
Inspiration
We watched non-technical founders spend weeks and thousands of dollars to get a basic landing page. They needed a designer, a developer, and a project manager. Most gave up before shipping anything. We asked: What if one AI model handled the entire process? Gemini 3 gave us the answer. One model family for validation, branding, code generation, and deployment. No handoffs. No waiting.
What it does
LaunchKit takes a startup idea in plain text and produces a live, deployed web application. The pipeline runs in sequence:
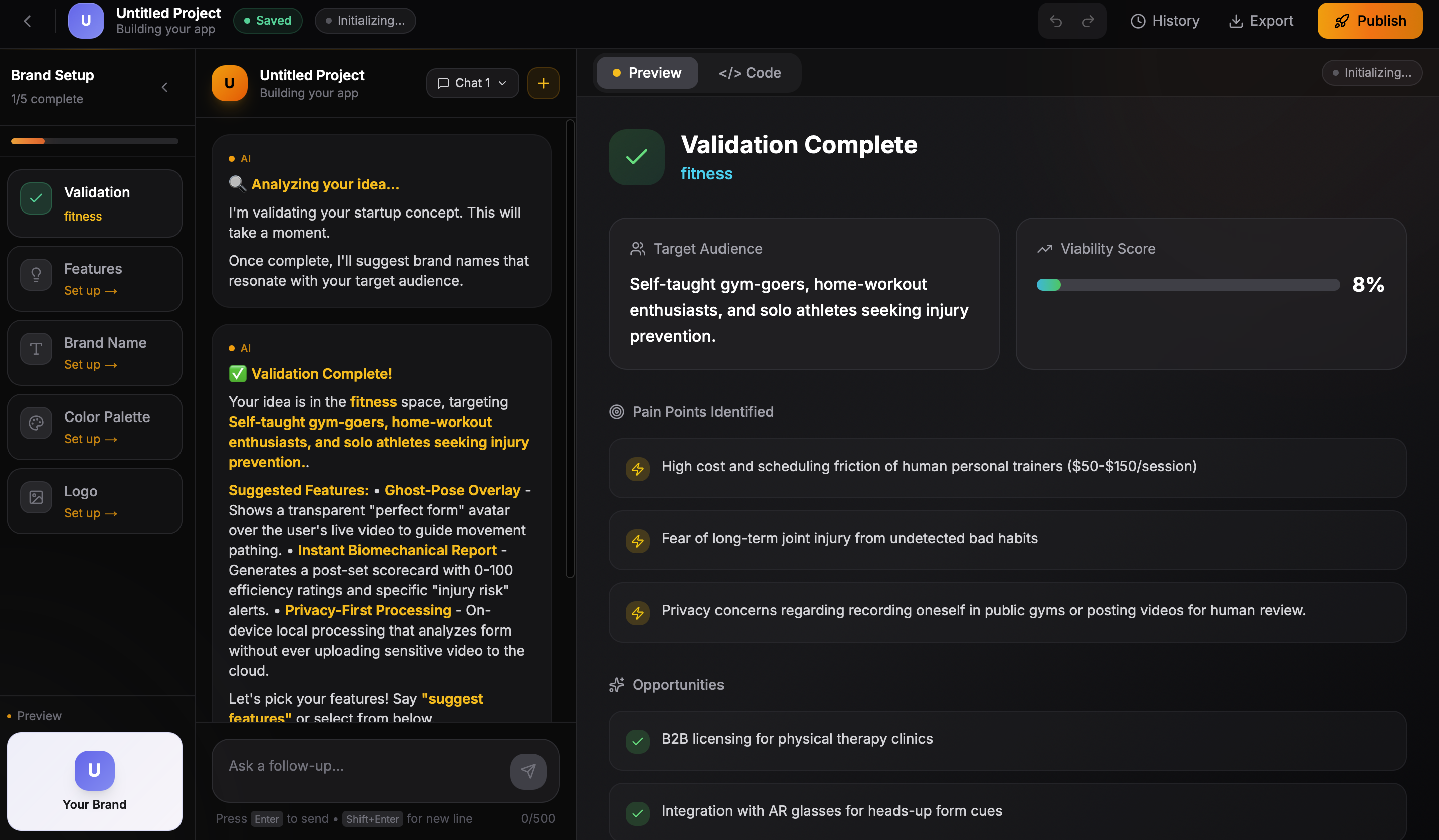
- Market validation with competitor analysis and viability scoring
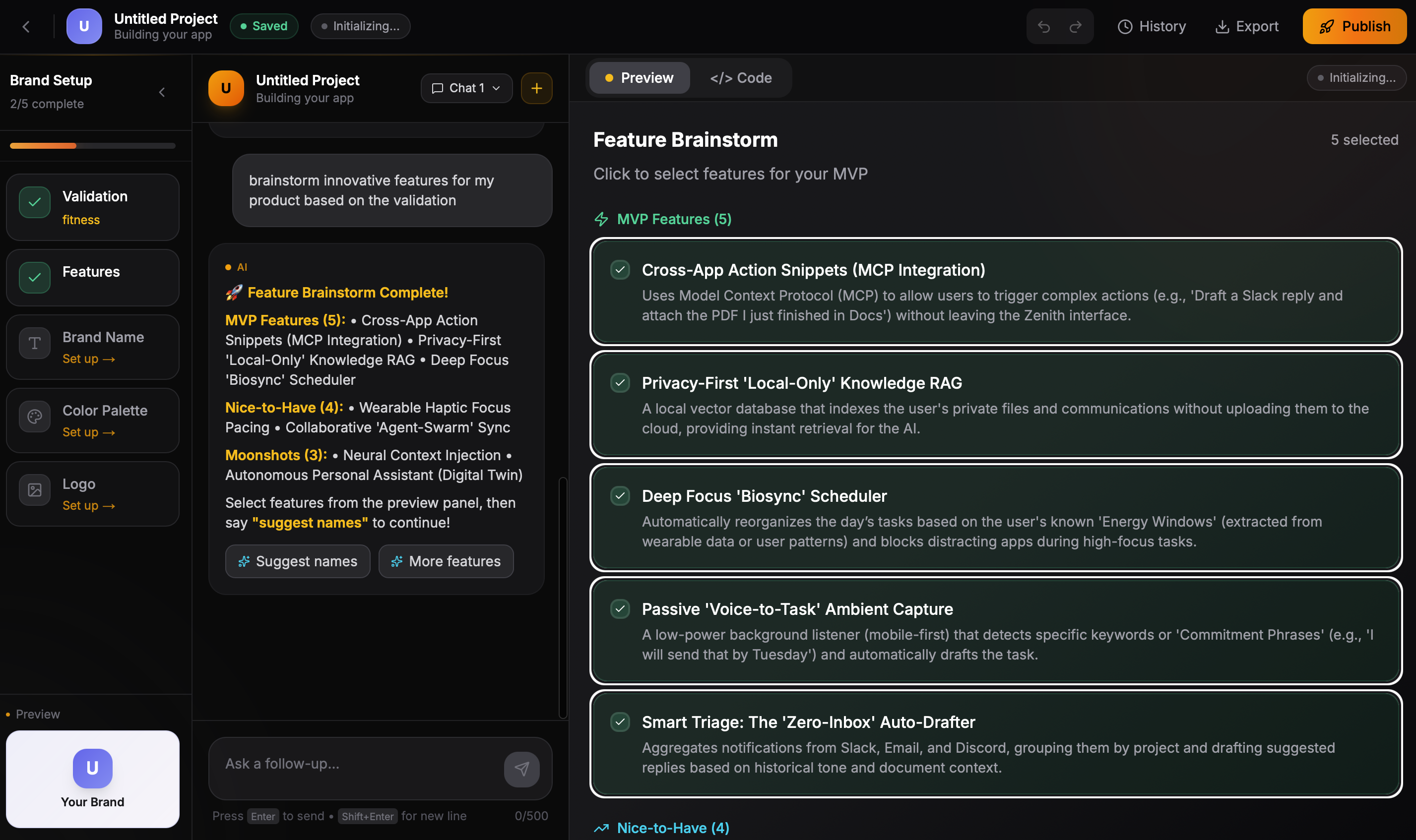
- Feature brainstorming with MVP prioritization
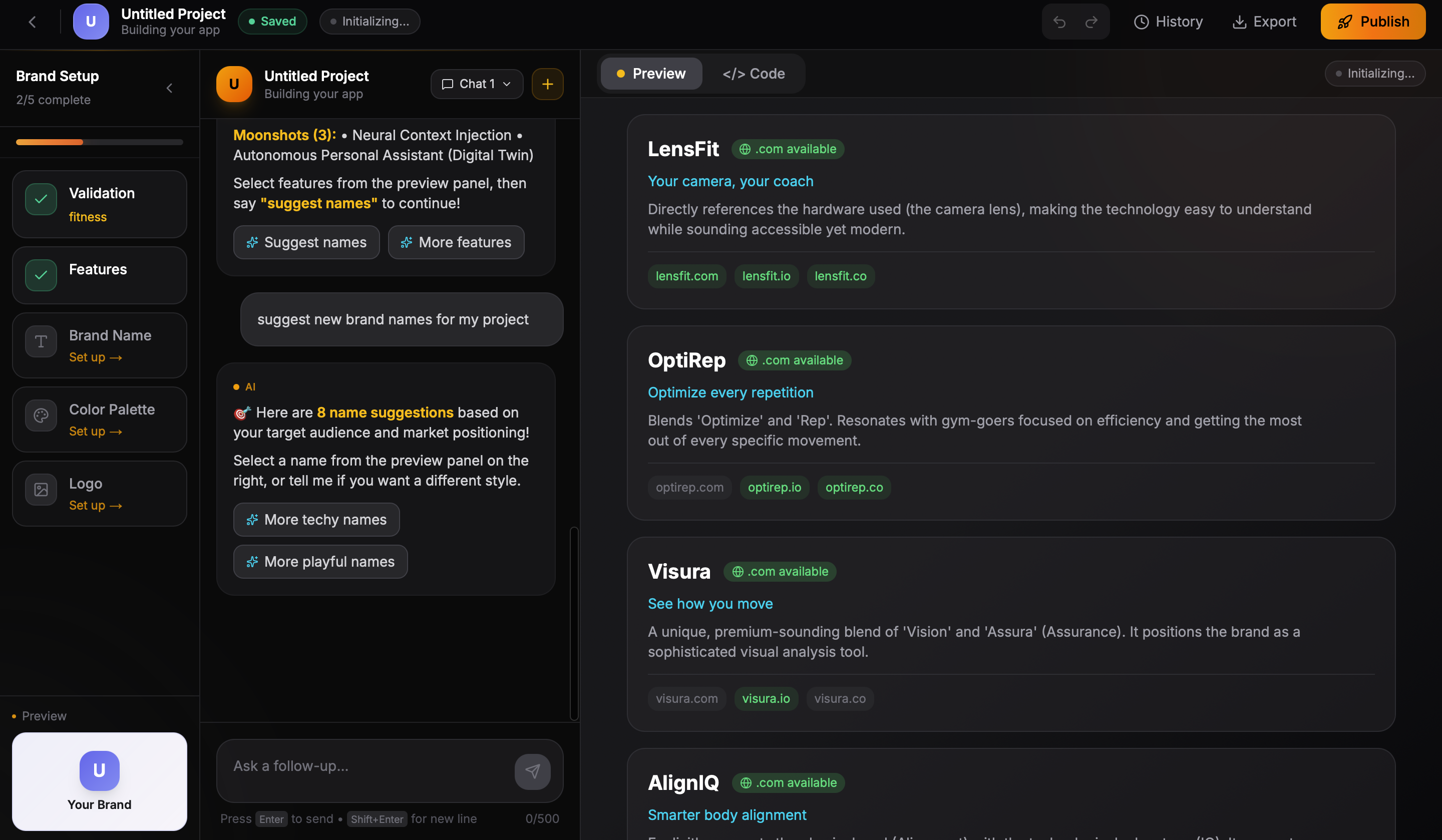
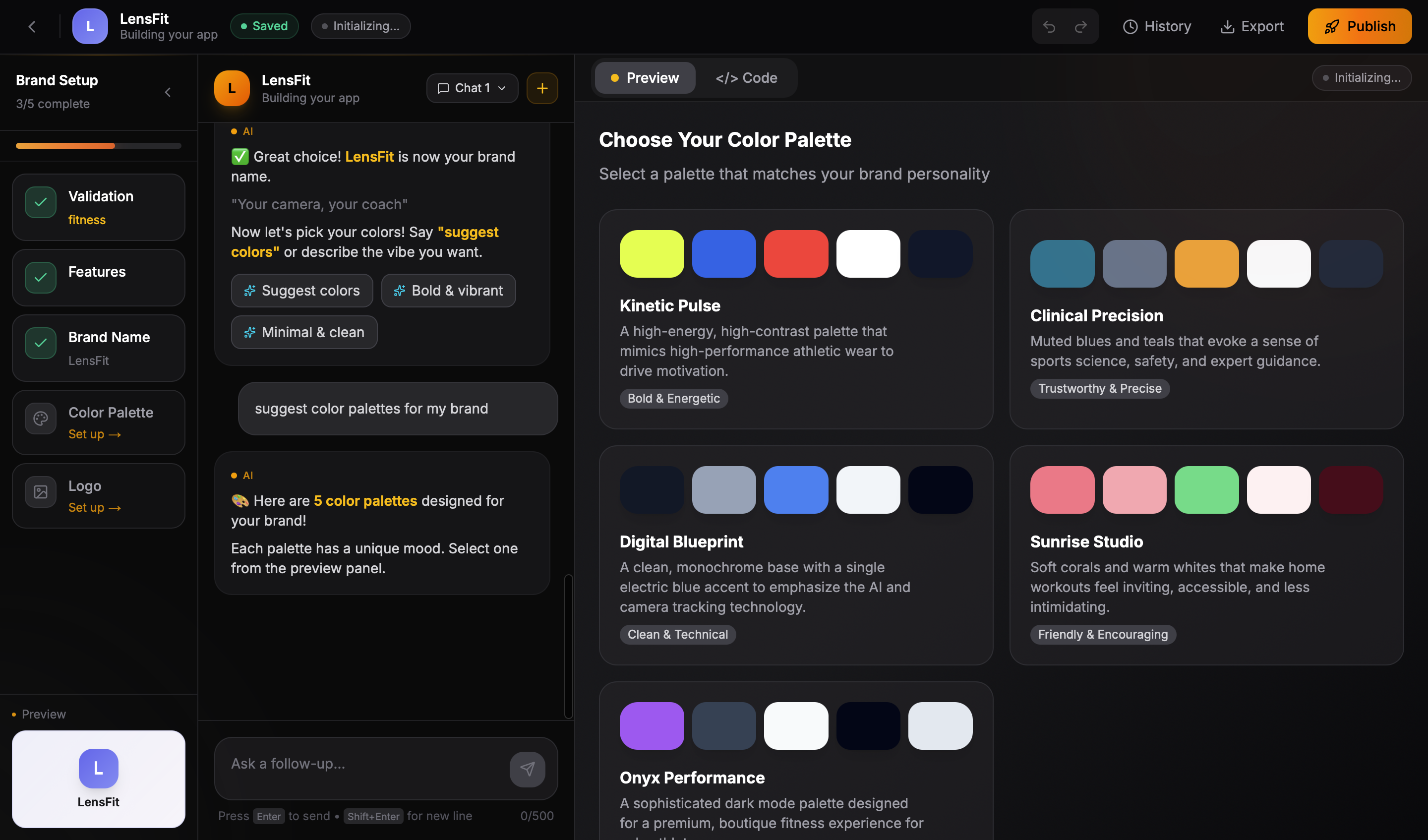
- Brand name generation with domain availability checks
- Color palette creation based on brand personality
- Logo design with AI-generated variations
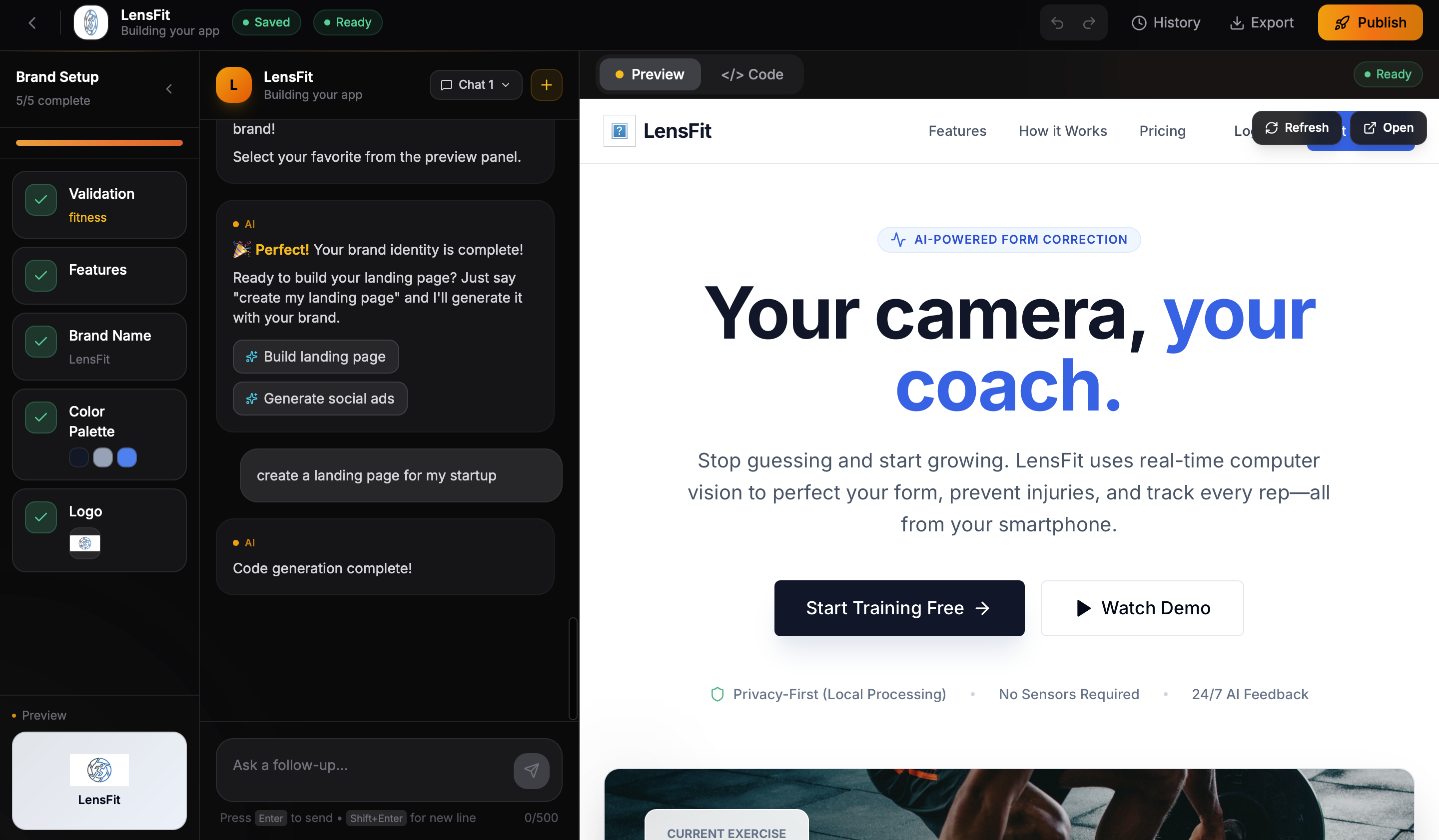
- Full website code generation (React + Tailwind)
- Live preview in a cloud sandbox
- One-click export to Vercel or GitHub
- Version history for every iteration
The entire process takes under five minutes.
How we built it
The frontend runs on Next.js with TypeScript. The backend orchestrates two Gemini 3 models: Gemini 3 Pro handles market validation, feature brainstorming, and full code generation through streaming function calls. Gemini 3 Flash handles brand naming, color palette generation, and logo design for speed-critical operations. Code runs in E2B cloud sandboxes. Users see their website render in real-time as the AI writes each file. We built two generation modes: Fast Mode (single-shot, one API call) and Agentic Mode (multi-step with tool use and self-repair). A repairer fallback catches broken code and fixes errors automatically. Firebase handles authentication and data persistence.
Challenges we ran into
- Gemini function calls sometimes returned malformed JSON. We built retry logic with structured error parsing to recover gracefully.
- Rate limiting (429 errors) during heavy generation sessions. We added exponential backoff and request queuing.
- Generated code would occasionally break on edge cases. We built a repairer pipeline: if Fast Mode fails, it falls back to Agentic Mode. If Agentic Mode fails, it re-prompts with the error context.
- File persistence bugs caused duplicate files (15 instead of 7). We traced it to fallback paths merging file sets and fixed it by passing an empty state on fallback.
Accomplishments that we're proud of
- End-to-end generation in under 5 minutes. From text input to a live deployed website.
- 12 AI-generated features from a single prompt.
- 4 custom logos generated in 30 seconds.
- Self-healing code generation. The dual-mode pipeline (Fast + Agentic) with automatic repair catches and fixes errors without user intervention.
- 100% Gemini 3 powered. No other LLM in the pipeline. Pro and Flash handle every task.
What we learned
Gemini 3's function calling works well for multi-step pipelines when you structure the tool definitions tightly. Streaming function calls let users see progress in real-time, which reduces perceived wait time significantly. Flash mode is fast enough for branding tasks that need sub-second responses. Pro mode handles complex code generation reliably when given structured context about the target framework.
Building fallback chains matters more than getting the first attempt right. Users tolerate a 3-second retry. They do not tolerate a broken output.
What's next for LaunchKit
- Multi-page app generation. Right now, LaunchKit produces single-page apps. Multi-page routing and navigation are next.
- Backend generation. Adding API routes, database schemas, and authentication flows.
- Template marketplace. Let users save and share generated apps as reusable templates.
- Mobile app generation. Extending code generation to React Native.
- Team collaboration. Real-time co-editing of generated projects with shared version history.
Built With
- firebase
- gemini
- gemini3flash
- gemini3pro
- googleaisdk
- nextjs
- tailwind
- typescript


Log in or sign up for Devpost to join the conversation.