

Inspiration
The research on why early-stage startups fail is remarkably consistent: it's not the idea, it's the untested assumptions underneath it. Founders build for 6 months before discovering their assumptions about their target customer was wrong the whole time. And the tragedy is that most of those assumptions could have been surfaced in Week 1, if only someone had just asked the right questions.
As college students trying to turn ideas into something real, we kept running into the same wall: a lack of honest feedback. Our friends and family were supportive. The AI tools we tried were even more supportive. Everyone agreed with us. No one challenged us.
That's why we built Launchify. We want to give aspiring founders what we didn't have access to: a room full of experienced, honest advisors who will actually challenge our thinking, help us identify blindspots, and ask the uncomfortable questions.
Decision Impact: Launchify won't validate you just because you want to be validated. We built AI that truly helps you think, not AI that helps you feel good about thinking.
What it does
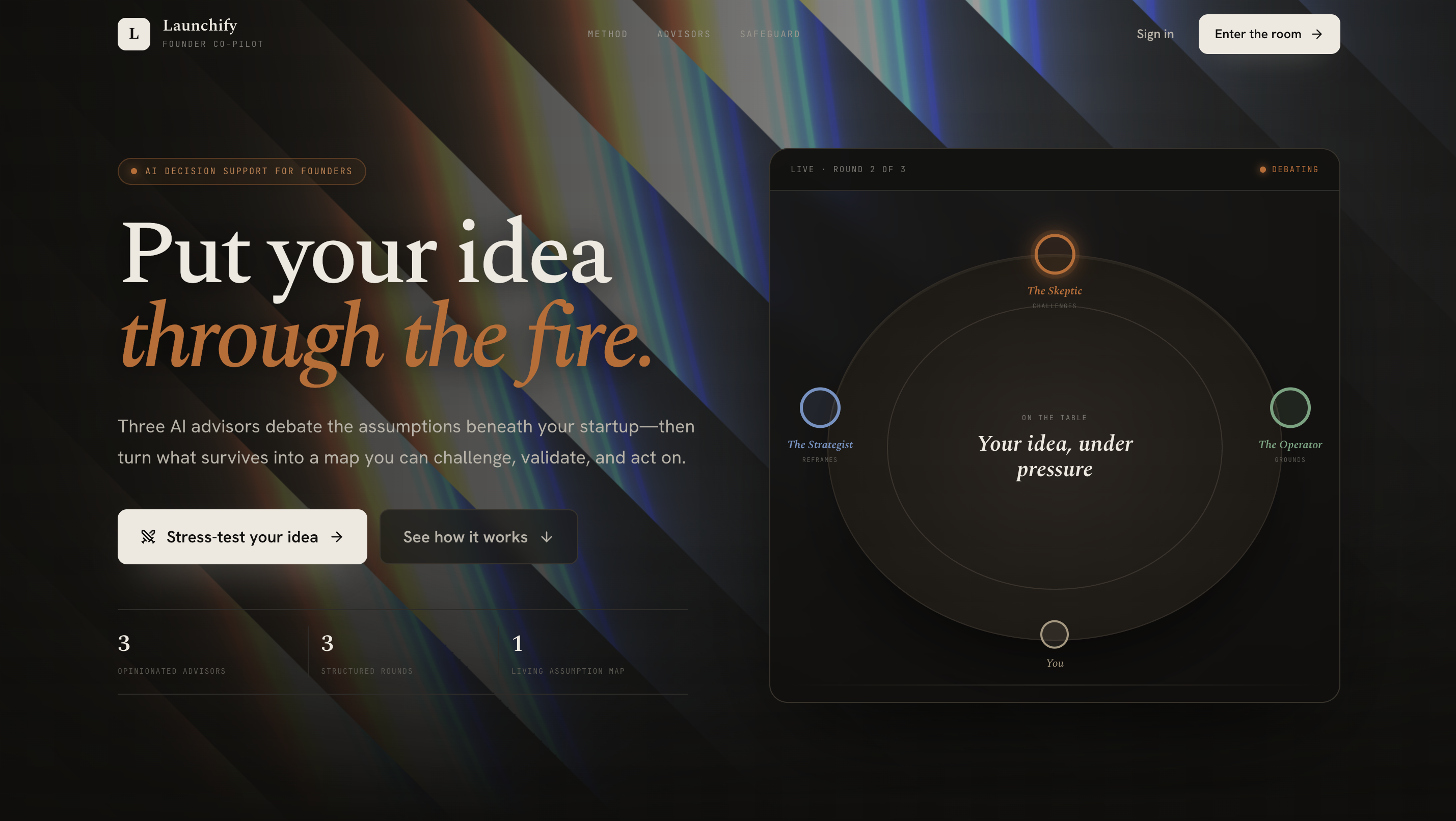
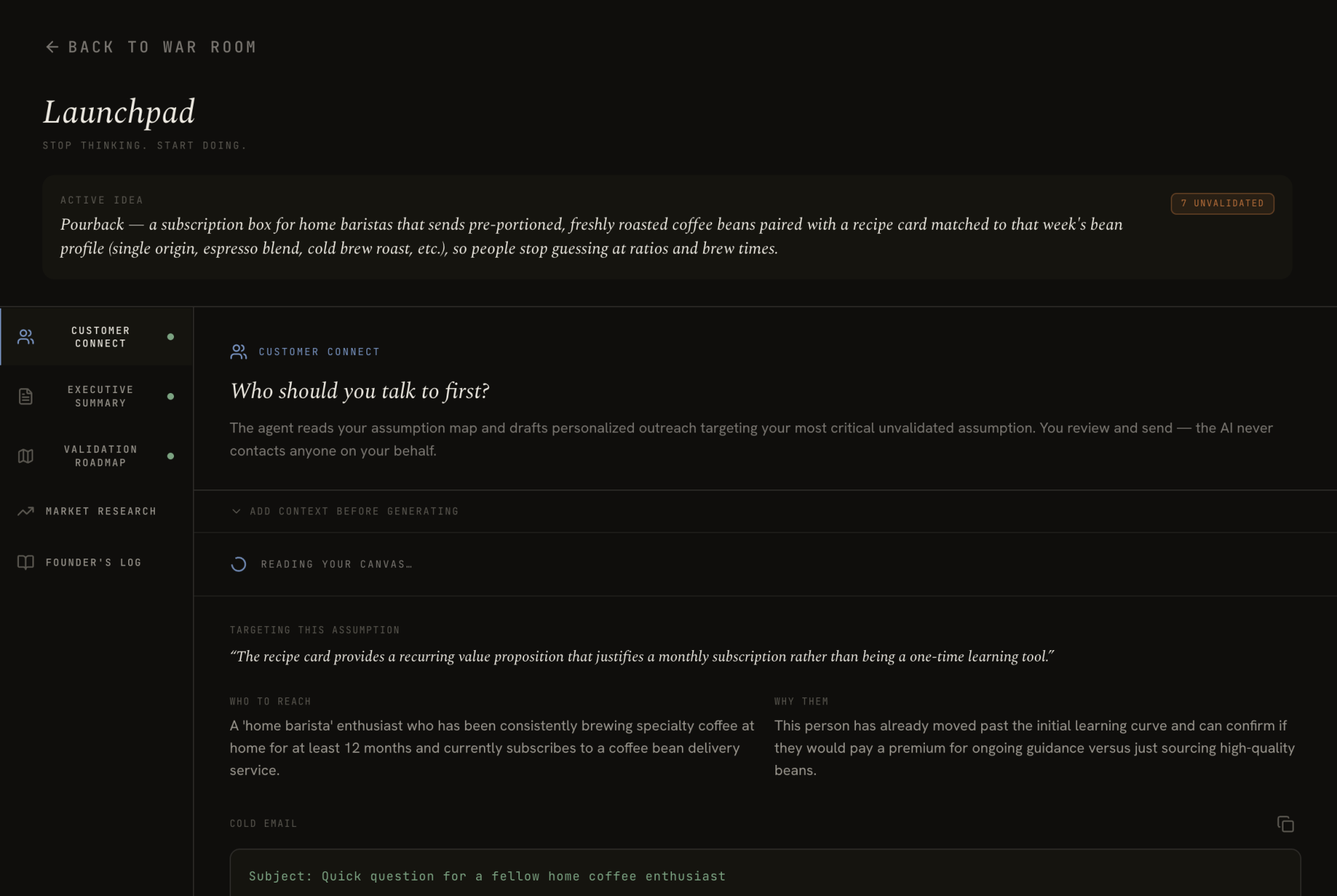
Launchify is an AI-powered startup co-pilot that helps early-stage founders pressure-test their idea. You start by describing your idea and answering 8 questions: who specifically has this problem, how they solve it today, what evidence you have, and what you think could kill it. Then you enter the War Room.
Three specialized AI agents debate your idea across three rounds. The Skeptic challenges every unproven claim with Socratic precision. The Strategist interrogates your market, your competition, and your timing. The Operator stress-tests what it actually takes to build this: timelines, dependencies, cold-start problems, hiring realities. Critically, they respond to each other, and they keep debating until they've converged on the single most critical thing you should test.
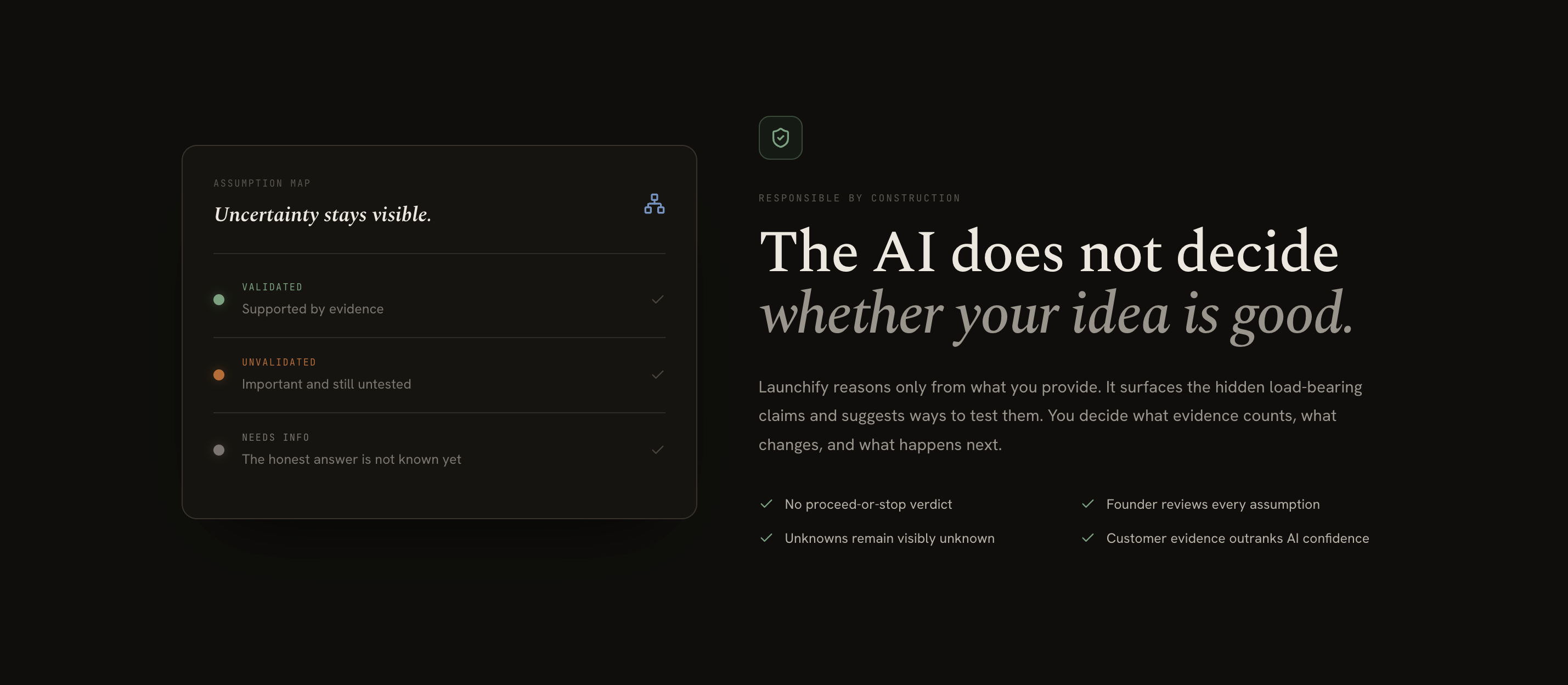
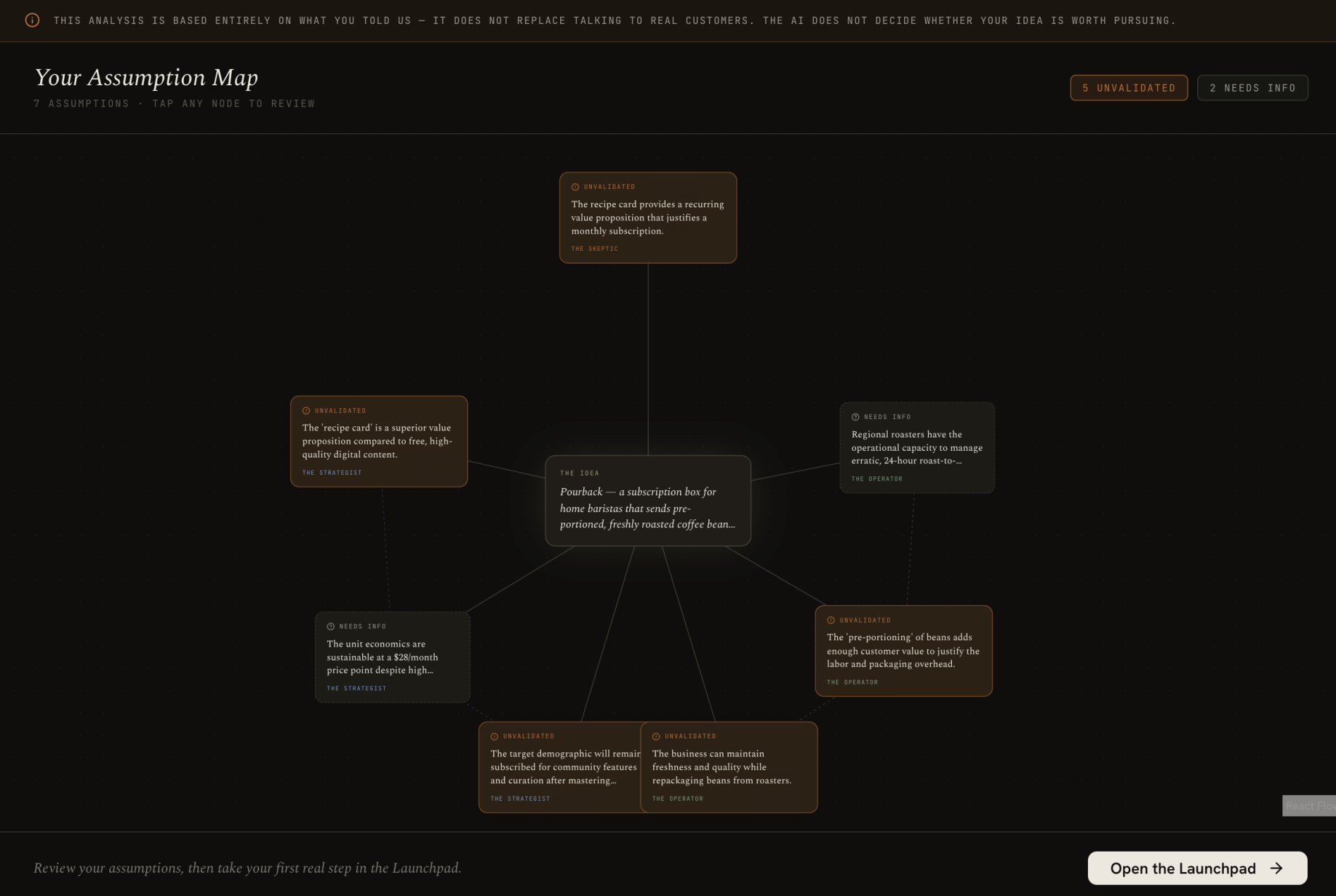
After surviving the War Room, Launchify synthesizes all the findings into an Assumption Map, an interactive visual canvas showing what's proven versus what's still unknown. It's designed uncertainty-first: unvalidated assumptions appear larger and higher-contrast than validated ones. You then remediate each node: validate it with your own evidence, modify the claim, or remove it. AI never resolves an assumption on its own. The map updates because you acted and got actual feedback from the market. That's what being a founder means.
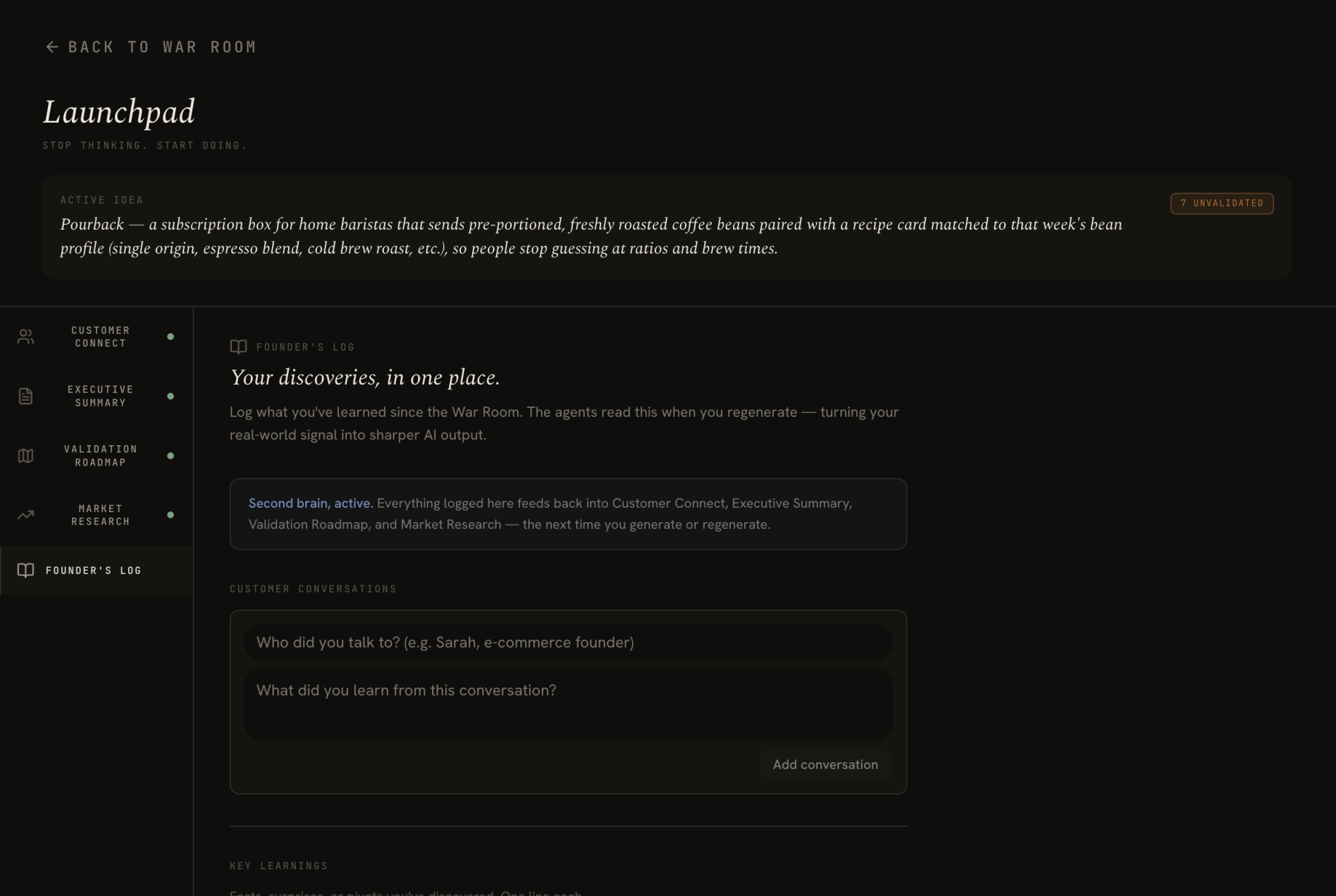
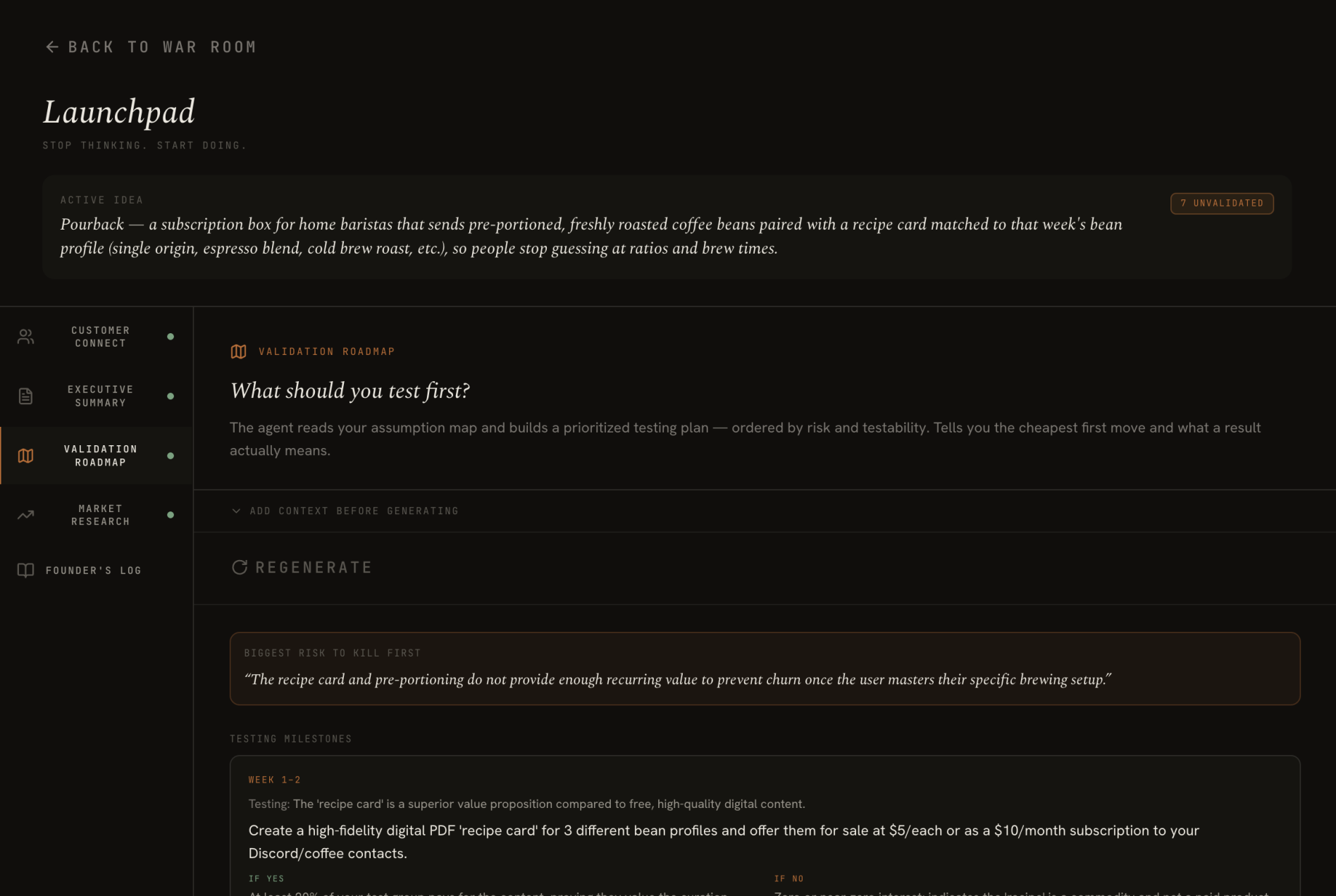
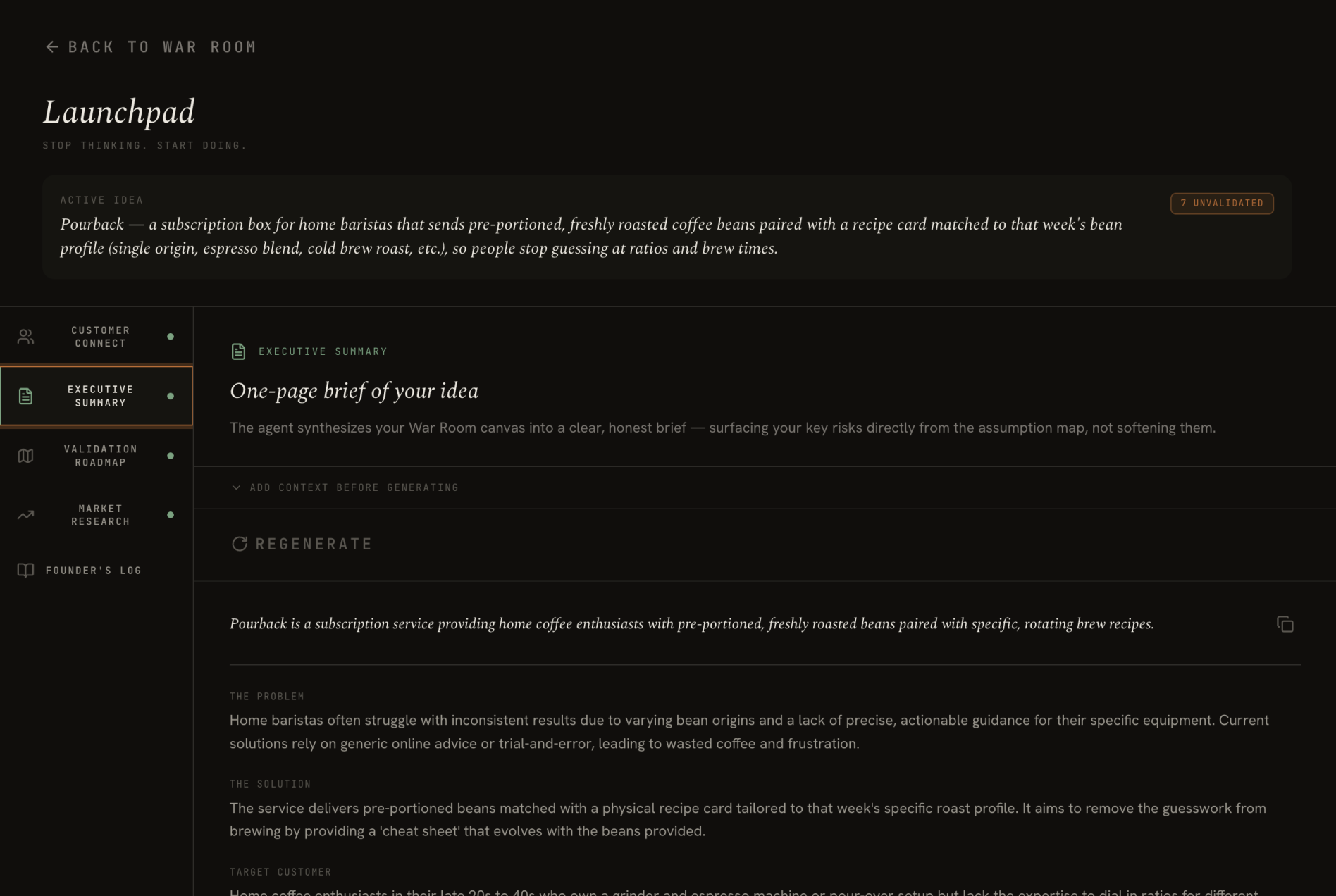
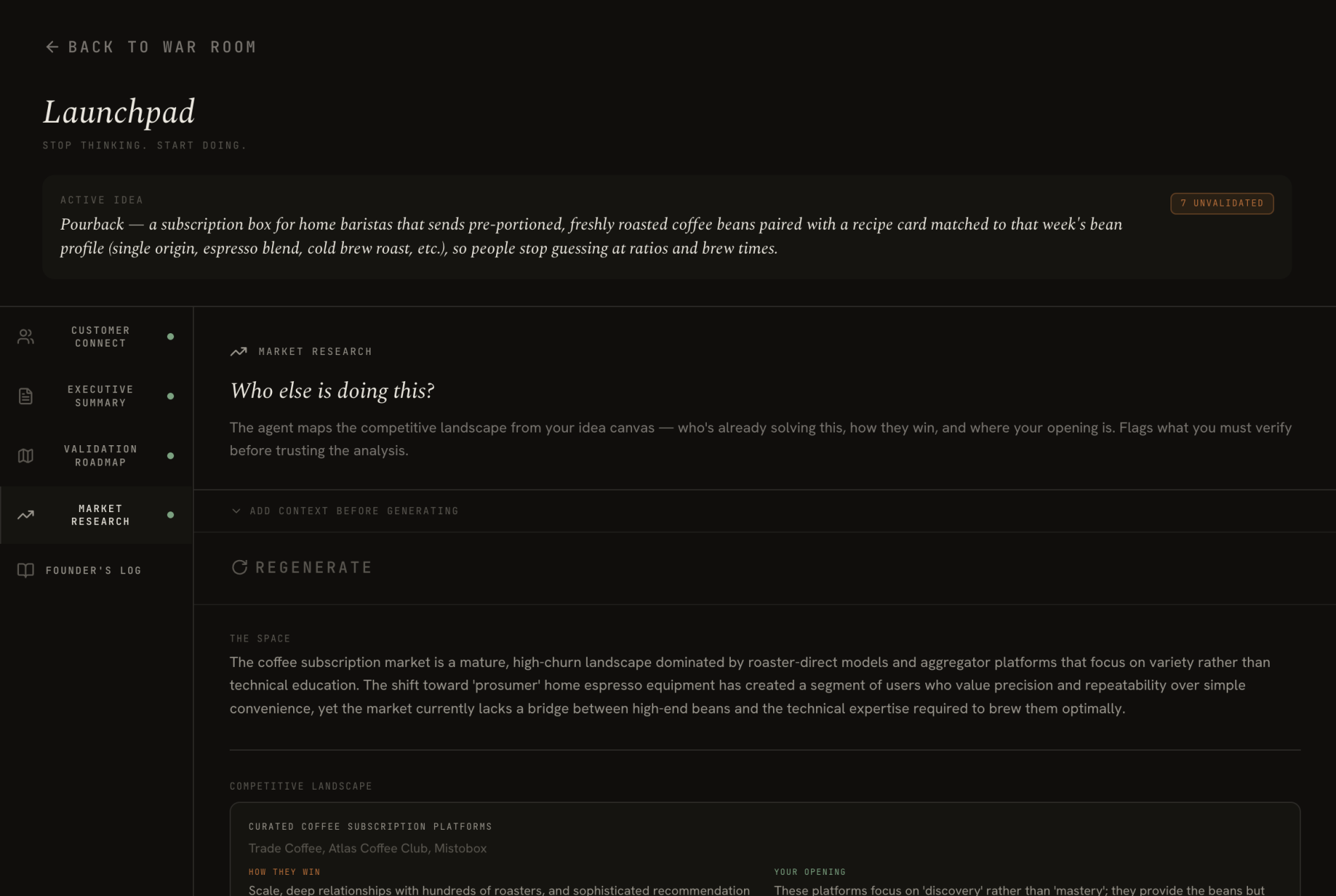
Your updated map feeds the Launchpad: an all-in-one founder hub to take your startup from idea to action. You get: personalized outreach targeting your first customers, an executive summary you can share with advisors and investors, prioritized validation roadmap to test your assumptions, and a complete map of your competitive landscape. Everything is carefully calibrated to your specific idea, not generic responses.
Decision Impact: The goal is for you to get clarity on exactly what you don't know yet, and concrete steps to find out.
Who it's for: College students and recent grads with an early-stage startup idea who need rigorous thinking, not more information. If you've ever had an idea you wanted to stress-test before spending 6 months building the wrong thing, Launchify was built for you.
How we built it
Launchify is the brainchild of a team of 3 students: a founder, a game developer, and a CS major. We combined our diverse expertise — product intuition, creative systems thinking, and engineering depth — to build an experience for founders, not just another tool.
The technical foundation is a Next.js 16 frontend with an Express 5 backend, connected to a PostgreSQL database via Prisma. Authentication runs through Auth0. All LLM calls go through a provider layer that uses Google Gemini 2.5 Flash as primary and Groq Qwen3-32B as fallback so the app stays functional even if one provider is unavailable.
The War Room runs 9 sequential LLM calls (3 agents × 3 rounds) plus a final synthesis pass, each one receiving the full transcript-so-far as context. Getting that state machine right, handling retries, persisting progress after each round so nothing is lost on reload, and passing the right context window into each call took more careful thinking than we expected.
The Assumption Map is built on React Flow, with a custom layout algorithm that positions nodes by confidence status: unvalidated assumptions cluster to the left and are physically larger, validated ones are smaller and muted on the right. We used Framer Motion for the sequential debate reveal: each agent's message appears with deliberate pacing, because watching the debate unfold is part of the experience.
The Pitch Coach is powered on Gemini multimodal API so the founder can stream their video, share screen, and talk to our AI coach and receive real feedback live. Every session analyzes a founder's actual pitch for pacing, clarity, and investor objection anticipation and provides actionable tips for them to practice and improve on.
The visual design was intentional at every level. We wanted a "situation room" feeling: dark, warm, editorial.The arena layout positions the three agents spatially around a central debate floor. The color system uses warm near-blacks and carefully chosen accent colors rather than the flat RGB red/green/blue you see in most AI tools.
We used Claude Code for AI-assisted development and disclosed it in our tools list. Every design and architectural decision was ours.
Challenges we ran into
A hard bug we hit: Prisma's database adapter reads the connection string at module initialization time before dotenv had loaded the environment variables. The ORM was being instantiated with undefined as the database URL, which meant every database write silently failed. We spent hours ruling out authentication issues, schema mismatches, and driver version conflicts before tracing it to import order. The fix was three lines. The diagnosis was a full evening.
The design challenge: Making uncertainty feel honest without feeling discouraging. An Assumption Map where most of your nodes are red can feel like the AI is telling you your idea is bad. It's not. It's telling you what you haven't tested yet. We went through several visual iterations before landing on our uncertainty-first hierarchy and design visuals.
The orchestration challenge: Multi-agent systems are easy to describe and hard to build correctly. Getting three agents to genuinely respond to each other required careful prompt engineering around what each agent receives at each round, and how the transcript-so-far is formatted. Early versions produced agents that talked past each other. Later versions produced agents that agreed too quickly. The goal was productive disagreement, and getting there took lots of iteration.
Accomplishments that we're proud of
We're proud that the agents actually disagree with each other. It would have been easy to build three agents that each give a polished, coherent response to the founder's idea. What makes the War Room actually valuable is getting the productive disagreement right: like the Strategist genuinely pushing back on the Skeptic's framing or the Operator redirecting the debate toward execution when the other two are too focused on market theory. You can feel the dynamic when you watch it all happen before your eyes in the War Room.
We're sldo proud that the human-in-the-loop is architecturally enforced, not just mentioned. The AI cannot resolve a node or do our validation for us. That's on the founder, and that's what being a founder means. Going out into the market, talking to customers, and overcoming rejection.
What we learned
We learned that responsible AI is as much of a design problem as it is a compliance problem. The temptation is to add a disclaimer and move on. What we discovered is that the safeguard that actually protects users is the visual design of the Assumption Map itself. The safeguard has to live at the moment of decision, not in the fine print.
We also learned how much the framing of AI output matters. The same information presented as "here are your risks" versus "here is what you don't know yet" produces completely different emotional responses. The first feels like failure. The second feels like clarity. We rewrote our copy more times than our code.
And we learned what it means to build something under real constraints. Every feature we cut made the product better. The War Room, the Assumption Map, and the Launchpad are what's left after removing everything that wasn't essential to the core insight: founders need honest challenge, not more information.
What's next for Launchify
Inside Launchify, we also have a built-in Pitch Coach that we aim to develop further in the future. As a founder, one of the most important skills you can have is pitching. We help founders build the iron confidence to pitch in a scary room full of VCs. Critically, it will cross-reference the pitch against the founder's Assumption Map: if you're claiming market validation in your pitch but that assumption is still UNVALIDATED on your map, Pitch Coach flags the contradiction in real time. We are also working on Collaborative War Rooms since founders rarely work alone. A multi-founder mode where the Assumption Map is shared and both founders can remediate nodes, leave comments, and track who validated what would make Launchify genuinely useful for teams.
Built With
- amazon-web-services
- auth0
- claude
- express.js
- gemini
- github
- grok
- neon
- nextjs
- postgresql
- typescript


Log in or sign up for Devpost to join the conversation.