Inspiration
Every engineering team has shipped a release they shouldn't have. A missing approval, an unpatched CVE, a rollback plan that was "TODO" — and the post-incident review always asks the same question: how did this get past everyone?
The answer is usually: nobody had the full picture at the moment the merge button was clicked.
GitLab already surfaces the signals — pipelines, vulnerability reports, approvals, linked issues, audit logs. The problem isn't visibility. It's synthesis. A human reviewer has to mentally cross-reference six different screens, remember which policy applies to which environment, and make a judgment call under deployment pressure. That's exactly the kind of structured reasoning that a coordinated AI agent chain can perform in seconds — if you wire it correctly.
We built Launch Control because release decisions shouldn't depend on who remembers the checklist.
What it does
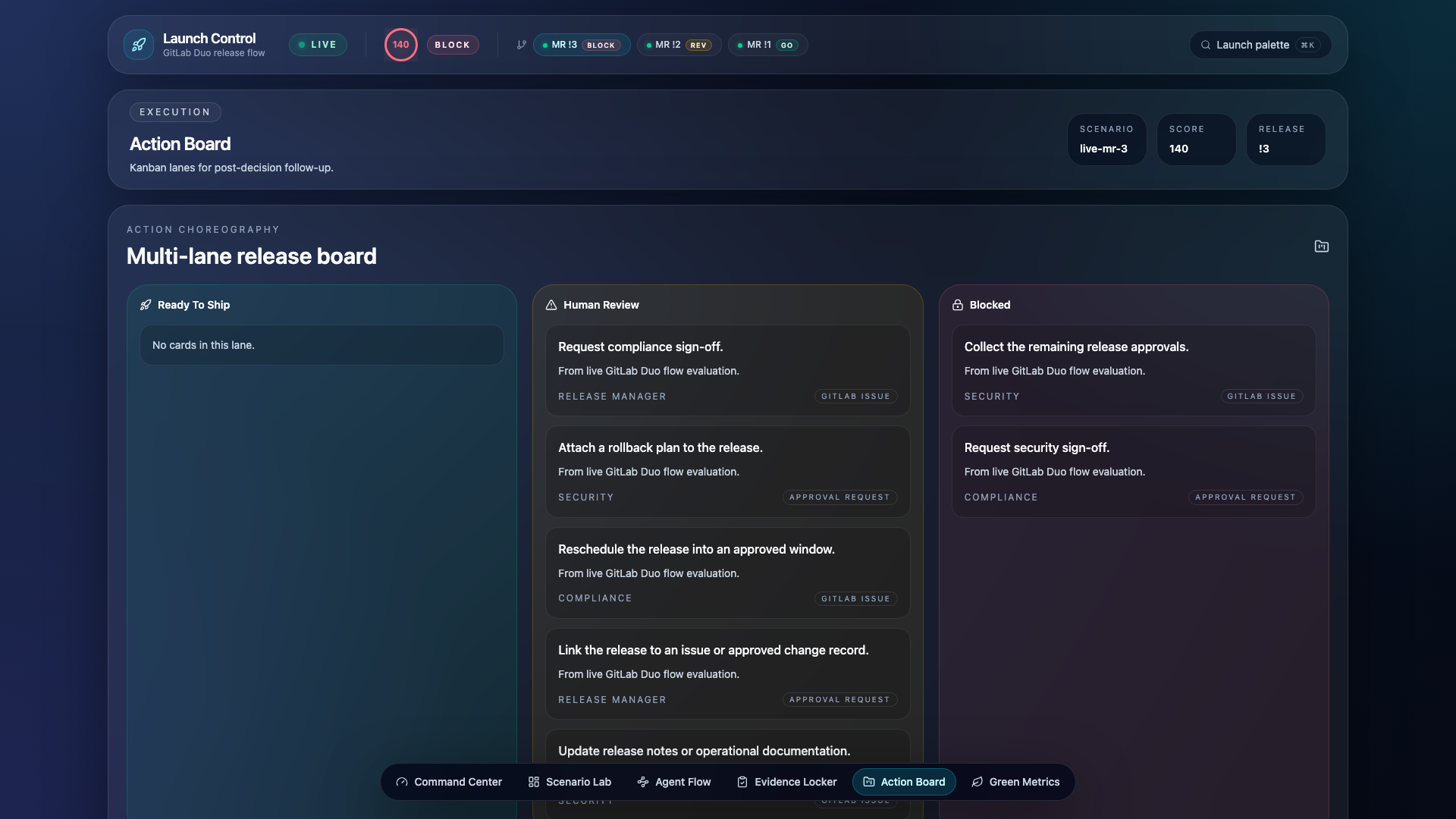
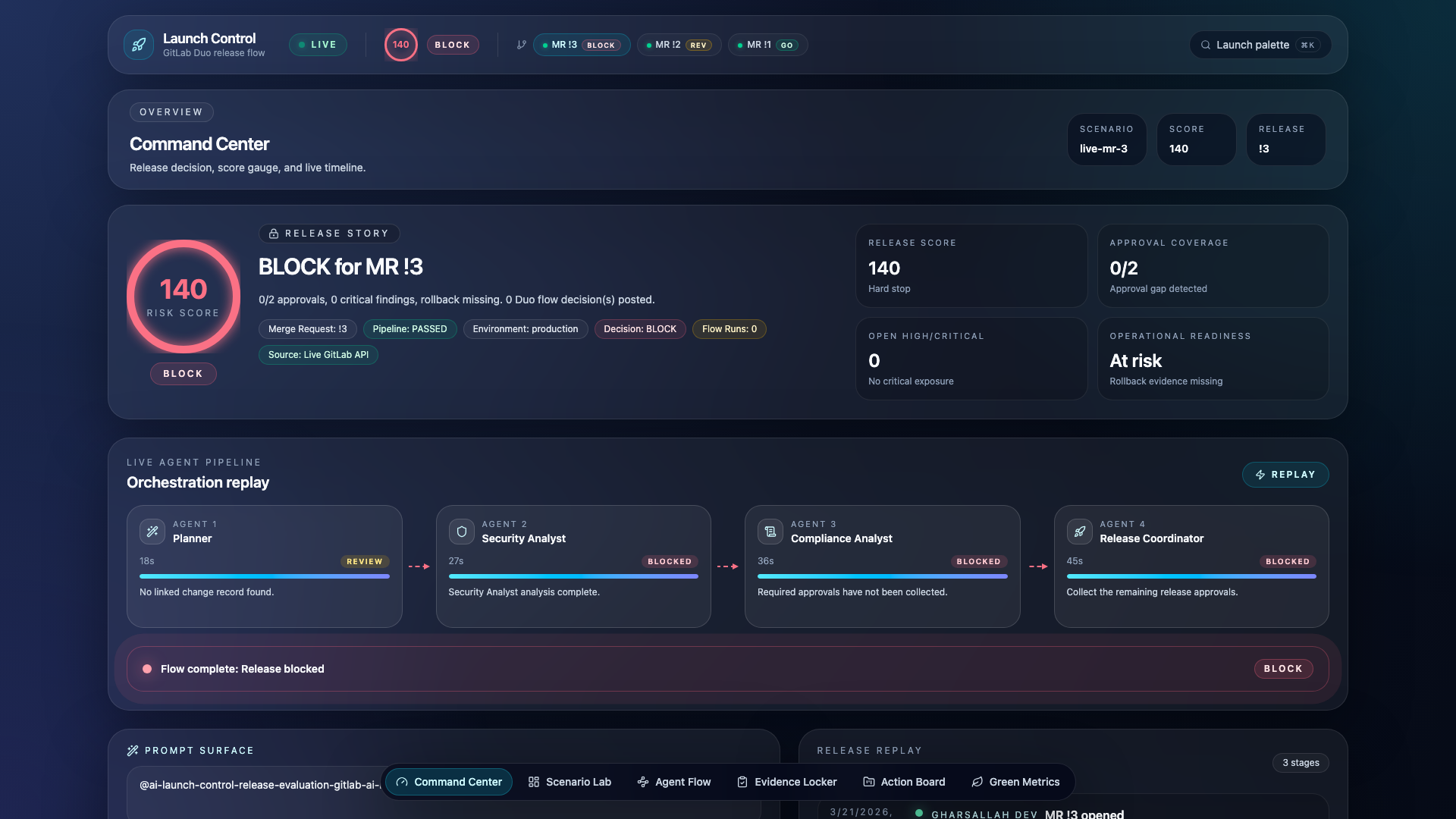
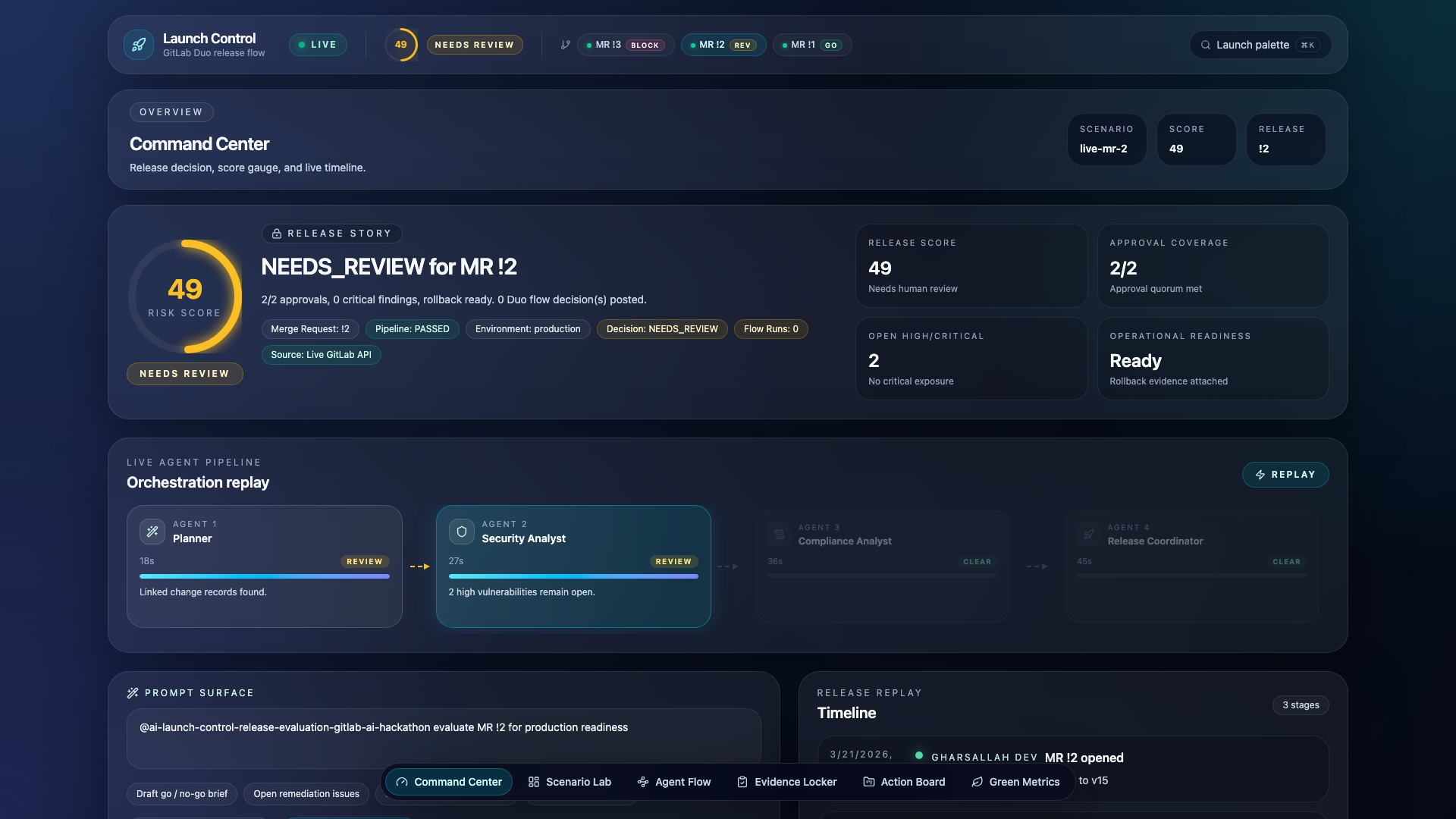
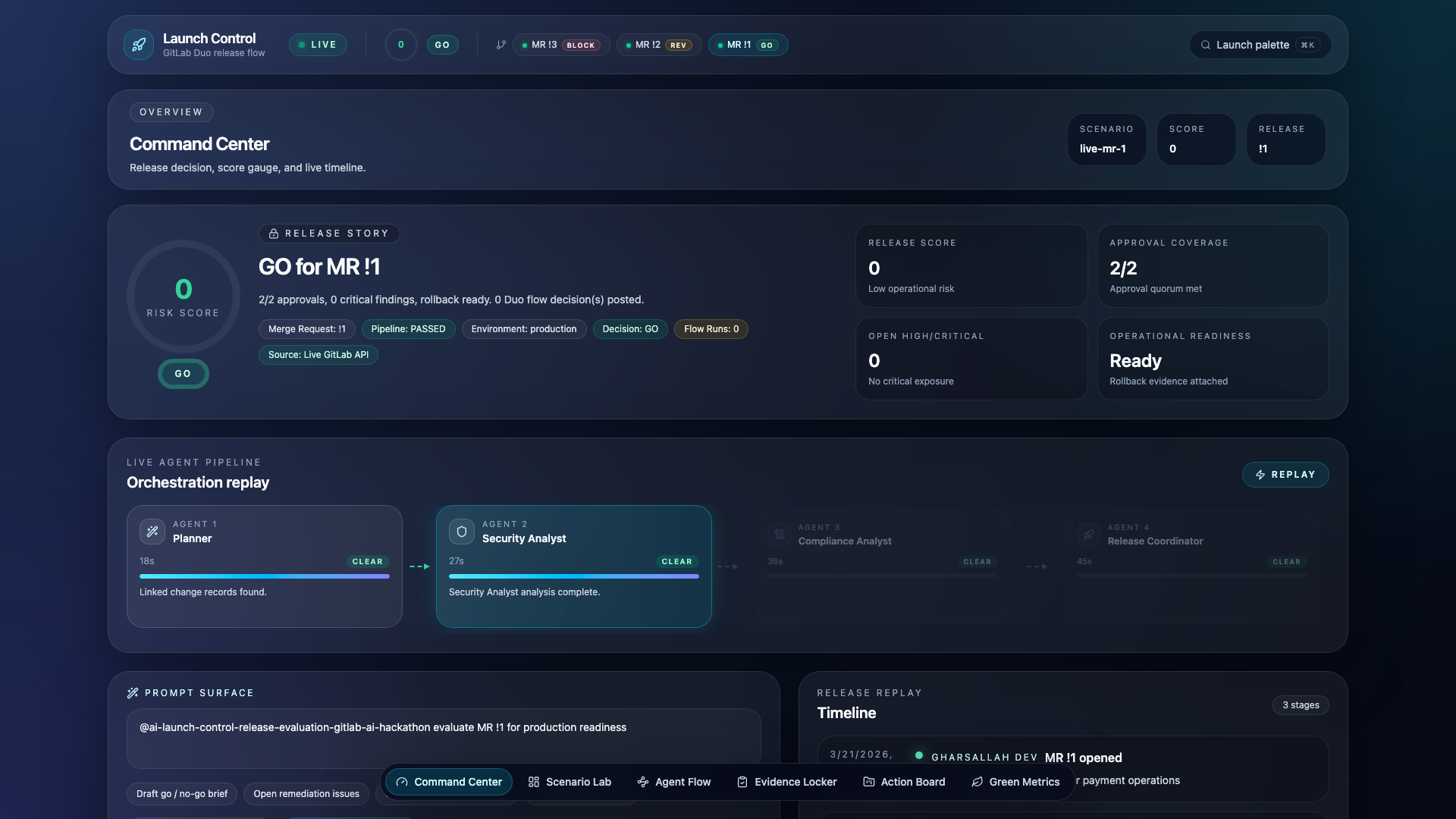
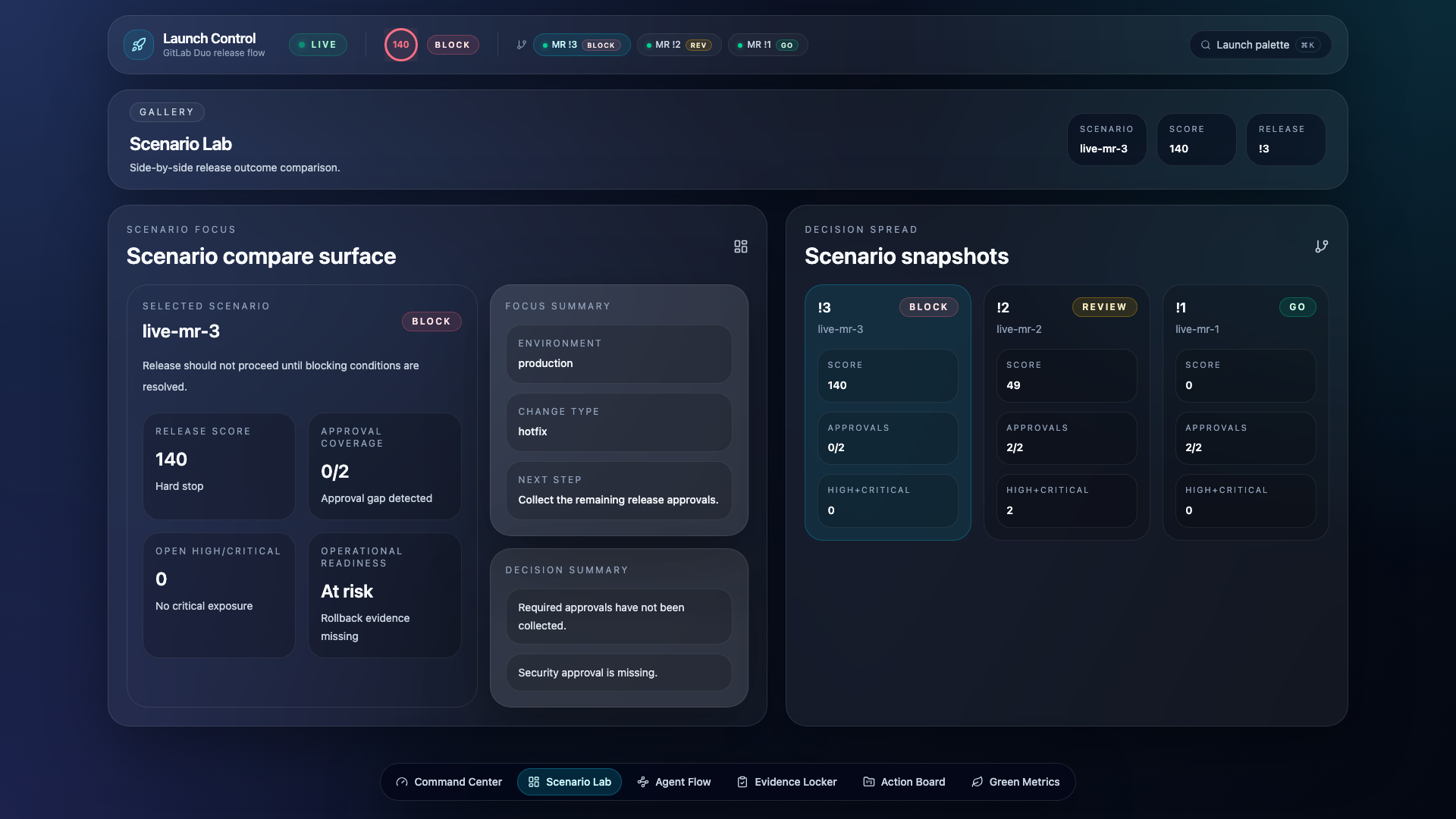
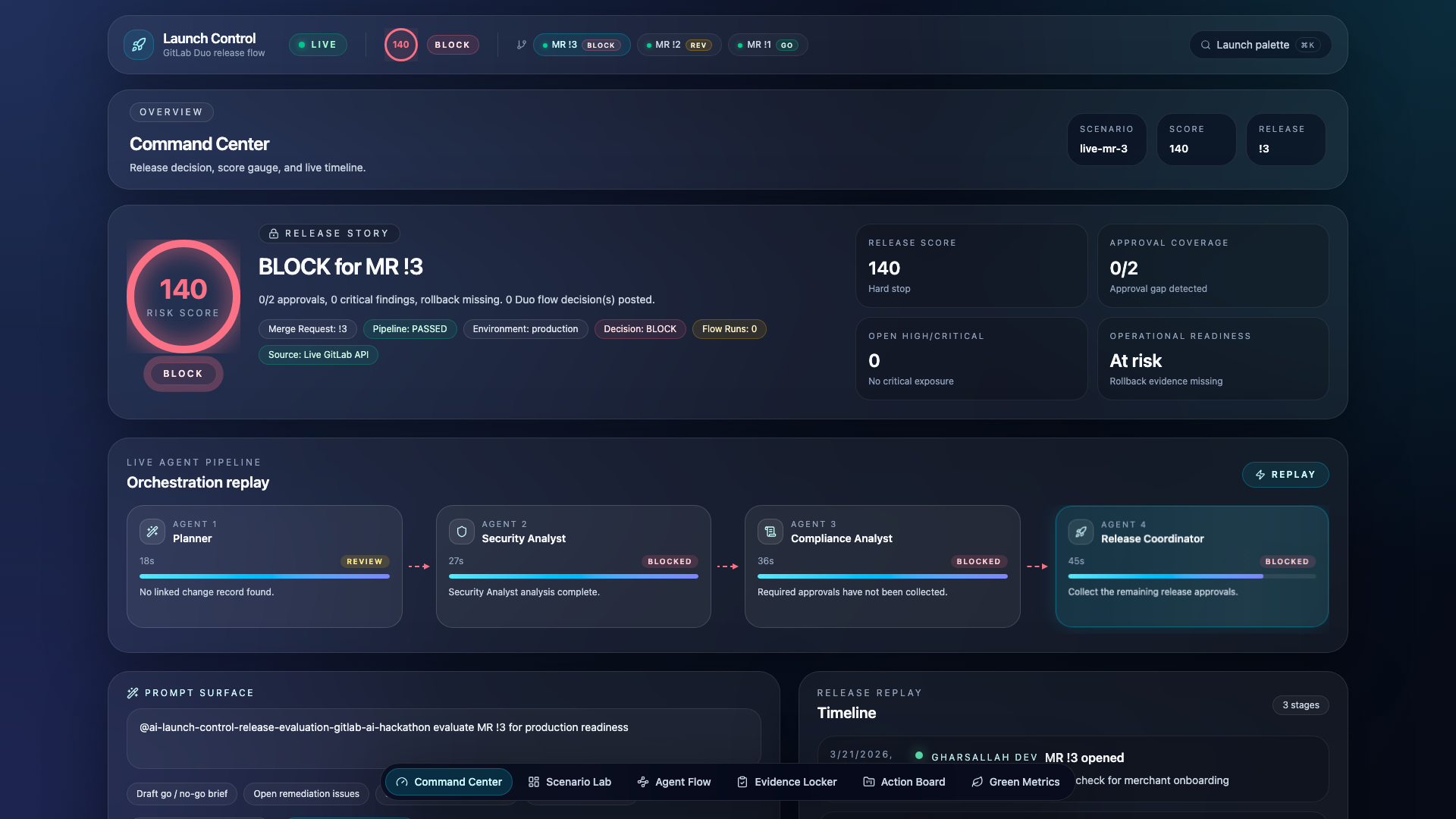
Launch Control is a custom GitLab Duo flow that chains four specialized AI agents to evaluate merge requests against policy-as-code and produce a structured GO / NEEDS_REVIEW / BLOCK decision — posted directly as an MR note with full evidence, blockers, and automatic remediation.

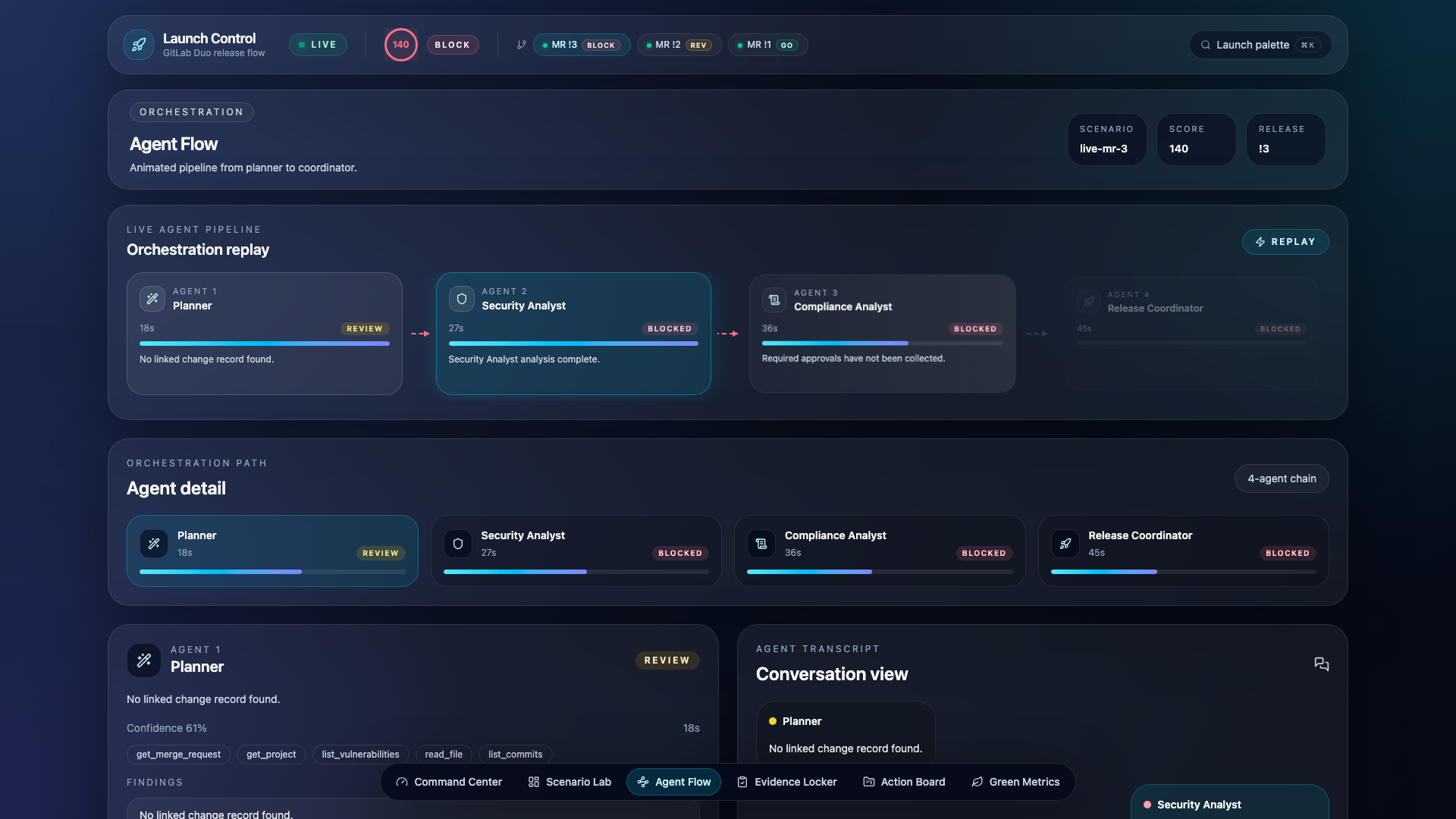
The Four-Agent Flow
The flow is defined in .gitlab/duo/flows/release-evaluation.yaml and runs on GitLab compute. Each agent is scoped to exactly 5 tools:
| Agent | Role | Key Tools |
|---|---|---|
| Planner | Gathers release context: MR summary, changed files, pipeline status, vulnerabilities, approvals, linked work items | get_merge_request, list_vulnerabilities, read_file, list_commits, get_project |
| Security Analyst | Evaluates critical/high CVEs, sensitive file changes, dependency risk, secret exposure, pipeline confidence | list_vulnerabilities, get_vulnerability_details, list_security_findings, get_merge_request, read_file |
| Compliance Analyst | Checks approval quorum, security/compliance sign-off, rollback evidence, linked change records, documentation | get_merge_request, list_issues, read_file, list_commits, list_project_audit_events |
| Release Coordinator | Combines all upstream findings into a final decision. Posts the structured verdict and opens remediation issues | create_merge_request_note, create_issue, get_merge_request, read_file, list_issues |
The flow routes sequentially: Planner → Security Analyst → Compliance Analyst → Release Coordinator → end. Every agent grounds its reasoning in three policy files checked into the repository — no hardcoded thresholds, no magic numbers.
Risk Scoring
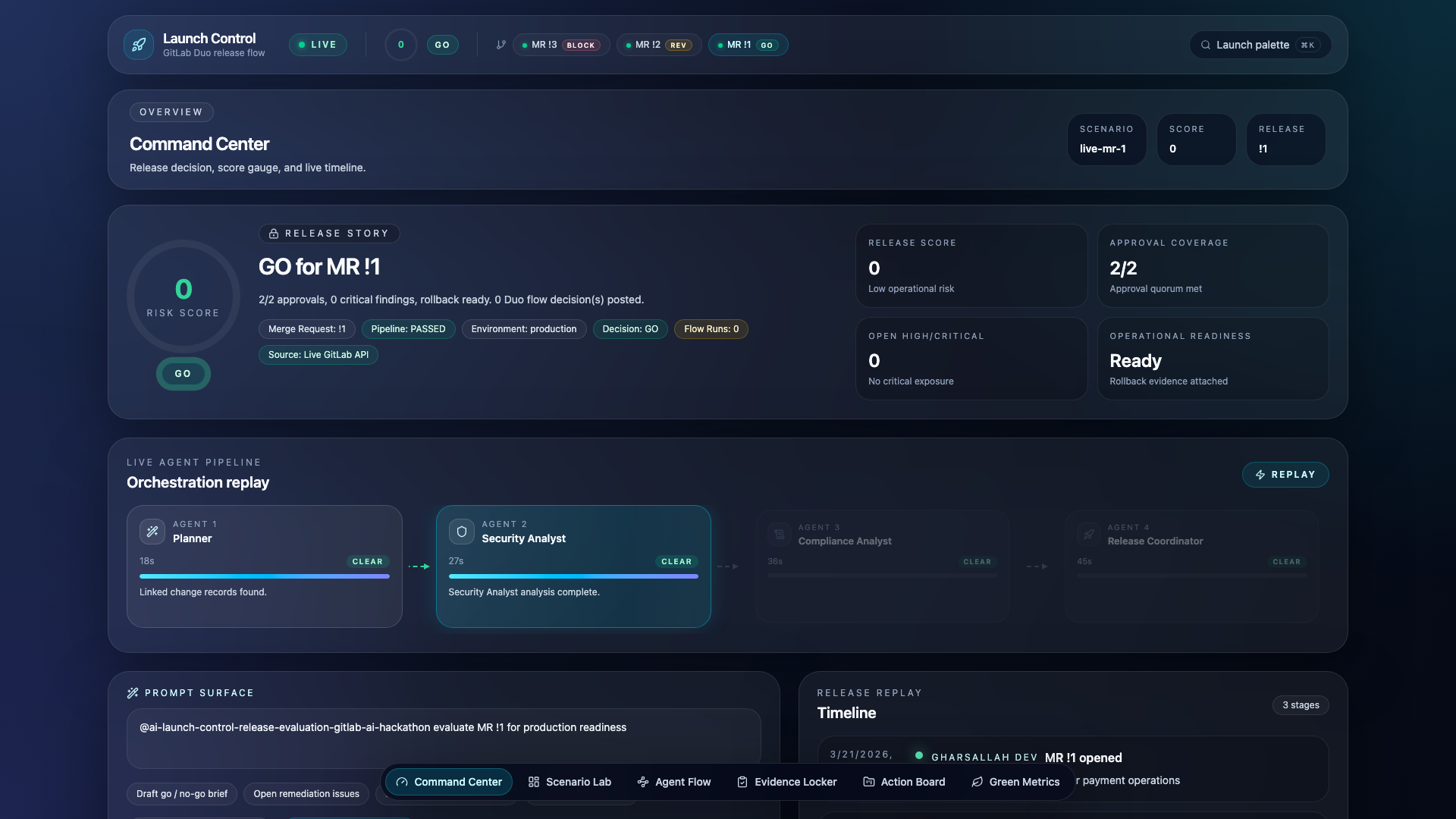
The evaluation engine computes a weighted risk score from 11 signals. Hard blockers (failed pipeline, critical CVE in production, missing required approvals) trigger an instant BLOCK regardless of score.

Policy-as-Code
All thresholds, weights, and requirements live in three YAML files:
# risk-matrix.yaml — every number is tunable without code changes
weights:
criticalVulnerability: 50
highVulnerability: 15
missingSecurityApproval: 25
missingApproval: 20
noRollbackPlan: 30
thresholds:
goMax: 24 # score <= 24 = GO
reviewMax: 59 # score 25-59 = NEEDS_REVIEW
# score >= 60 = BLOCK
Teams change release policy by editing YAML. No code changes. No redeployment. No re-prompting agents.
Command Center Dashboard
A companion real-time evaluation UI deployed at https://launch-control-six.vercel.app that pulls live data from the GitLab API. Connect any GitLab project to see:
- Command Center — Risk score gauge, agent pipeline replay, release timeline
- Scenario Lab — Compare evaluations across multiple open MRs side by side
- Agent Flow — Visualize each agent's verdict, confidence, duration, and findings
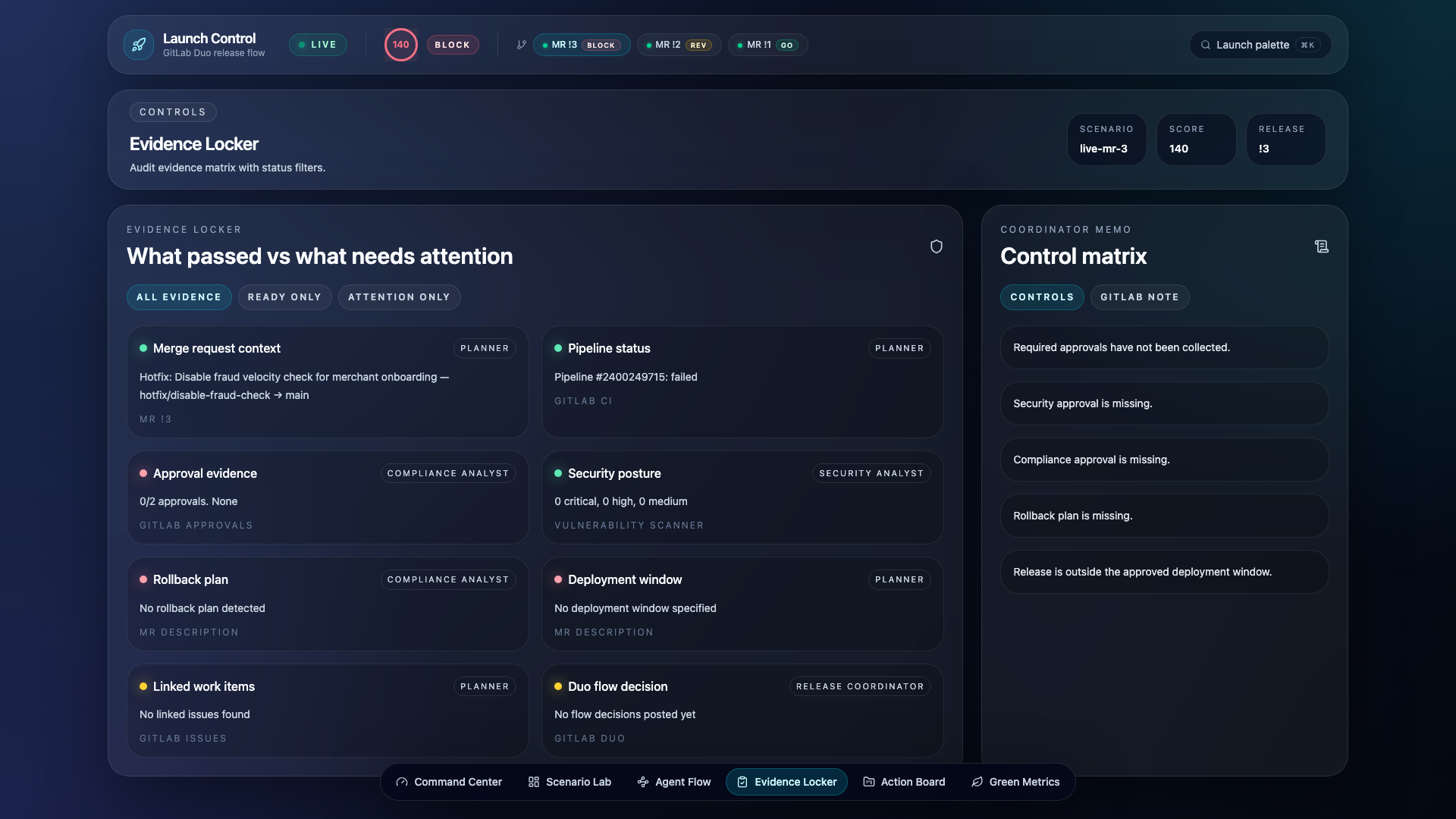
- Evidence Locker — Per-item audit status mapped to source and owning agent
- Action Board — Kanban-style board with Blocked / Human Review / Ready To Ship lanes
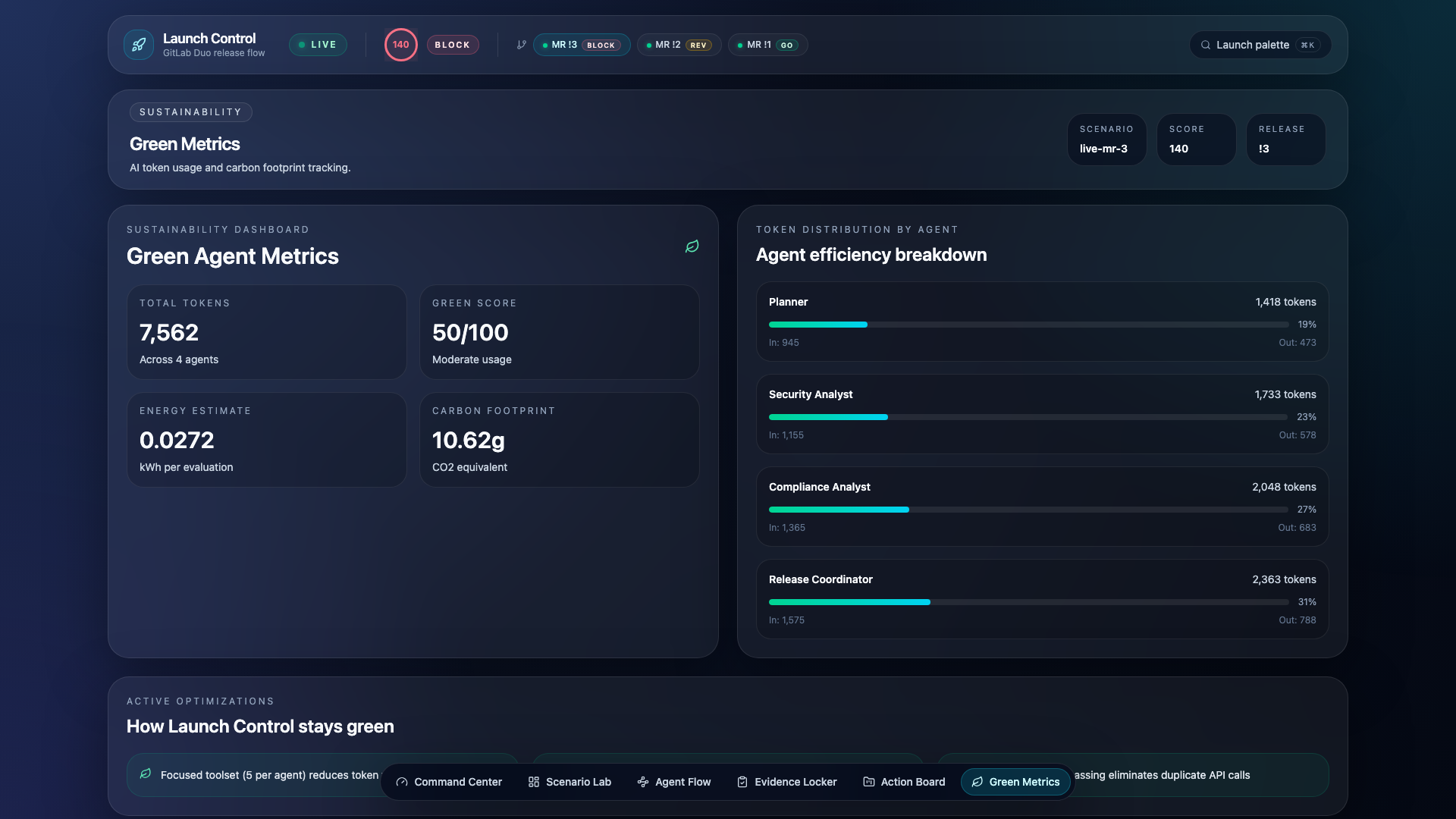
- Green Metrics — Token efficiency, energy consumption, and carbon footprint per evaluation
Automatic Remediation
When the system issues a BLOCK, it doesn't just say "fix it." The Release Coordinator opens GitLab issues for each blocker with specific remediation steps — one issue per blocker, linked back to the MR.
How we built it

GitLab Duo Flow is the backbone. The flow definition (.gitlab/duo/flows/release-evaluation.yaml) chains four AgentComponent stages with sequential routing. Each agent has a scoped prompt and a curated toolset of 5 GitLab-native tools. Keeping toolsets small is deliberate — it reduces token waste and keeps agent reasoning focused.
Custom agent (agents/launch-control.yml) — A public GitLab Duo Chat agent with 24 tools for interactive release evaluation. Users can also chat with the agent directly in GitLab Duo Chat to ask about release readiness.
Flow triggers — The flow is triggered by mentioning the service account in an MR comment, or by assigning the service account as a reviewer. The trigger is configured via Automate → Triggers pointing to the flow YAML.
Risk scoring engine — A deterministic, weighted-sum evaluator (evaluateRelease.ts) that scores release context against the risk matrix. The engine runs both server-side for the dashboard and inside the agent chain (via the Coordinator's prompt). Same policy, same math, zero divergence.
Live GitLab API integration — The server fetches MR data, pipelines, approvals, notes, and linked issues in parallel via Promise.all. It parses existing Launch Control decision notes from the MR thread to show evaluation history. The mrDataToReleaseContext function transforms raw GitLab API responses into a typed ReleaseContext consumed by the scoring engine.
Policy-as-code architecture — Three YAML files define all operational policy:
release-policy.yaml— Per-environment requirements (approval counts, sign-offs, rollback plans, deployment windows)compliance-policy.yaml— Evidence requirements, minimum linked issues, exception labelsrisk-matrix.yaml— 11 weighted scoring factors, GO/REVIEW/BLOCK thresholds, hard blocker definitions
Frontend — React 19 with Framer Motion for the Command Center dashboard. Built with Vite. Connect any GitLab project via the onboarding screen — enter a project URL and personal access token, and the dashboard loads live workspace views for all open MRs.
Input validation — Zod schemas validate all API inputs at the boundary. The releaseContextSchema enforces typed, bounded release payloads before they reach the scoring engine.
Sustainability tracking — Every evaluation calculates token usage per agent, estimated energy consumption (kWh), and carbon footprint (grams CO2). The green score incentivizes efficient agent architecture.

Challenges we ran into
Agent toolset scoping. Giving agents access to all GitLab tools caused rambling, unfocused evaluations with hallucinated findings. We iterated to exactly 5 tools per agent — enough capability to gather evidence, constrained enough to prevent drift. This constraint also measurably reduced token consumption.
Policy drift between agents and dashboard. Early versions had the agent chain using its own interpretation of "safe to release" while the dashboard scored with different logic. We eliminated divergence by making evaluateRelease.ts the single source of truth, consumed by both the live data path and the agent chain path.
Structured output parsing from MR notes. The Release Coordinator posts decisions as formatted Markdown in MR comments. Extracting decisions, risk scores, and action items back from those notes required regex parsing of our own output format — necessary for the feedback loop that displays evaluation history in the Command Center.
Threshold calibration. Initial risk weights produced too many false BLOCKs. A missing doc update was scoring the same as a missing rollback plan. We iterated the weights in risk-matrix.yaml until the scoring aligned with real release scenarios — and because it's YAML, each iteration was a one-line edit with zero code changes.
Accomplishments that we're proud of
Zero-code policy changes. A compliance officer can change release requirements by editing a YAML file. No developer involvement. No redeployment. The same policy file governs both the AI agent chain and the deterministic scoring engine simultaneously.
Full audit trail. Every decision is posted as a GitLab MR note with structured evidence — blockers, risk score, required actions. The Evidence Locker in the dashboard maps each finding to its source and owning agent. This is not a black box — every verdict is traceable to the signal that produced it.
Automatic remediation. BLOCK decisions generate GitLab issues for each blocker with specific remediation steps. The system doesn't just flag problems — it creates the work items to fix them.
Sustainability-first architecture. We track token usage, energy, and carbon per evaluation. The focused toolset design (5 tools per agent) and inter-agent context passing aren't just for accuracy — they produce measurably lower token consumption than giving agents broad tool access.
Two converging paths, one engine. The Duo Flow path (for the agent chain) and the live GitLab API path (for the dashboard) both feed into the same evaluateRelease scoring logic with the same policy files. Two interfaces, zero scoring divergence.
What we learned
Policy-as-code is underrated. The moment we moved thresholds out of TypeScript and into YAML, iteration speed increased by an order of magnitude. Testing "what if critical vulns score 30 instead of 50?" became a one-line edit instead of a code change, build, and deploy cycle.
Agent chains need hard constraints. The difference between a useful agent and a rambling one is toolset size. Five tools per agent was the sweet spot — enough capability for evidence gathering, bounded enough to prevent hallucinated findings and token waste.
Deterministic scoring and AI reasoning are complementary. The weighted risk score gives you reproducibility and auditability. The agent chain gives you natural-language synthesis and context-aware judgment. Neither alone is sufficient — the risk score can't explain why a rollback plan matters for this specific change, and the agent can't guarantee consistent thresholds across evaluations.
Sustainability isn't a checkbox. Tracking token usage per agent changed how we designed the system. When you can see that a broad toolset costs 3x more tokens with no accuracy gain, the architecture decision makes itself.
What's next for Launch Control
- Pipeline event triggers — Trigger evaluations automatically on pipeline completion via GitLab Duo trigger events
- Multi-MR release trains — Evaluate batched releases where risk compounds across merge requests
- Policy marketplace — Shareable policy templates for SOC 2, HIPAA, and PCI-DSS compliance frameworks
- Outcome feedback loop — Track whether BLOCK decisions prevented actual incidents, and auto-tune risk weights based on historical outcomes
- Notification integrations — Push decisions to Slack/Teams channels with one-click override for emergency changes
Built With
- api
- duo
- express.js
- framer
- gitlab
- motion
- node.js
- react
- typescript
- vite
- workflow
- yaml
- zod
Log in or sign up for Devpost to join the conversation.