-
-
agents
-
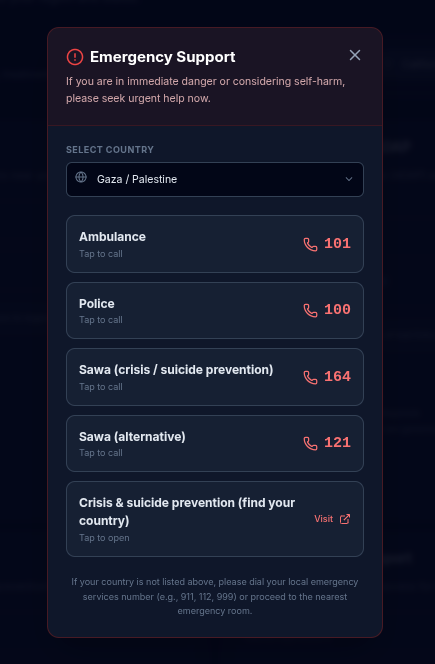
emergency help
-
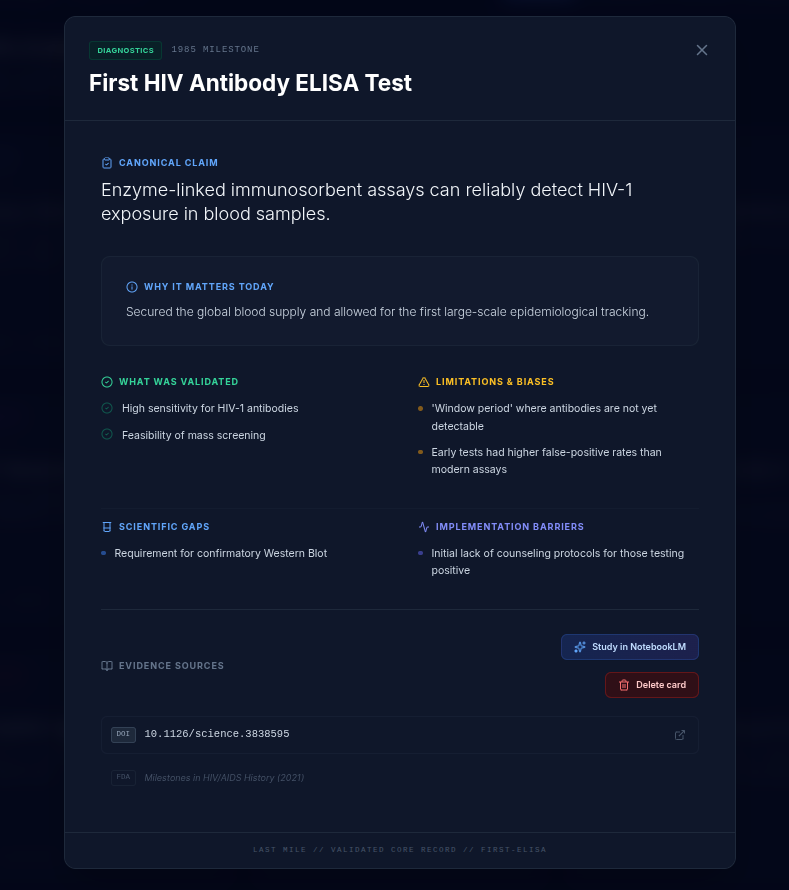
cards
-
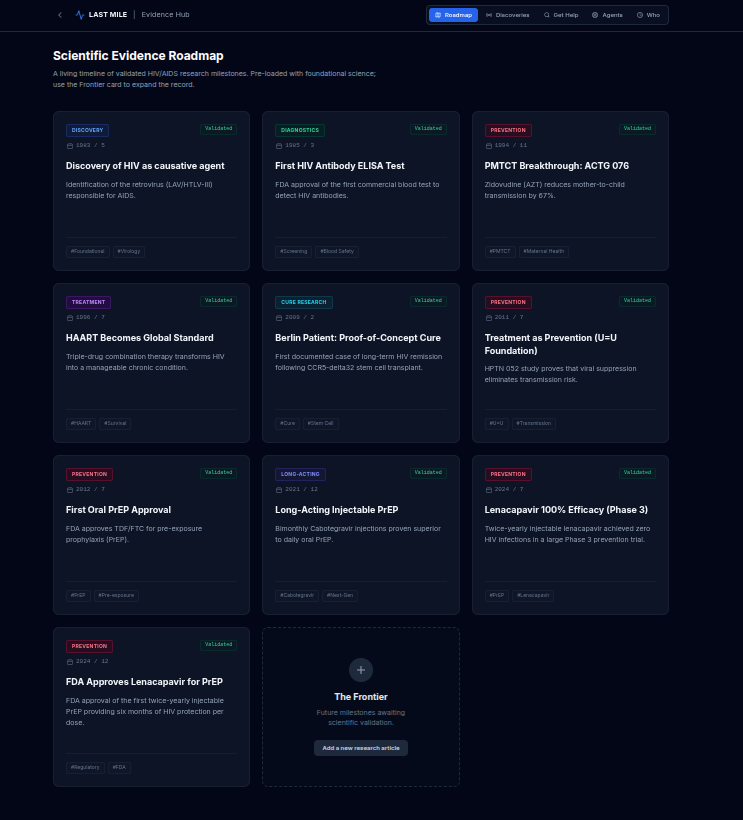
roadmap
-
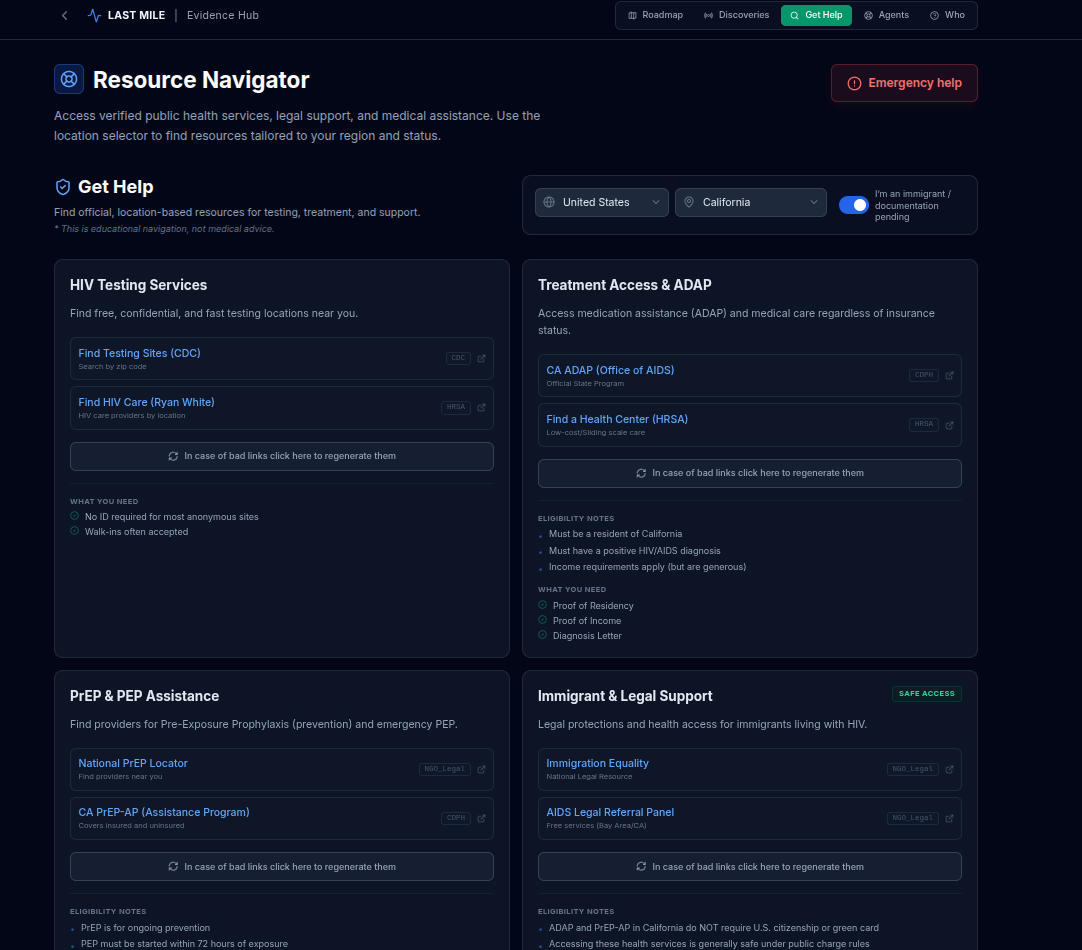
get help
-
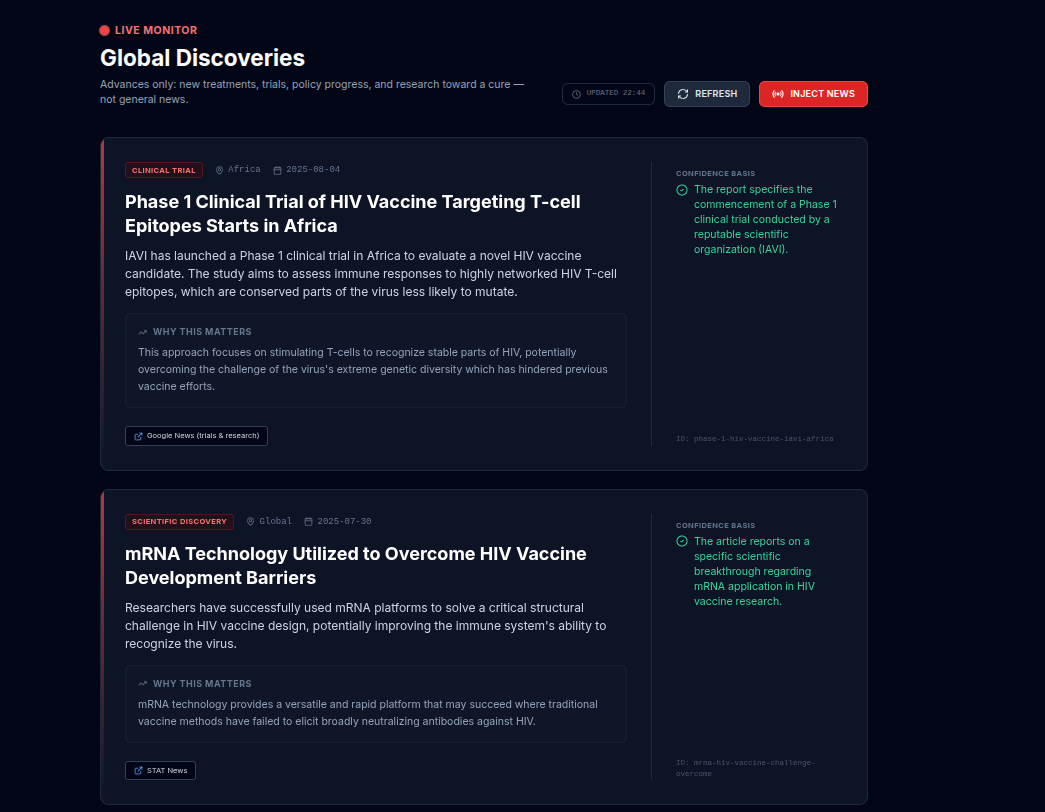
discoveries
-
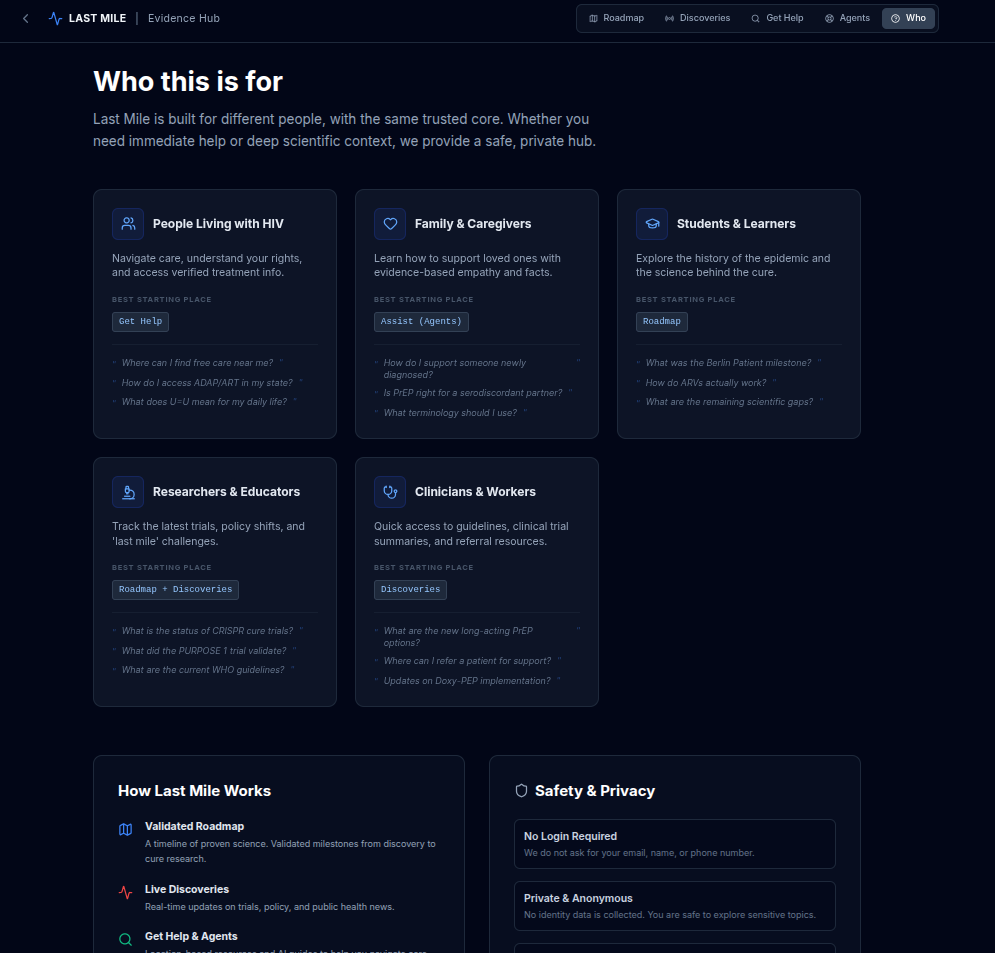
whoi s this for
-
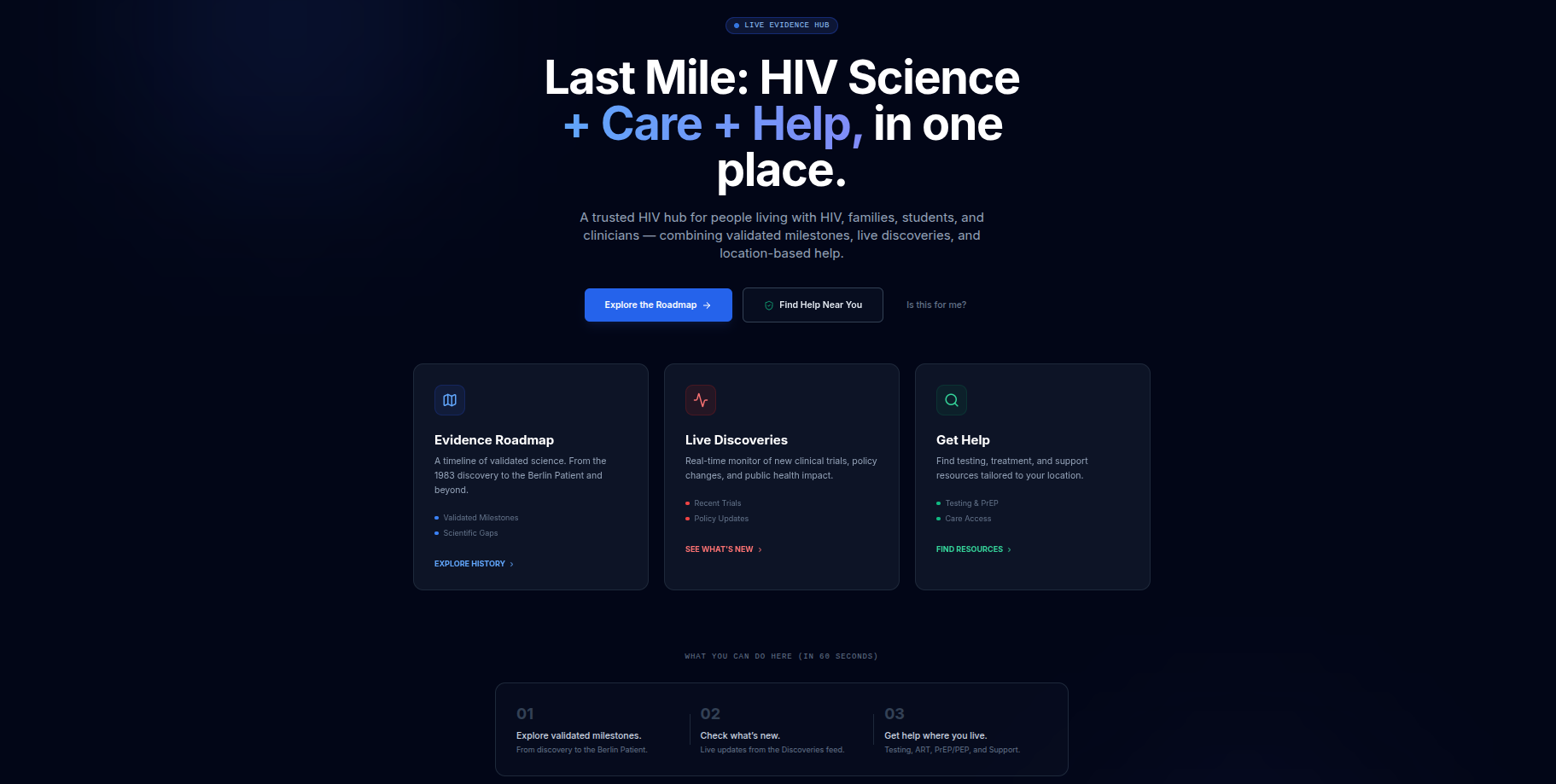
home
Last Mile
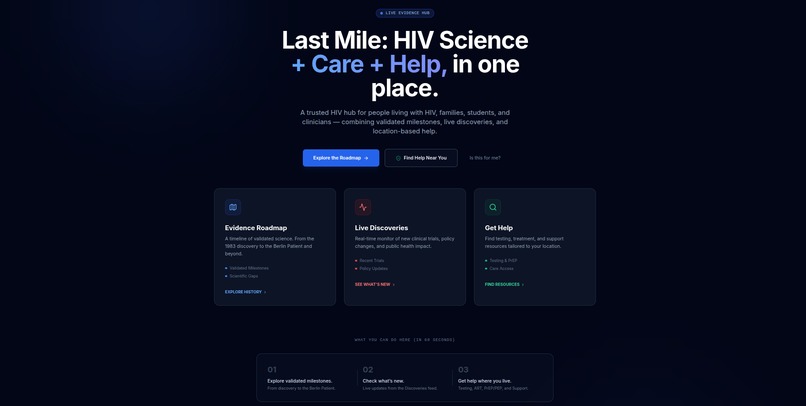
A trusted HIV hub connecting science, care, and real-world support
Validated scientific milestones, live research updates, and location-based care navigation — built for people living with HIV, families, students, and clinicians.
Inspiration
Last Mile emerged from direct engagement with the information ecosystem surrounding HIV science and care.
Over the past decades, HIV treatment, prevention, and research have advanced through robust scientific work. That knowledge now supports patients, families, clinicians, researchers, and public health systems worldwide. However, this information is distributed across many sources — academic literature, clinical trial registries, institutional guidelines, and local care systems — each designed for a specific audience and rarely connected.
As a result, different groups often face the same challenge:
not a lack of information, but a lack of integration, context, and orientation.
For people living with HIV and their families, this fragmentation can make it harder to understand the current scientific landscape, identify reliable guidance, and navigate available care options.
For students, clinicians, and researchers, it creates additional effort to track validated milestones, recent discoveries, and practical implications across multiple channels.
The role of a hub in this context is not only technical, but human.
When information is accessible, structured, and grounded in evidence, it supports better decisions, reduces uncertainty, and helps people engage with care systems more confidently — without replacing professional medical guidance.
Last Mile began with a practical goal:
To bring together validated HIV science, live research updates, and location-based care navigation into a single, trustworthy hub — supporting both scientific understanding and real-world human needs.
What it does
Last Mile is an evidence-based science and humanitarian navigation hub focused on HIV care, research, and access.
It connects validated scientific knowledge with practical, real-world support, translating complex information into clarity, context, and actionable guidance — while maintaining strict medical, ethical, and regulatory boundaries.
The platform helps users:
- Understand what HIV science has proven, what is experimental, and what remains unknown
- Follow recent scientific, clinical, and public health developments in context
- Navigate testing, treatment, prevention, and care systems by location
- Access clear, step-by-step guidance through public and institutional processes
- Regain orientation, confidence, and realistic expectations through evidence-based information
Last Mile does not provide medical diagnosis or treatment decisions.
Its role is education, navigation, and support — always encouraging consultation with qualified healthcare professionals.
How we built it
The platform is structured around three complementary pillars, supported by a domain-constrained AI architecture built on Gemini 3 Flash Preview, with live discovery feeds, server and client caching, regenerate-links for Get Help cards, and strictly constrained navigation agents.
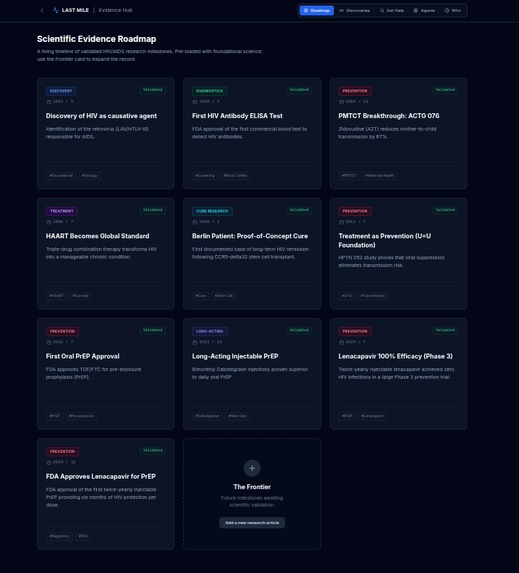
1. Evidence Roadmap
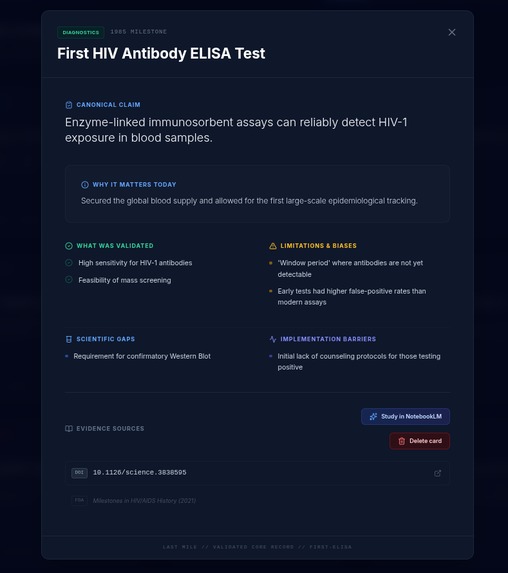
A chronological, evidence-based map of HIV research milestones — from early antiretroviral therapy and treatment-as-prevention to PrEP, long-acting injectables, functional cures, and exceptional cases such as the Berlin Patient.
Milestones are extracted and structured using Gemini 3 Flash Preview in services/geminiService.ts, guided by strict system instructions (prompts.ts — SYSTEM_INSTRUCTION) to:
- Parse scientific abstracts, policy documents, and institutional reports
- Distinguish validated evidence from ongoing or experimental research
- Identify scientific and implementation gaps explicitly
- Preserve traceability to primary identifiers (PMIDs, DOIs, NCT numbers)
Caching & performance: Evidence analysis is cached at two layers to avoid redundant Gemini calls and keep latency low. The server (server.ts, api/analyze.ts) keeps an in-memory (RAM) cache keyed by a fast hash of the input text, with a cap of 100 entries (FIFO eviction). The client (utils/analysisCache.ts) uses an in-memory Map (max 50 entries) plus sessionStorage (max 20 entries persisted across navigations within the same tab). Repeated analysis of the same text returns instantly from cache without hitting the model.
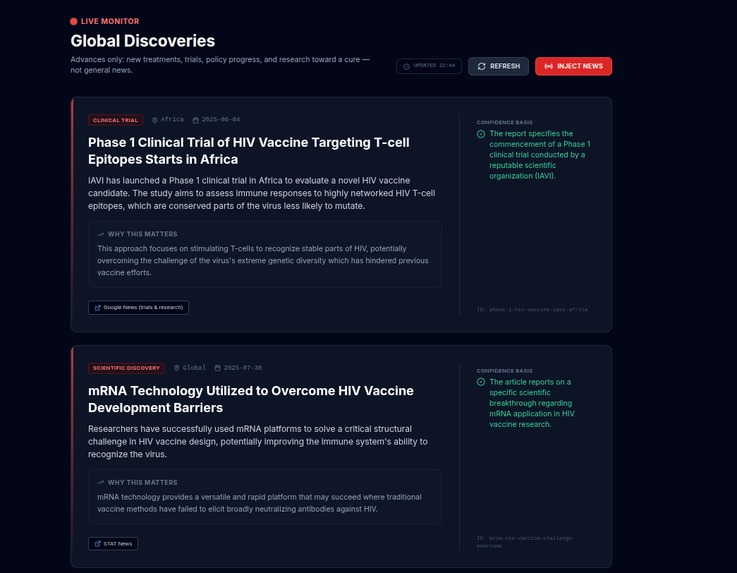
2. Live Discoveries (Live Feed)
A continuously updated feed of scientific discoveries, policy changes, and clinical trial updates.
This layer uses Gemini 3 Flash Preview across two services:
services/discoveryMonitor.ts— Fetches RSS feeds (e.g. Google News HIV/trials/research), filters HIV-related items, deduplicates, and whenGEMINI_API_KEYis set sends raw items to Gemini for validation and formatting.services/geminiDiscovery.ts— Batch processing with Gemini 3 Flash Preview andDISCOVERY_FORMAT_BATCH_INSTRUCTION: one API call per batch of items (batch size 4), returning structured discovery cards (or rejection with reason). Only advances (trials, approvals, guidelines, implementation) are accepted; access cuts, sensational or off-topic news are rejected.
Overload protection & parallelism: To avoid overloading the model and to improve throughput, we process RSS items in batches of 4 and run at most 2 batches in parallel via api/utils/concurrency.ts (runWithConcurrencyLimit). We cap the number of items sent to Gemini at 8 (maxWithGemini) and apply an 18-second timeout per batch; on timeout we skip that batch and continue. This keeps request volume and latency predictable.
Cache:
- Server: Discovery results are cached on disk (
data/discoveryCache.json) or in Vercel serverless/tmp, with a 1-hour TTL.GET /api/discoveries/feeduses cache when valid;POST /api/discoveries/refreshor?refresh=1forces a fresh RSS fetch and Gemini run. - Client:
utils/discoveryFeedCache.tsstores the feed in localStorage and enforces a 15-minute cooldown between fetches; the Refresh button bypasses cooldown and triggers a server refresh. This reduces API and Gemini load while keeping the feed fresh enough for users.
Endpoints:
GET /api/discoveries/feed— Returns latest discoveries (from cache or live).POST /api/discoveries/refresh— Forces refresh (RSS + Gemini), updates cache, returns new list.
A scheduled cron (e.g. hourly) can call refresh so the feed stays updated without user action.
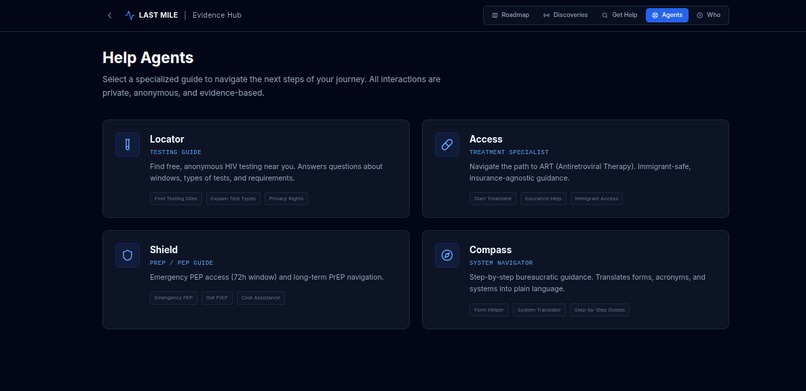
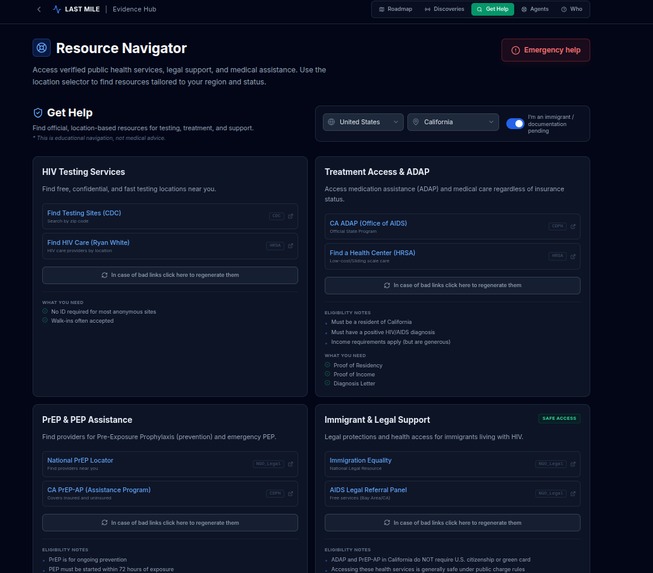
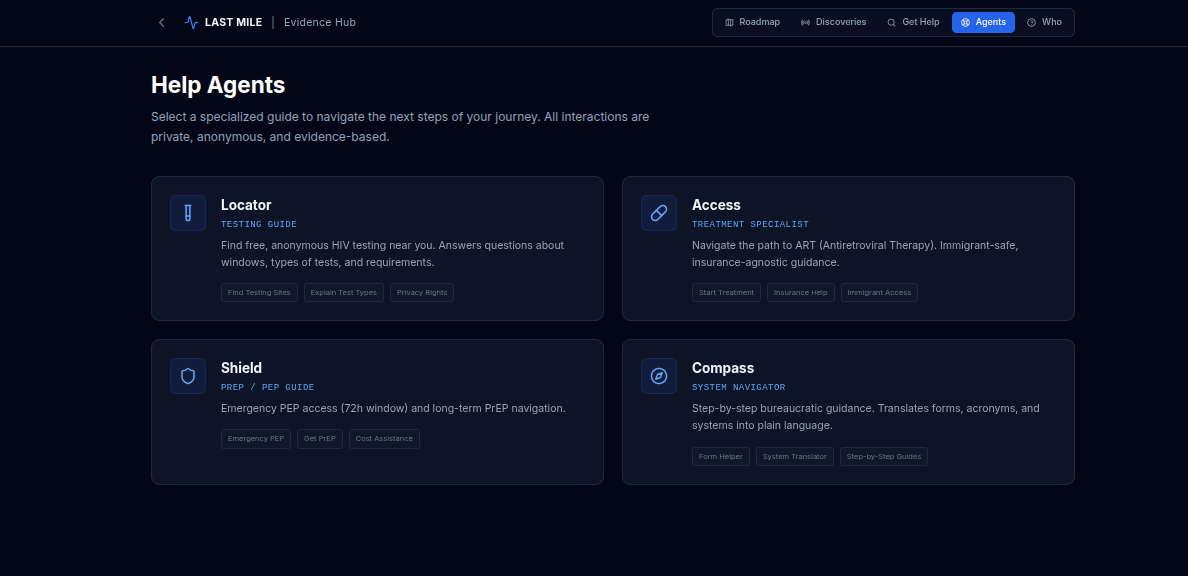
3. Get Help & Navigation Agents
A set of non-diagnostic AI agents focused on humanitarian assistance and system navigation, powered by Gemini 3 Flash Preview and constrained by strict system instructions and agent constraints.
Each agent is defined in services/agentService.ts with a persona: id, name, role, description, inScope, and handoffTopics (topic, referToAgentName, triggerKeywords). The chat UI (components/AgentChat.tsx) builds a dynamic system instruction for Gemini that:
- Enforces STEP 1 — Mandatory handoff: if the user's message matches another agent's topic or keywords, the model must only acknowledge and refer to that agent (e.g. "This is better handled by Shield. Continue the conversation there.") and must not give substantive medical or location advice.
- STEP 2 — Narrow scope: only if no handoff applies, the model answers strictly within
inScope(e.g. "Only: where to get tested…", "Only: PEP, PrEP, prevention…"), one clear next step at a time.
Agent constraints in code:
- Locator — Testing sites, test types, window periods, privacy. Handoffs: Access (treatment/ART), Shield (PrEP/PEP), Compass (forms/acronyms).
- Access — Path to ART, eligibility, immigrant-safe access. Handoffs: Locator, Shield, Compass.
- Shield — PEP (72h), PrEP, prevention. Handoffs: Locator, Access, Compass.
- Compass — Forms, acronyms, step-by-step system navigation. Handoffs: Locator, Access, Shield.
Style rules in the system instruction: calm, short, no emojis, no diagnosis, no legal claims.
Regenerate links:
Get Help cards show location-specific links (from data/helpContent.ts). If links are broken or outdated, users can regenerate them via Gemini 3 Flash Preview:
- Endpoint:
POST /api/help/regenerate-links(body:cardId,title,description,locationLabel, optionalcurrentLinkLabels). - Service:
regenerateHelpLinks()inservices/geminiService.tsuses Gemini 3 Flash Preview withHELP_LINKS_SYSTEM_INSTRUCTIONto return 2–5 current, official HTTPS links (government, WHO, UNAIDS, HRSA, CDC, PAHO, UNHCR, etc.) withlabel,url,authority, and optionalnote. Output is JSON-only; responses are validated and filtered to HTTPS only.
Technical Architecture & Use of Gemini AI
Last Mile uses Gemini 3 Flash Preview as a domain-specific reasoning and extraction layer across all AI-backed services, not as a general-purpose chatbot.
The model is used in a highly constrained, role-based manner, with:
- Prompt design and system-level instructions in
prompts.ts - Structured JSON output (
responseMimeType: "application/json") where applicable - Domain restriction (HIV/AIDS-only), identifier grounding for evidence, and explicit agent boundaries (no diagnosis, no treatment decisions)
Where Gemini is used (services)
| Service / Layer | File(s) | Gemini role |
|---|---|---|
| Evidence analysis | services/geminiService.ts |
analyzeEvidence() — milestone extraction from text; system instruction: SYSTEM_INSTRUCTION |
| Live discovery formatting | services/geminiDiscovery.ts |
formatNewsItemBatch() — batch validation/formatting of RSS items into discovery cards; system instruction: DISCOVERY_FORMAT_BATCH_INSTRUCTION |
| Discovery single-item (legacy/alternative) | services/geminiService.ts |
analyzeDiscovery() — single discovery card from text; system instruction: DISCOVERY_SYSTEM_INSTRUCTION |
| Get Help link regeneration | services/geminiService.ts |
regenerateHelpLinks() — current official links for a card/location; system instruction: HELP_LINKS_SYSTEM_INSTRUCTION |
| Get Help agent chat | components/AgentChat.tsx |
Chat with Gemini 3 Flash Preview; system instruction built from AGENTS (inScope, handoffTopics), enforcing handoffs and single-scope answers |
Model usage
Model: gemini-3-flash-preview
- Evidence analysis and milestone extraction (
analyzeEvidence) - Live discovery ingestion: batch formatting in
geminiDiscovery, optional single-item ingeminiService - Get Help: agent chat (AgentChat), regenerate-links (
regenerateHelpLinks) - Low-latency, cost-efficient processing suitable for real-time and batch use
Evidence grounding & domain safety
- Domain gate: System instructions restrict content to HIV/AIDS-related topics. Off-domain or non-advance content is rejected (e.g. discovery feed rejects access cuts, sensational news).
- Identifier grounding: Evidence roadmap prompts require primary identifiers (PMID, DOI, NCT); outputs without valid grounding are constrained (e.g. status "Ongoing" / "Experimental").
- Role boundaries: Navigation agents are instructed not to give medical diagnoses, treatment decisions, or personalized clinical advice; handoffs keep each agent within its defined scope.
Performance: caching, parallelism, and avoiding model overload
We designed the system to avoid overloading the Gemini API, to reduce latency, and to keep costs under control.
Avoiding model overload
- Evidence: Every analysis request is keyed by a hash of the input. Server and client check their caches first; only cache misses call Gemini. Server RAM cache (100 entries) and client RAM + sessionStorage (50 + 20 entries) drastically cut duplicate requests.
- Discovery feed: RSS items are batched (4 items per Gemini call) so we make fewer, larger requests instead of one per item. We cap the number of items sent to Gemini at 8 (
maxWithGemini). We run at most 2 batches in parallel (runWithConcurrencyLimitwithCONCURRENCY = 2), and each batch has an 18s timeout so a slow response does not block the pipeline. Discovery results are cached on the server (disk or/tmp, 1h TTL) and on the client (localStorage + 15‑min cooldown), so repeated feed loads rarely hit the API. - Regenerate links & agent chat: Single-request flows; no batching, but they benefit from the same domain and instruction constraints so responses stay small and predictable.
Parallelism
- Discovery pipeline (
discoveryMonitor.ts): RSS items are split into chunks of sizeBATCH_SIZE(4). Chunks are processed byrunWithConcurrencyLimit(chunks, CONCURRENCY, …)withCONCURRENCY = 2, so two batches are in flight at once. Each batch callsformatNewsItemBatch()ingeminiDiscovery.ts. This gives steady throughput without flooding the API.
Caching layers (summary)
| Layer | Store | Use case | Limits / TTL |
|---|---|---|---|
| Server RAM | Map in server.ts / api/analyze.ts |
Evidence analysis | 100 entries, hash key, FIFO |
| Client RAM | Map in utils/analysisCache.ts |
Evidence analysis | 50 entries, FIFO |
| Client session | sessionStorage |
Evidence analysis (persist in tab) | 20 entries |
| Server disk | data/discoveryCache.json or /tmp |
Discovery feed | 1 hour TTL |
| Client local | localStorage in utils/discoveryFeedCache.ts |
Discovery feed + cooldown | 15‑min cooldown between fetches |
Privacy & trust by design
- Stateless AI interactions where possible; no persistent user profiles; no training on user data; no mandatory accounts.
- Sessions are isolated so users can access sensitive health-related information without leaving a persistent digital footprint.
Challenges we ran into
The main challenges were conceptual and ethical rather than technical.
Balancing scientific rigor with real-world usability required careful design choices:
- Avoiding misinformation, oversimplification, or false expectations
- Respecting medical, ethical, and regulatory boundaries
- Designing for clarity and reassurance without crossing into medical advice
Another challenge was reflecting the true nature of scientific progress — incremental, evidence-driven, and often misunderstood — without exaggeration or pessimism.
Technical challenges: avoiding model overload and improving performance
- Controlling request volume: Sending every RSS item or every analysis to Gemini would have caused rate limits, high latency, and cost. We introduced batching (e.g. 4 items per call for discoveries), a concurrency limit (2 parallel batches), a cap on items sent to Gemini (8 for discovery), and timeouts (18s per batch) so slow or stuck calls do not pile up.
- Reducing duplicate calls: Many users request the same evidence text or the same discovery feed. We added multi-layer caching: RAM on server and client for evidence (100 and 50 entries), sessionStorage (20 entries) so repeated analyses in the same session skip the API, disk/
/tmpfor the discovery feed (1h TTL), and localStorage plus a 15‑minute cooldown for the feed on the client. Cache hits avoid Gemini entirely and improve perceived performance. - Parallelism without overload: We use
runWithConcurrencyLimitso the discovery pipeline processes 2 batches at a time instead of sequentially, improving throughput while keeping concurrent Gemini requests bounded.
Accomplishments that we're proud of
- Unifying HIV science, care navigation, and human-centered support in a single platform
- Applying AI responsibly within strict medical and ethical constraints
- Making decades of complex research understandable without oversimplifying it
- Building a trusted resource for patients, families, students, and clinicians
- Delivering a live discovery feed with Gemini-backed validation and server/client cache for performance and cost control
- Enabling regenerate links for Get Help cards so resource links stay current via Gemini
- Enforcing agent constraints and handoffs so each navigation agent stays in scope and defers to the right agent
- Performance and resilience: Batching, concurrency limits, timeouts, and RAM + sessionStorage + localStorage + disk cache to avoid model overload and to make repeated use fast and predictable
What we learned
We learned that access to medicine alone is not enough — access to understanding, structure, and trust is equally important.
Across all audiences, the core challenge is rarely lack of data, but lack of integration and context.
We also learned that AI can support healthcare responsibly without replacing clinicians — by helping people understand information, ask better questions, and navigate systems with confidence.
We learned that controlling API load through batching, concurrency, timeouts, and layered caching (sessionStorage, localStorage, RAM, disk) is essential for a good user experience and sustainable use of the model.
What's next for Last Mile
Last Mile will continue to evolve as a global HIV science and care hub:
- Expanding localized help pathways to more countries
- Strengthening discovery ingestion from trusted scientific and public health sources
- Developing deeper educational tools for students, educators, and clinicians
- Collaborating with research groups and public health initiatives
- Continuously refining the balance between scientific rigor, usability, and humane support
The mission remains the same
To close the last mile between scientific knowledge, real-world care, and the people whose lives depend on both.
Application architecture
High-level flow of the application: frontend, API/server, Gemini-backed services, and caches.
flowchart TB
subgraph Frontend["Frontend (React / Vite)"]
LP[LandingPage]
EF[Evidence Roadmap / Analyzer]
DF[DiscoveryFeed]
GH[Get Help]
AC[AgentChat]
EF --> EF_RAM["RAM cache (50)"]
EF --> EF_SS["sessionStorage (20)"]
DF --> DF_LS["localStorage + 15min cooldown"]
end
subgraph API["API layer (Express / Vercel serverless)"]
A_AN["POST /api/analyze"]
A_F["GET /api/discoveries/feed"]
A_R["POST /api/discoveries/refresh"]
A_REG["POST /api/help/regenerate-links"]
end
subgraph ServerCaches["Server caches"]
RAM_AN["RAM cache (100) - evidence"]
DISK_F["Disk /tmp - discovery (1h TTL)"]
end
subgraph Services["Backend services"]
GEM_SVC[geminiService]
GEM_DISC[geminiDiscovery]
MONITOR[discoveryMonitor]
AGENTS[agentService - AGENTS]
end
subgraph Gemini["Gemini 3 Flash Preview"]
G_API[API]
end
LP --> EF
LP --> DF
LP --> GH
GH --> AC
EF -->|analyze text| A_AN
A_AN --> RAM_AN
RAM_AN -->|miss| GEM_SVC
GEM_SVC --> G_API
GEM_SVC -->|analyzeEvidence| G_API
DF -->|feed / refresh| A_F
DF --> A_R
A_F --> DISK_F
A_R --> DISK_F
DISK_F -->|miss / refresh| MONITOR
MONITOR -->|RSS fetch| RSS[RSS sources]
MONITOR -->|batches of 4, concurrency 2| GEM_DISC
GEM_DISC -->|formatNewsItemBatch| G_API
MONITOR --> DISK_F
GH -->|regenerate links| A_REG
A_REG --> GEM_SVC
GEM_SVC -->|regenerateHelpLinks| G_API
AC -->|chat| G_API
AC -->|system instruction| AGENTS
Legend
- Frontend: Evidence uses client-side RAM + sessionStorage before calling the API. Discovery uses localStorage and a 15‑minute cooldown to limit feed requests.
- API:
/api/analyzeand discovery endpoints check server caches first; only cache misses or explicit refresh trigger Gemini. - discoveryMonitor: Fetches RSS, filters and deduplicates, then sends items to geminiDiscovery in batches of 4 with concurrency 2 and an 18s timeout per batch; results are written to disk/
/tmpand returned. - geminiService: Handles
analyzeEvidence,analyzeDiscovery, andregenerateHelpLinks; all use Gemini 3 Flash Preview with the appropriate system instruction. - AgentChat: Calls Gemini directly from the client with a dynamic system instruction built from agentService (inScope, handoffTopics).
Simplified component view
┌─────────────────────────────────────────────────────────────────────────────┐
│ Last Mile Application │
├─────────────────────────────────────────────────────────────────────────────┤
│ React (Vite) │
│ ├── Evidence Roadmap → POST /api/analyze → RAM cache → geminiService │
│ ├── Live Discoveries → GET/POST discoveries/feed|refresh → disk cache │
│ │ → discoveryMonitor → RSS + geminiDiscovery (batch) │
│ ├── Get Help → cards + POST /api/help/regenerate-links │
│ │ → geminiService.regenerateHelpLinks │
│ └── Agent Chat → Gemini (client) + agentService personas │
├─────────────────────────────────────────────────────────────────────────────┤
│ Caches: │
│ • Evidence: server RAM (100) │ client RAM (50) + sessionStorage (20) │
│ • Discovery: server disk/tmp (1h) │ client localStorage + 15min cooldown │
├─────────────────────────────────────────────────────────────────────────────┤
│ Gemini 3 Flash Preview: evidence, discovery batch, regenerate-links, chat │
└─────────────────────────────────────────────────────────────────────────────┘
Built With
- aistudio
- google/genai
- node.js
- react
- react-dom
- typescript
- vite

Log in or sign up for Devpost to join the conversation.