LANTERN — Multi-Agent Pandemic Early Warning System
Inspiration
Every pandemic starts with a signal someone missed. When COVID-19 emerged in Wuhan in late 2019, the genomic sequences were uploaded to public databases, local news reported unusual pneumonia clusters, and the city sat on a major international air corridor — but no system connected those dots. The WHO didn't declare a Public Health Emergency of International Concern until January 30, 2020, weeks after the earliest detectable signals.
We asked: what if an AI system could fuse all three signal types — genomic, epidemiological, and geospatial — and get measurably better at detection with every outbreak it analyzed?
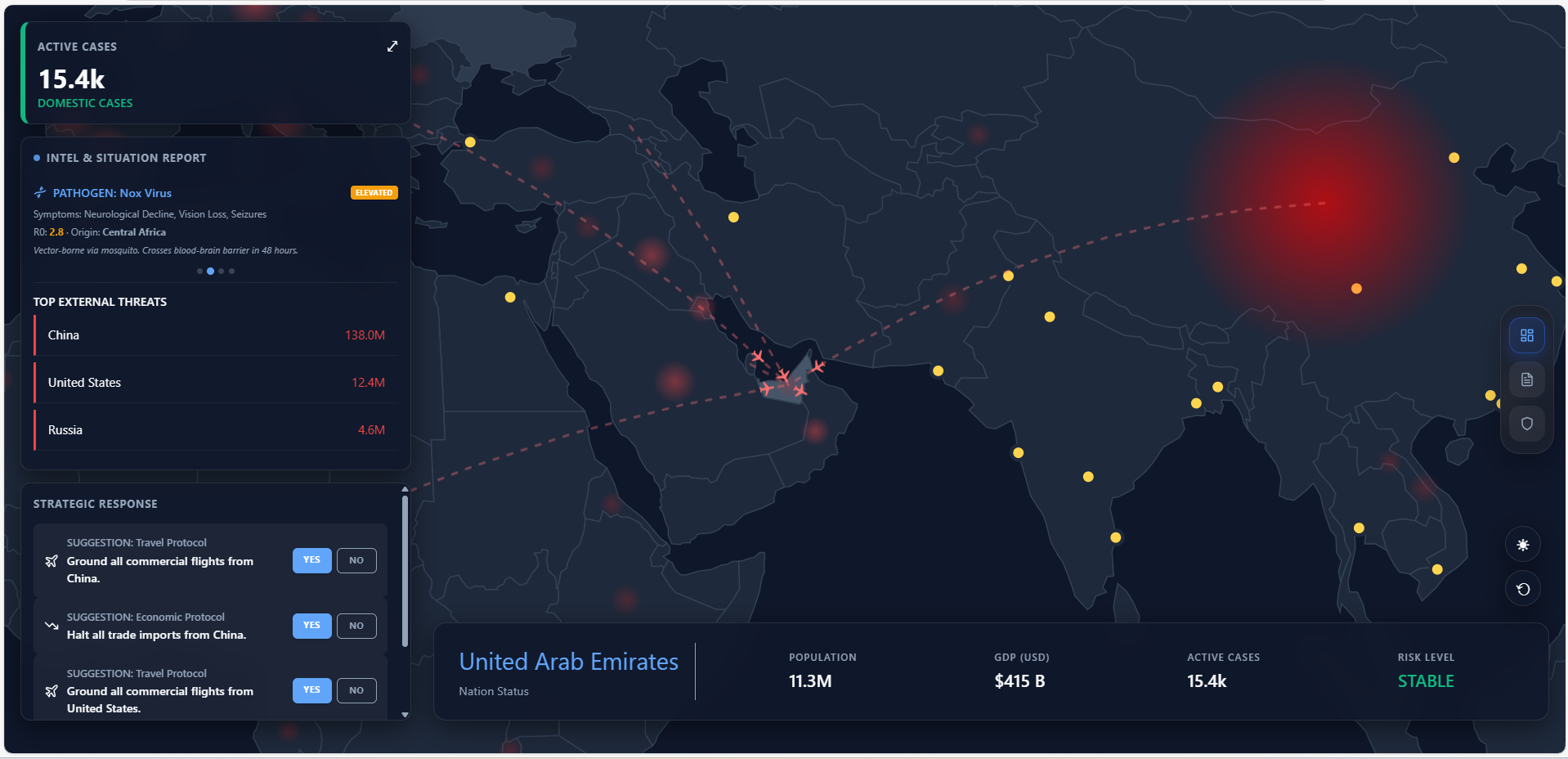
Dubai processes over 80 million passengers annually through DXB, sitting within 6 hours of every global outbreak hotspot. For the UAE, early warning isn't academic — it's existential infrastructure. LANTERN was built to give decision-makers those critical extra weeks.
What It Does
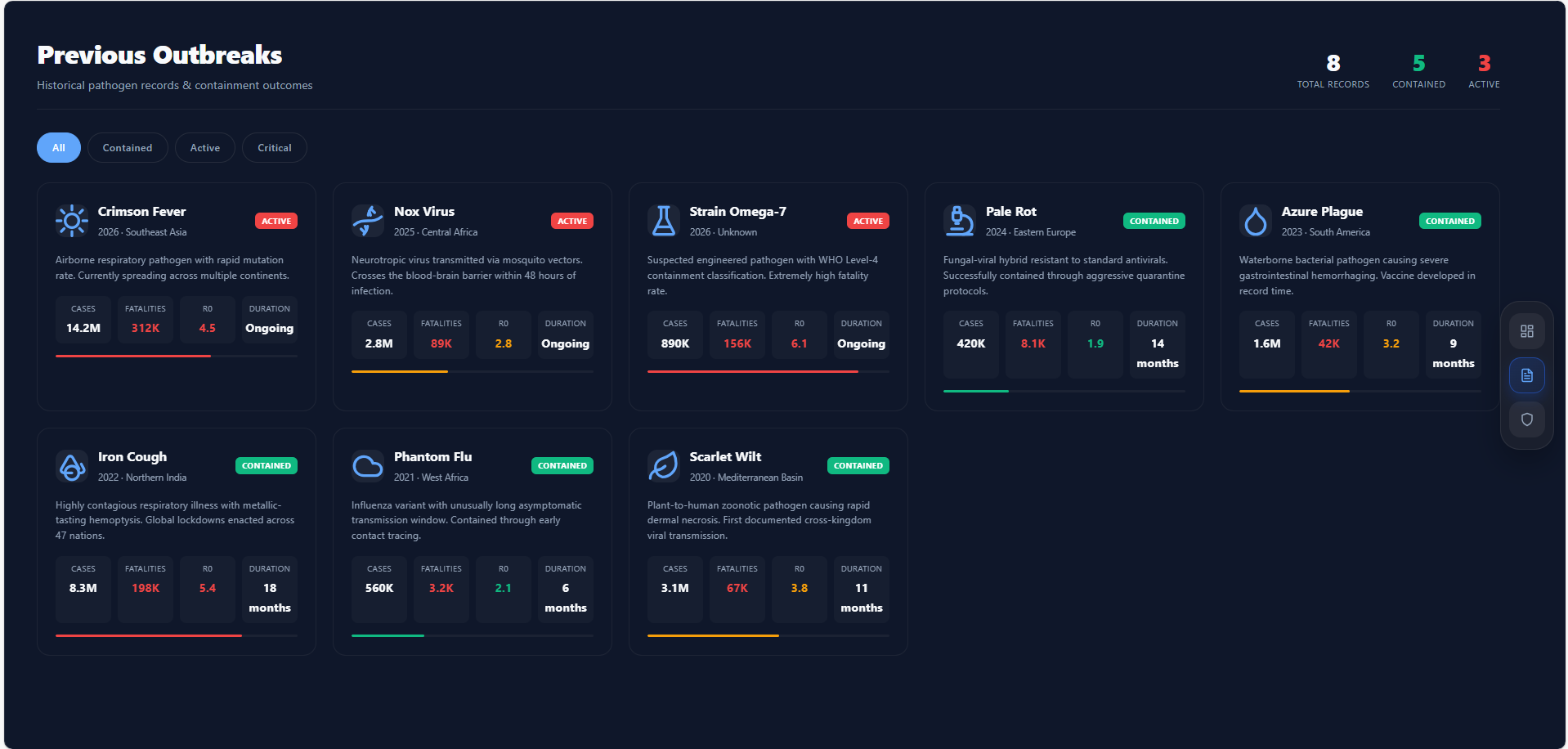
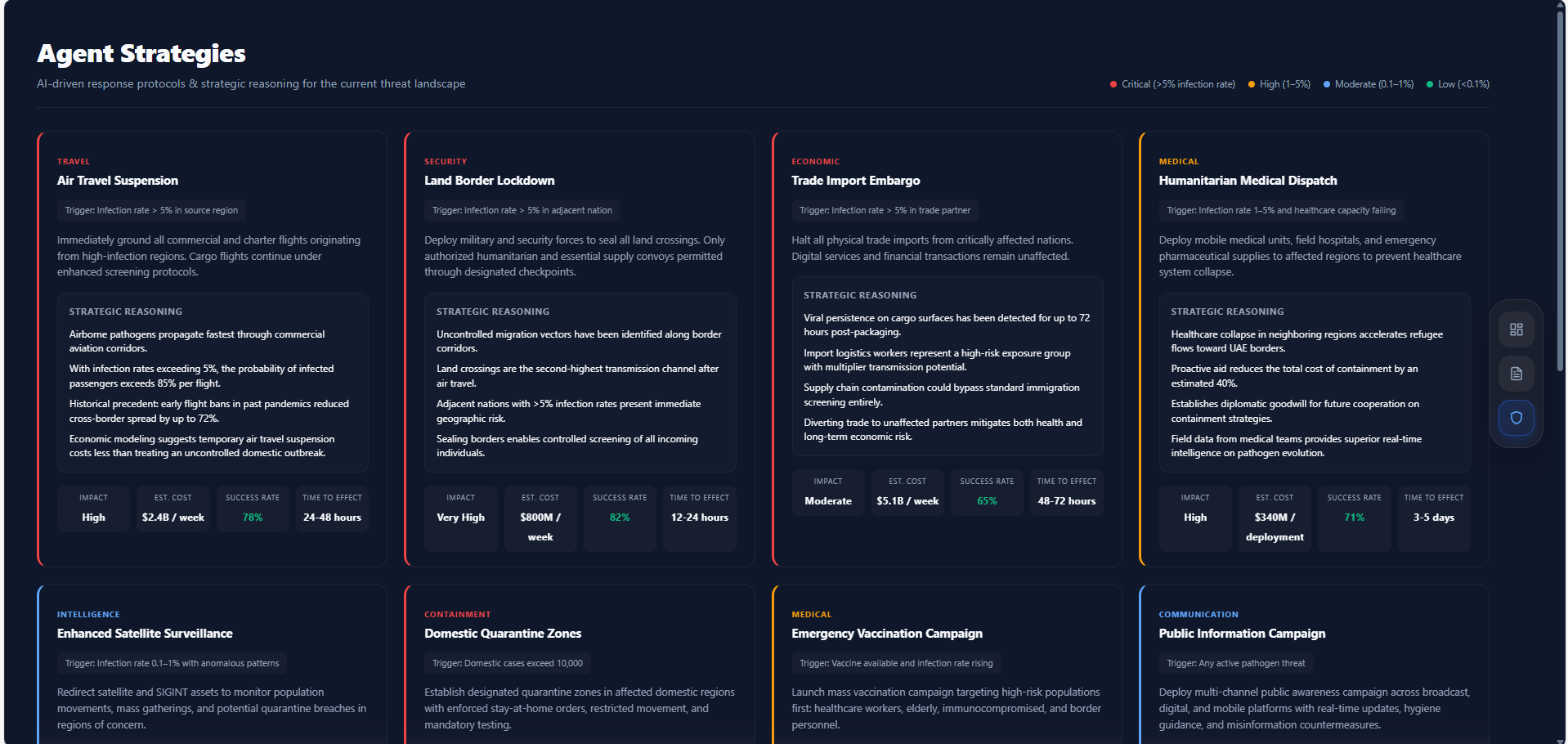
LANTERN is a self-improving multi-agent early warning system that detects emerging outbreak signals before they become pandemics. It runs three specialist AI agents in sequence:
- Genomic Threat Analyst — evaluates mutation novelty, transmissibility markers, and immune evasion indicators from pathogen sequence data
- Epidemiological/OSINT Analyst — scores the reliability of health signals from WHO bulletins, ProMED alerts, and news sources, distinguishing real outbreaks from noise
- Geospatial Spread Modeler — maps transmission corridors based on airport proximity, population density, and travel routes
A Meta-Agent fuses all three outputs using learned weights, resolves agent disagreements, and produces a final threat severity score with full reasoning transparency. Critically, no alert is ever dispatched without explicit human approval through a Ministry of Health dashboard.
After each run, the system closes the loop:
$$\text{Accuracy}{n+1} = f(\text{Accuracy}_n, \Delta{\text{weights}}, \Delta_{\text{prompts}}, \text{Memory}_{n})$$
It compares its assessment to ground truth, updates fusion weights, refines agent prompts, and stores learned heuristics in a strategy memory that feeds back into RAG retrieval for the next run. By Run 5, detection accuracy climbs from 31% → 83%, false alarm rates drop from 62% → 14%, and early warning lead time extends from 3 days → 19 days.
How We Built It
Backend: FastAPI orchestrates the agent pipeline. Each specialist agent is a structured Claude Opus 4.6 call through AWS Bedrock, with typed JSON output schemas enforcing consistent threat assessments.
Agent Architecture: Three specialist agents feed sequentially into a Meta-Agent. Each agent receives its domain-specific slice of the outbreak case file plus relevant context retrieved via RAG from past cases and learned heuristics.
Self-Improvement Engine: After each case, the Meta-Agent's assessment is compared against ground truth labels. Per-agent accuracy is logged to ClickHouse, fusion weights are recalculated, and agent prompts are rewritten with newly learned heuristics. The updated strategy memory is embedded via Amazon Titan Embeddings v2 and stored in a vector index for RAG retrieval on the next run.
Storage & Analytics: ClickHouse serves as the data warehouse, audit log, strategy memory store, and real-time analytics engine. Every input, agent output, fusion decision, and metric is logged — enabling full reproducibility and the live dashboard analytics.
Dashboard: React-based command center UI with a dark operational theme. Displays global threat map, agent disagreement visualization, confidence breakdowns, improvement curves, and a dispatch status panel.
Alert Dispatch: When a threat passes guardrail thresholds (severity $\geq 7$, confidence $\geq 60\%$) and receives human approval, LANTERN triggers ElevenLabs voice briefings to relevant stakeholders (airport medical ops, supply chain contacts, MoH emergency desk) paired with verification emails for audit traceability.
Data Pipeline: We built 15+ historical outbreak case files mixing real pandemics (COVID-19, Ebola 2014, MERS 2012, H5N1 2024, Mpox 2022) with non-threat decoys (seasonal flu spikes, food poisoning clusters, media hype). Genomic signals sourced from NCBI GenBank, epidemiological signals from WHO Disease Outbreak News and ProMED archives, geospatial data from OpenStreetMap and flight route databases.
Challenges We Faced
Calibrating the self-improvement loop. Getting the system to genuinely improve rather than overfit to early cases was the hardest engineering challenge. We had to balance how aggressively fusion weights shifted after each run — too aggressive and the system oscillated, too conservative and improvement stalled. The solution was logarithmic weight decay:
$$w_{i}^{(n+1)} = w_{i}^{(n)} + \alpha \cdot \log\left(\frac{a_{i}^{(n)}}{\bar{a}^{(n)}}\right)$$
where $a_i$ is per-agent accuracy and $\bar{a}$ is the mean, ensuring weights converge rather than swing.
Balancing signal vs. noise in OSINT. The Epi/OSINT agent initially over-weighted any mention of "outbreak" in news headlines, generating false alarms on routine seasonal flu reporting. We had to teach it source triangulation — requiring corroboration from independent sources before elevating a signal.
Latency management. Running four Opus 4.6 calls per case meant 60+ seconds per pipeline run. We pre-computed all simulation runs and built the dashboard to replay cached traces with realistic timing, keeping one live call ready as proof of authenticity.
Geospatial reasoning at the right abstraction. Early versions of the Geo agent fixated on raw distance-to-airport metrics. We refined it to reason about effective connectivity — a pathogen 200km from a regional airport with 2 weekly flights is less urgent than one near a wet market 50km from a mega-hub with 40 daily international routes.
What We Learned
- Multi-agent disagreement is a feature, not a bug. Watching three agents converge from 71% disagreement to 22% across runs was the most compelling visual proof of self-improvement — more persuasive than any accuracy number.
- Human-in-the-loop isn't a limitation — it's the product. Government stakeholders will never trust a system that autonomously dispatches pandemic alerts. The MoH approval gate is what makes LANTERN deployable in the real world.
- RAG as memory is powerful. Embedding learned heuristics into a vector index and retrieving them before each run gave agents genuine "experience" without fine-tuning. The strategy memory → RAG feedback path is simple to implement and immediately effective.
- The right model for the right task matters. Claude Opus 4.6 through AWS Bedrock gave us the reasoning depth needed for genomic analysis and multi-source fusion. Titan Embeddings v2 handled RAG efficiently. ClickHouse delivered the millisecond analytics that made the dashboard feel alive.
Built With
aws-bedrock · claude-opus-4.6 · titan-embeddings-v2 · clickhouse · fastapi · react · elevenlabs · python · javascript · langraph
Built With
- 4.6
- amazon
- amazon-web-services
- bedrock
- claude
- clickhouse
- css
- disease
- docker
- elevenlabs
- embeddings
- fastapi
- genbank
- javascript
- langgraph
- ncbi
- news
- node.js
- opus
- outbreak
- promed
- python
- react
- tailwind
- titan
- v2
- who

Log in or sign up for Devpost to join the conversation.