-
-
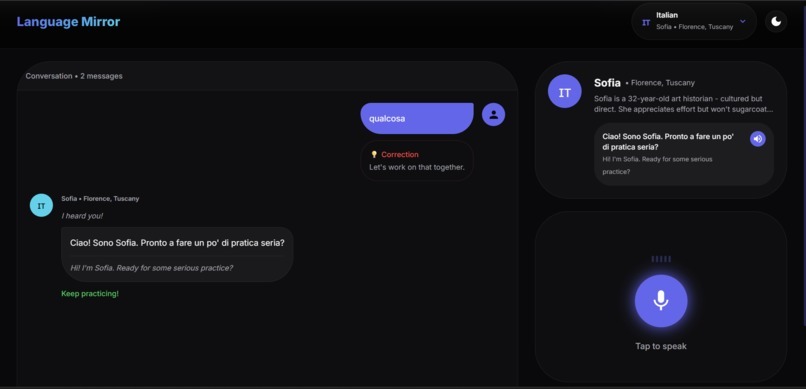
Dark Mode
-
Light Mode
Language Mirror
Talk to the world. Sound like you belong.
Inspiration
I've tried every language app out there. Duolingo, Babbel, Rosetta Stone—you name it. And they all have the same problem: they teach you textbook language, not real language.
Last year I was in Rome, confidently ordering "un caffè, per favore" just like my app taught me. The barista replied in rapid-fire Italian and I just... froze. Three years of practice and I couldn't hold a 30-second conversation.
That's when it hit me: we don't need more flashcards. We need practice talking to actual humans. But conversation partners are expensive, scheduling is a nightmare, and let's be honest—it's terrifying to stumble through broken sentences with a stranger.
What if AI could bridge that gap? Not as a robotic chatbot, but as a patient tutor with personality, cultural context, and a voice that actually sounds like someone from Milan or Tokyo or Mexico City?
What it does
Language Mirror is an immersive conversation tutor that lets you practice speaking with AI personas who feel genuinely human.
Pick your language. Pick your dialect (Roman Italian hits different than Milanese). Start talking.
The app listens to you speak, understands your intent, and responds in real-time with a voice that matches the regional accent you're learning. Make a grammar mistake? Your tutor gently corrects you mid-conversation, the way a friend would—not with a red X and a buzzer sound.
Each tutor has a distinct personality. Sofia from Rome is warm and encouraging, loves talking about food, and will absolutely roast you (affectionately) if you butcher the subjunctive. Kenji from Tokyo is more formal but has a dry sense of humor that comes out once you get comfortable.
It's the closest thing to being dropped in a foreign country and forced to figure it out—except you can do it from your couch at 2am in your pajamas.
How It's Made
The architecture is a sophisticated hybrid pipeline designed to maximize both reasoning intelligence and audio fidelity:
Speech-to-Text (Google Cloud) captures your spoken input. We specifically chose a dedicated STT model over a multimodal input because its robustness against non-native accents (users speaking broken Italian) proved superior during testing.
Google Gemini 3 (leveraging the gemini-flash-latest reasoning engine) powers the conversational brain. We utilized Gemini 3's advanced instruction-following capabilities to maintain strict persona guidelines. While Gemini 3 offers native audio modalities, we deliberately chose a text-based reasoning pipeline to maintain granular control over the output before synthesis. This allows the model to handle contextual responses and gentle corrections with higher precision than previous generations.
Google Translate provides a safety net. If you're truly stuck, you can see translations without breaking the immersion.
ElevenLabs Multilingual v2 is the secret sauce for audio. We pipe Gemini 3's text output here because we needed hyper-specific regional dialects (e.g., Roman vs. Milanese) that generic multimodal models cannot yet distinguish perfectly. When Sofia responds, she sounds Roman because Gemini 3 generates the dialect-accurate text, and ElevenLabs handles the cadence.
Backend runs on FastAPI deployed to Cloud Run. We're using Server-Sent Events for streaming so you see responses build in real-time. Frontend is Next.js with Material UI.
The whole thing is wrapped in dark mode with glassmorphism effects and language-specific accent colors. When you switch to Japanese, the UI shifts to cherry blossom pink highlights. Spanish gets warm terracotta. Small touch, but it reinforces the immersion.
Challenges we ran into
Latency is brutal. Speech-to-text → LLM → text-to-speech is a lot of round trips. Early versions had 4-5 second delays between speaking and hearing a response, which completely kills conversational flow. We got it down by parallelizing what we could, implementing streaming at every stage, and being aggressive about caching common responses.
Tutor personalities kept going generic. First attempts at the system prompts produced tutors that all sounded like the same helpful assistant wearing different hats. It took a lot of iteration to make Sofia actually feel Italian—not just in what she says but how she says it. The breakthrough was adding specific opinions, pet peeves, and conversational quirks rather than just demographic descriptors.
Rate limiting almost killed us. At one point we were accidentally hammering the ElevenLabs API during testing and got temporarily blocked. Added proper rate limiting (20 req/min/IP) and graceful degradation so the app doesn't just crash if one service hiccups.
The "correction" problem. How do you correct someone's grammar without being annoying? Too aggressive and it interrupts flow. Too passive and they never learn. We landed on inline corrections that acknowledge what you meant while modeling the proper form: "Ah, you want to go to the market! Voglio andare—I want to go. Let's go together, where should we start?"
Accomplishments that we're proud of
The voices. Seriously, play a clip of our Roman Italian tutor to an actual Italian and watch their eyebrows go up. That moment when the technology disappears and it just feels like talking to a person—we got there.
Also proud of the error handling. Nothing tanks a demo like a crash. We built in fallbacks at every integration point. ElevenLabs down? Fall back to Google TTS. Gemini timing out? Return a cached conversational filler while retrying. The app degrades gracefully instead of exploding.
And honestly? We built this in a day. A functional, polished, actually-useful language learning tool in ~24 hours. The codebase isn't held together with duct tape and prayers (mostly).
What we learned
Streaming changes everything. The perceived performance difference between waiting 3 seconds for a complete response vs. seeing text appear word-by-word is massive, even if total time is similar.
Personality > capability for engagement. Users forgave occasional weird responses when the tutor felt like a character they enjoyed talking to. They didn't forgive boring responses even when technically correct.
Google Cloud's speech recognition is underrated. We expected to fight with transcription accuracy and... didn't really. Even with accented English and attempted foreign phrases, it kept up.
What's next for Language Mirror
Conversation memory. Right now each session is standalone. We want tutors to remember your progress, your weak points, topics you enjoy. "Last time you wanted to practice ordering at restaurants—how did your trip to Barcelona go?"
Pronunciation feedback. We're capturing audio but not analyzing it. The pipeline exists to compare your pronunciation against native speakers and give specific feedback. "Your R's are getting better but watch the double consonants."
More languages, more dialects. Five languages with three dialects each is a start. The system is built to scale—adding a new voice is mostly prompt engineering and ElevenLabs configuration.
Mobile app. Practice during your commute. Practice waiting in line. Language learning happens in stolen moments, and right now we're stuck in a browser.
Scenario mode. Guided conversations for specific situations: ordering coffee, asking for directions, job interviews, first dates. Structured practice for real-world moments.
Built with too much coffee and not enough sleep for the Google Gemini 3 Hackathon.
Built With
- css3
- elevenlabs
- fastapi
- gemini
- gemini3
- git
- github
- google-cloud
- google-speech-to-text-api
- google-translate
- gsap
- html5
- materialui
- nextjs
- python
- react
- typescript
- vercel
- vscode


Log in or sign up for Devpost to join the conversation.