Inspiration
Many endangered languages are learned from elders through sound (tone, rhythm, breath, and place) not from flat text alone. We were inspired by communities who already carry archives in recordings, stories, and everyday speech, and by learners who hit a wall when dictionaries are text-only or scattered across notebooks and phones. We wanted a single place where audio leads, words stay grounded in real voices, and learners, speakers, and moderators can grow the same archive together.
What it does
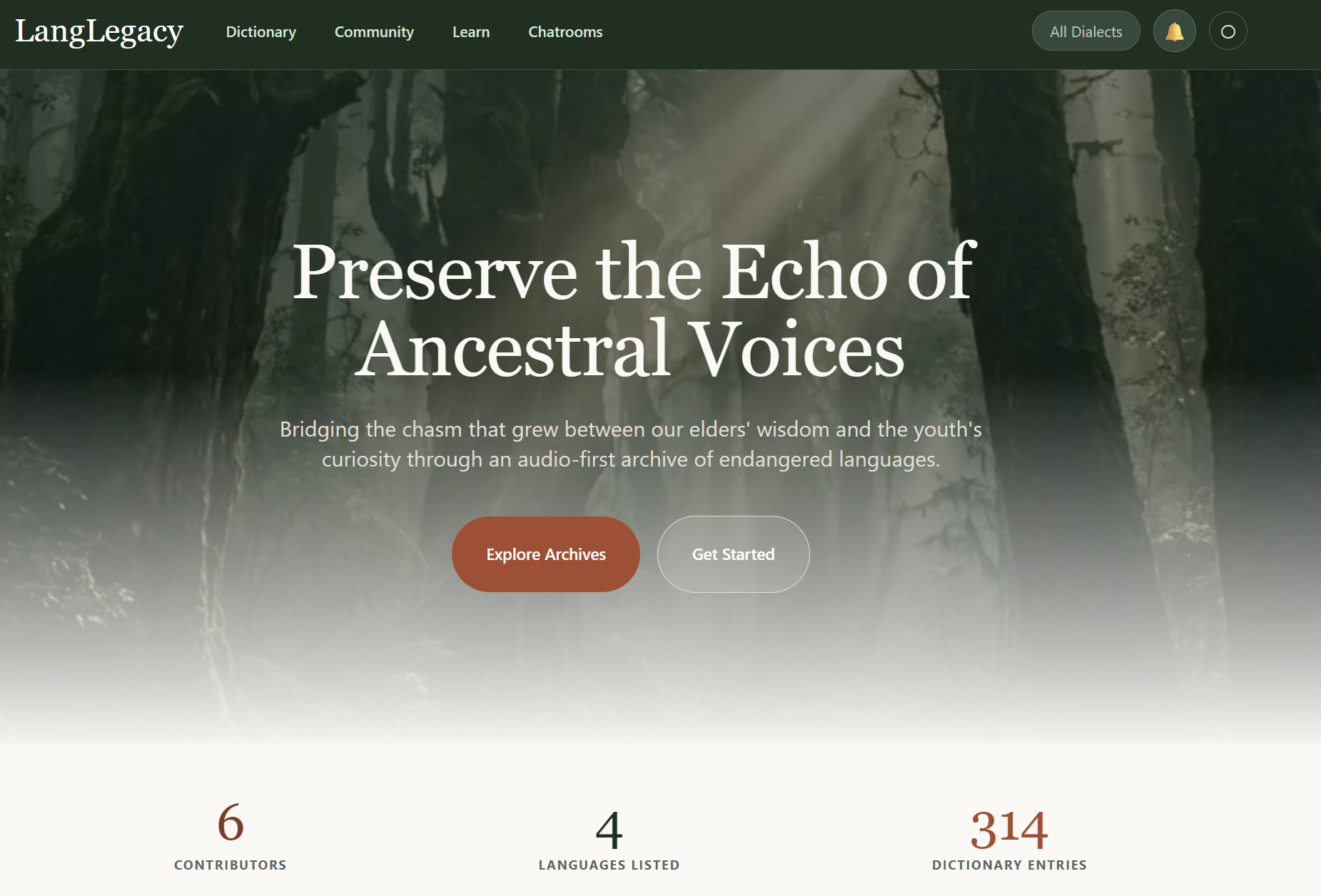
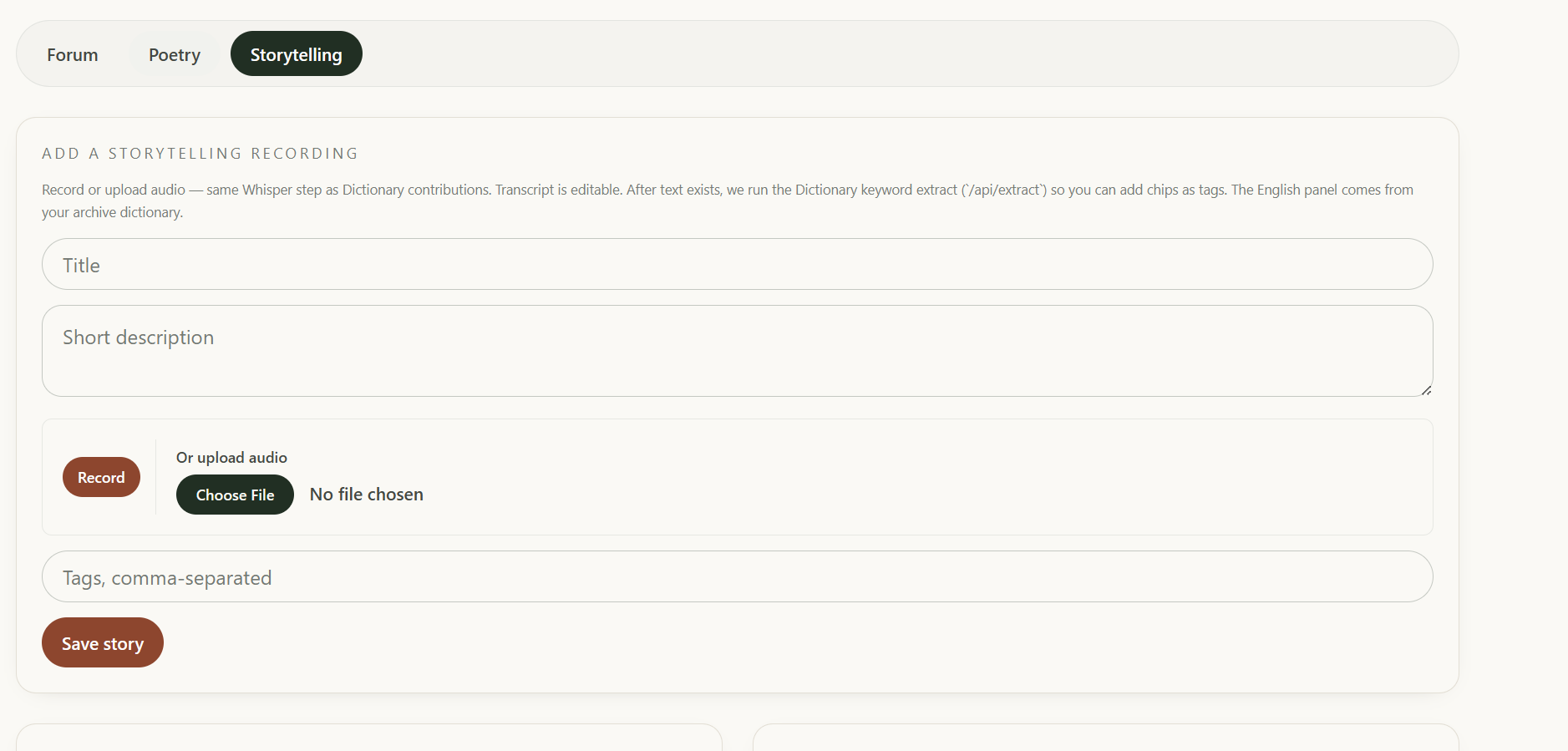
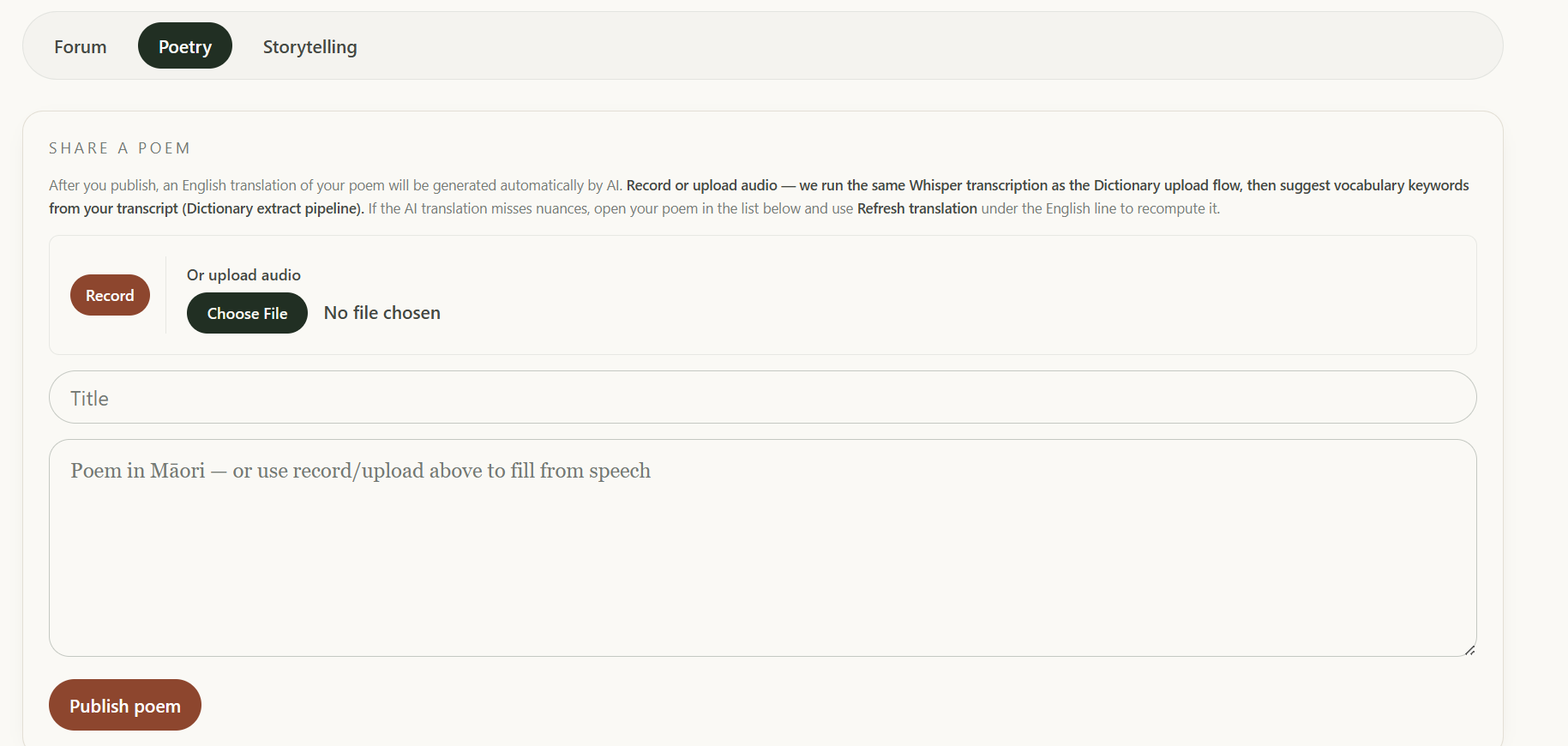
LangLegacy is a living audio dictionary and community hub for endangered languages. Contributors upload recordings of native speakers; the app transcribes them locally using Whisper, extracts vocabulary with IBM watsonx Granite, and builds a searchable dictionary where every entry is anchored to a real voice.
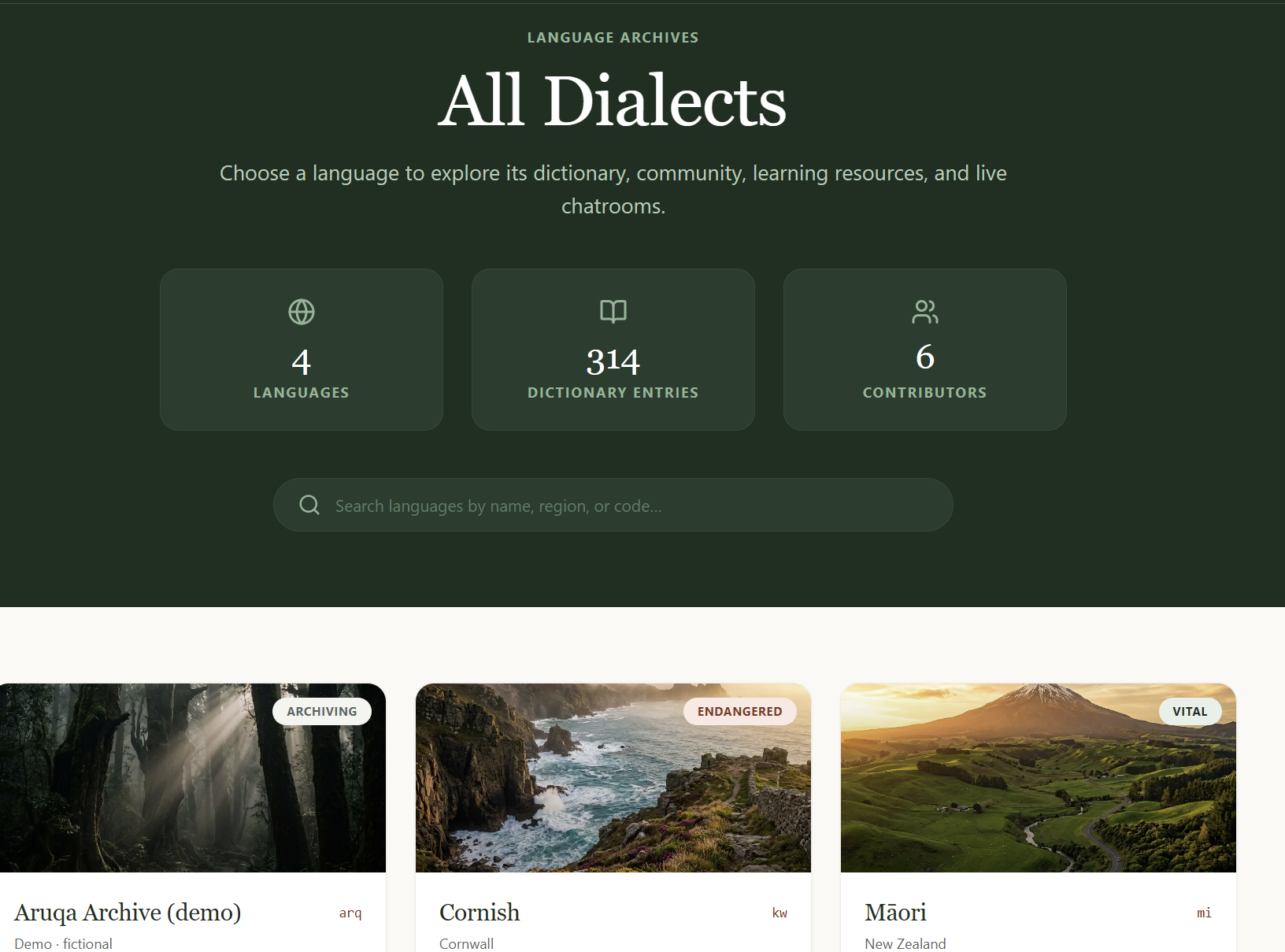
From there, the community takes over. Each language has four tabs:
- Dictionary: searchable entries with audio playback, phonetics, and example sentences. Any user can add an English translation to unlock the Learn tab for that language.
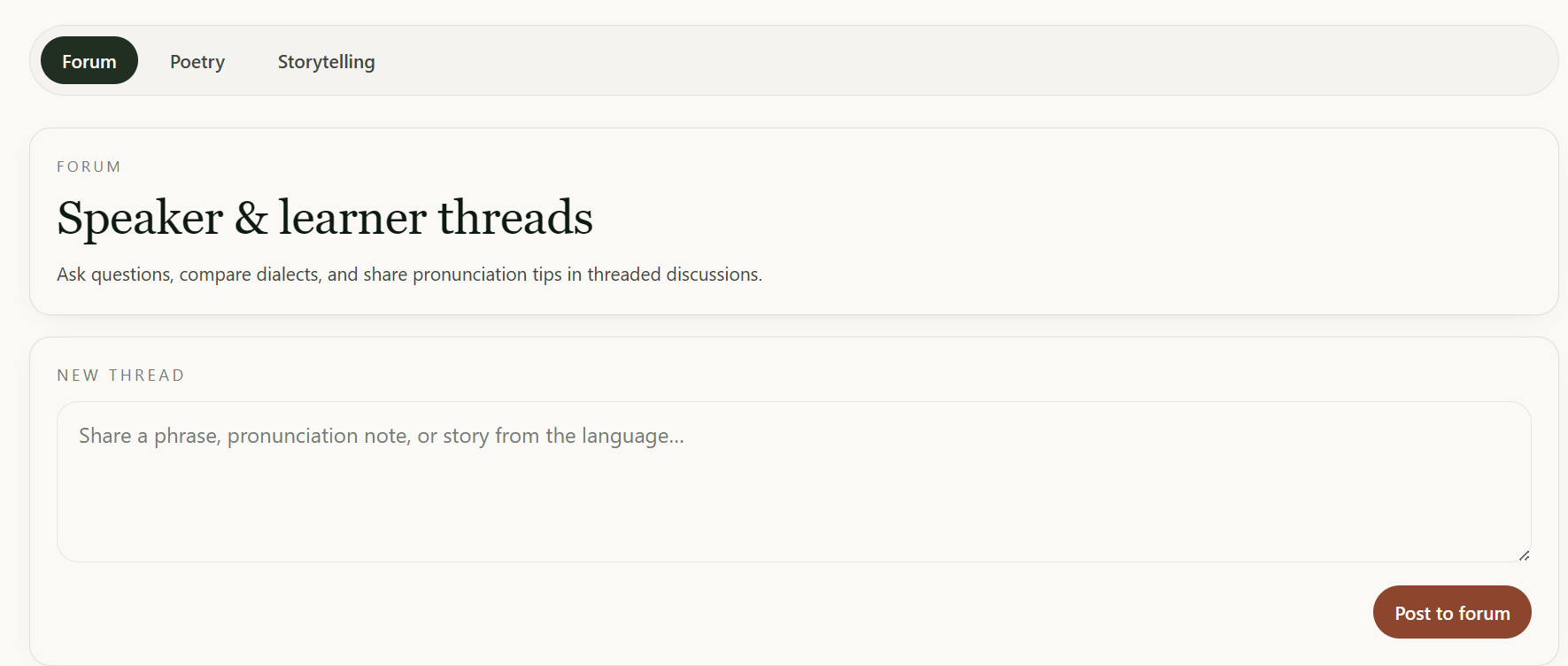
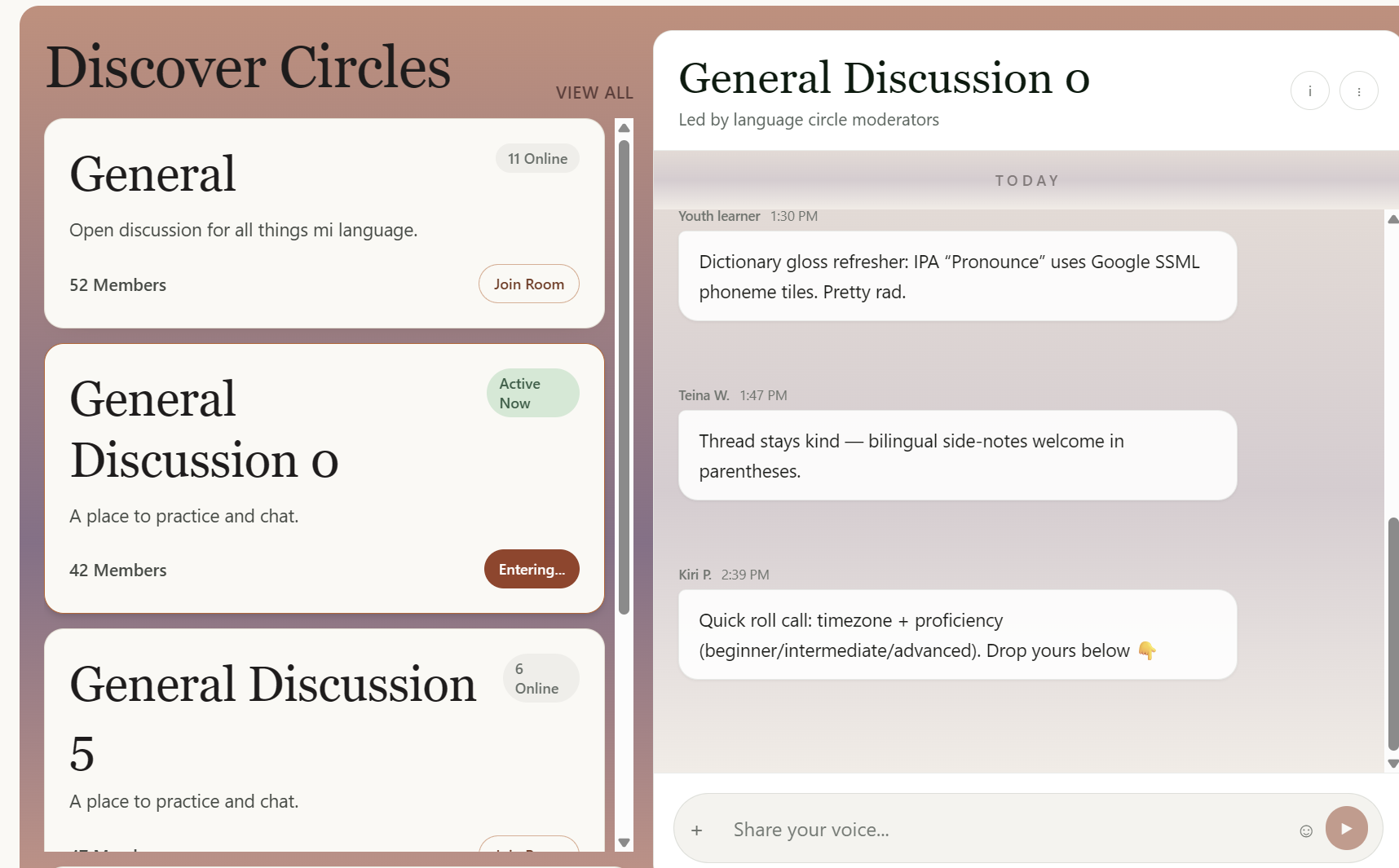
- Community: a hub with four sections: a threaded Forum for discussion, a Poetry gallery where members share poems in their language, a Storytelling library of recorded oral traditions with full transcripts, and Chatrooms for live conversation.
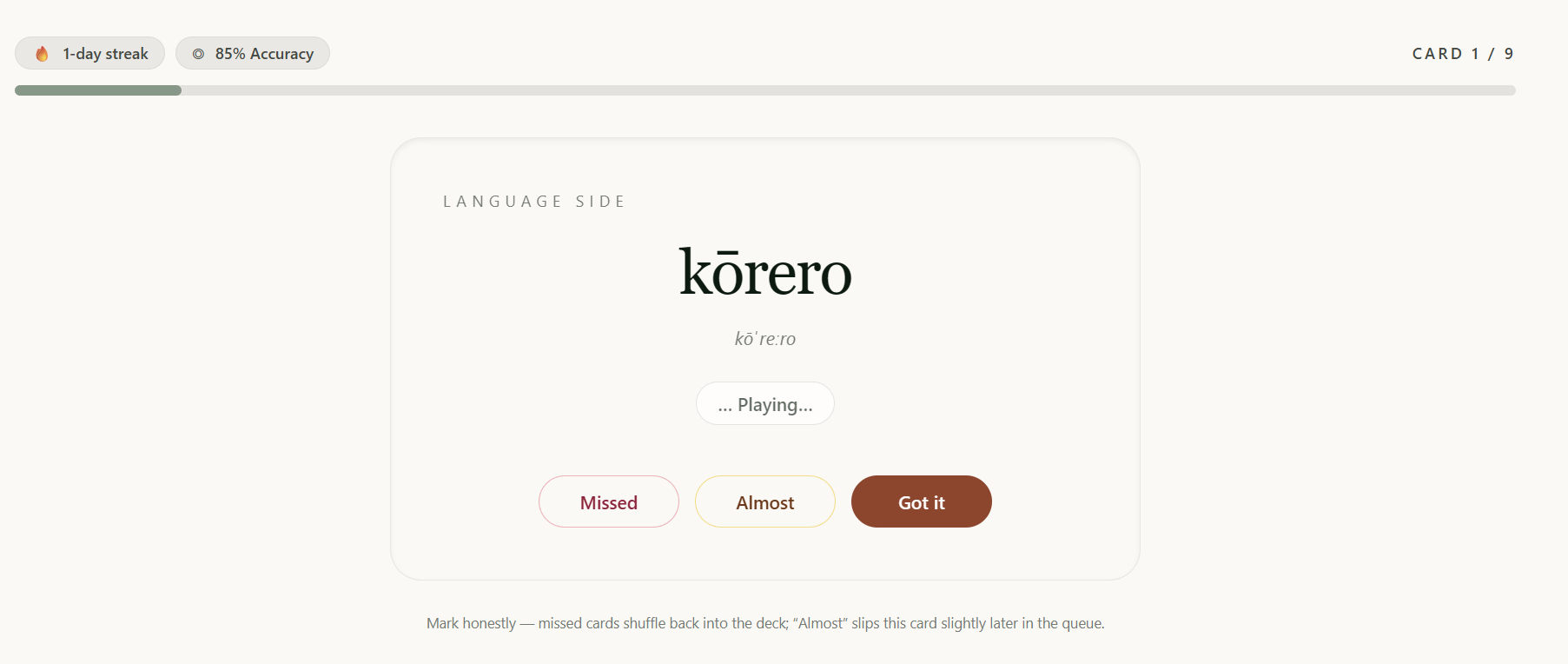
- Learn: a flashcard session built from dictionary entries. Locked in Archive mode until the community has translated enough entries to make it meaningful.
- Moderator: a report queue and language management panel, accessible only to moderators.
Languages with no English translations are marked Archive Only — the audio and native text are preserved and browseable, but the Learn tab stays locked until the community unlocks it together.
How we built it
We built LangLegacy as a Next.js 14 app with TypeScript end-to-end. Core pieces:
- IBM Cloudant for all document storage: languages, entries, posts, poems, stories, messages, reports, and users across ten databases with Mango indexes for efficient querying.
- IBM watsonx (Granite) for vocabulary extraction from transcripts. The model receives the raw transcript and returns structured JSON: word, phonetic, translation, part of speech, and example sentence, without any labeled training data.
- Local Whisper (faster-whisper, CUDA-accelerated) for transcription of contributor audio, running as a FastAPI server alongside the Next.js app with progress feedback in the UI.
- Google Cloud Text-to-Speech for IPA-based pronunciation playback via SSML, giving every dictionary entry a synthesized audio reference when a Google TTS API key is configured.
- Dictionary-driven gloss for poetry and story text tokens swap when they match archive headwords, including multi-word phrases, so the living dictionary enriches longer-form content automatically.
- Server-Sent Events for lightweight live fan-out in chatrooms, merged with optimistic UI so messages don't duplicate when the server echo arrives.
- Cloudinary for audio file storage unsigned upload presets keep the client-side flow simple with no exposed API secrets.
We kept the stack pragmatic: small coercion layers ensure legacy or partial Cloudant rows still render, and every read path degrades gracefully rather than hard-crashing SSR.
Challenges we ran into
- Cloudant / Mango quirks: regex option shapes and index selection behavior required careful alignment between query structure and what the provider actually accepts. We learned to write indexes first, queries second.
- CouchDB write responses return only
{ ok, id, rev }: we had to merge that with the submitted document so clients never received half-formed rows missing their ownbodyfield. - Race conditions in chat: optimistic message rows and SSE echoes arriving simultaneously required explicit deduplication: dropping
temp_*rows when a matching server ID arrived. - Network flakiness to Cloudant:
fetchcan throw before aResponseexists. We learned to degrade read paths (e.g. the language header) instead of propagating uncaught errors into SSR. - Archive mode unlock logic: auto-upgrading a language at ≥50% translation coverage while also allowing moderator override and community contribution required careful ordering of writes to avoid stale coverage counts.
Accomplishments that we're proud of
- A complete end-to-end pipeline from raw audio → Whisper transcript → IBM watsonx vocabulary extraction → searchable dictionary entry with audio playback, built in three days.
- The Archive mode system — the first time we saw Cornish render with its "Archive Only" badge and a locked Learn tab with a live coverage bar, it felt like the right way to handle languages the world is still learning to document.
- Chat working over SSE without a dedicated WebSocket server — just a Next.js API route polling Cloudant and fanning out to connected clients.
- A moderator dashboard that handles reports across five content types (entries, posts, poems, stories, messages) with a single shared report document model.
- The community unlock loop — the idea that a language graduates from Archive to Full when its own speakers and learners collectively add enough translations felt true to what the project is actually about.
What we learned
- The object isn't a database — it's trust. Contributors need clear flows for upload, review, and respectful use of sensitive material. Every design decision around reporting and moderation is a trust decision.
- Glossary ≠ translation. Word-level glossing from a living dictionary teaches structure. Full machine translation is a different product with different expectations — and we deliberately didn't build it.
- Ops is part of the UX. If Cloudant, auth, or streaming hiccups, the UI must fail gracefully. Empty states, fallbacks, and honest errors beat silent breakage every time.
- Real-time is optional; durability isn't. Chat and streams are good for presence, but writes that don't persist feel like bugs. We treated cloud writes as the source of truth and built optimism on top — not the other way around.
What's next for LangLegacy
- Transcript-audio sync: highlighting words in the story transcript as the audio plays, so readers can follow along and build listening comprehension.
- Spaced repetition: replacing the basic flashcard deck with a proper SRS algorithm so the Learn tab adapts to each learner's weak spots.
- Community translation review: a lightweight peer review flow where proposed translations are confirmed by two or more speakers before counting toward coverage, so the unlock threshold is meaningful.
- Dialect tagging: entries and recordings tagged by region so a learner can hear the same word spoken in multiple dialects and see how it varies.
- Mobile-first recording: a progressive web app mode optimized for elders recording on phones in low-connectivity environments, with offline queuing and background upload when signal returns.
- Partnerships with language archives: bulk ingestion from existing university and community audio archives (Mozilla Common Voice, AILLA, ELAR) to seed new languages without starting from zero.
Built With
- cloud
- cloudinary
- fastapi
- faster-whisper
- ibm-cloudant
- ibm-watsonx.ai-(granite)
- next.js-14
- python
- tailwind-css
- text-to-speech
- typescript
- whisper



Log in or sign up for Devpost to join the conversation.