-
-
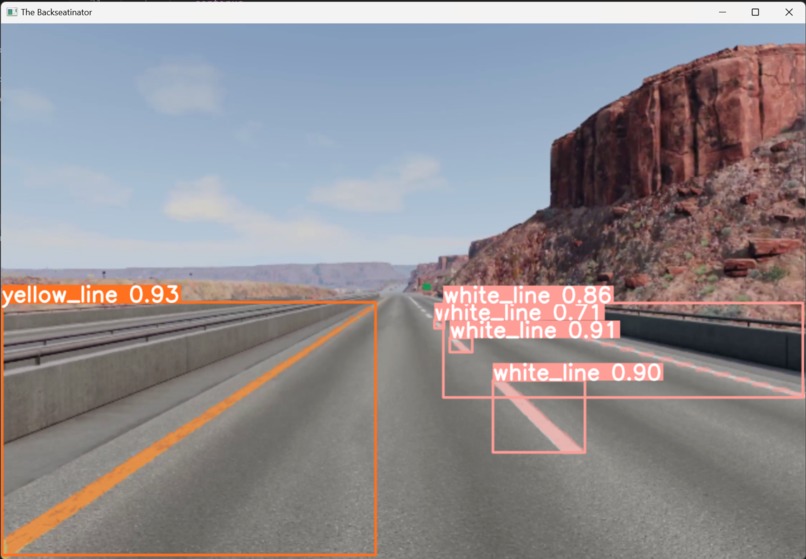
Processed Real-Time Video Clip Screenshot

Inspiration
The project drew inspiration from the need for robust real-time lane detection systems to enhance road safety and assist autonomous vehicles. It aimed to utilize deep learning models to accurately recognize and highlight lane markings in live video streams.
What it does
The project utilizes a pre-trained deep learning model to perform real-time lane detection on video feeds. Leveraging advanced computer vision techniques in opencv, it accurately identifies and outlines lanes within the video frames, providing a clear visual representation of the road structure from the first person driving view.
How we built it
The system was built using a combination of computer vision libraries in python and a pre-trained deep learning model specifically designed for lane detection. By integrating these tools, the project processed live video streams, applying the model's predictions to recognize and box lanes in real time.
Challenges we ran into
Challenges included optimizing the model for real-time performance, ensuring accurate lane identification under varying environmental conditions (e.g., different lighting and weather), and integrating the system seamlessly with live video feeds. I found things hard because I couldn't make my image processing algorithms handle all potential cases when it comes to lane detection in opencv. Additionally, we had live video streaming (realtime segmentation) working yesterday, but for some reason now it doesn't want to work.
Accomplishments that we're proud of
We successfully achieved real-time lane recognition and outlining in live video streams, contributing to the development of a robust system for road analysis. Overcoming the technical hurdles in learning a new language overnight on my side and achieving accurate, timely lane detection through training the deep learning model with Roboflow was a significant accomplishment.
What we learned
Throughout the project, we gained insights into optimizing deep learning models for real-time applications, understanding the complexities of environmental factors on model performance, and fine-tuning the system for improved accuracy and speed.
What's next for Lane Detection
Given more time, we would train the model to recognize more objects and be more interactive. For example, we will run our trained model that would classify people and cars driving towards or away from us.
Camera sensor calibration could be set up to handle distortions, which would become a great help to handle manually coded computer vision algorithms. I want to implement checkerboard for better accuracy in measurement so that we can test depth of objects and reconstruct 3D object detection.
This could be further developed into Augmented Reality applications where we can overlay virtual objects accurately onto real world scenes.

Log in or sign up for Devpost to join the conversation.