-

-

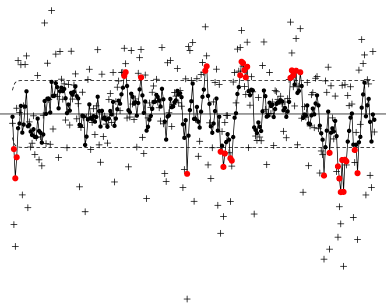
long-term mood over time: red points outside the control boundaries are extremes (high is positive, low is negative)

Inspiration
Half of our team has or is currently experiencing mental illness.
One of the best ways to recover from a mental illness such as Depression, PTSD, or Anxiety Disorder is to identify your triggers: the things in your daily life that bring up the negative feelings associated with your mental illness.
But his is extremely difficult!
Identifying triggers requires a patient to track everything that happens to them 24/7 as well as how they're feeling. Not only is this exhausting, impractical, and upsetting to sufferers, but it is also unreliable because in order to track your daily life, you need to already know what's relevant and what you're supposed to be tracking. This thinking is backwards, so we wanted to make an app that could monitor your mental health and identify possible triggers for you with minimal time, effort, and knowledge.
When you're suffering from a mental health condition that causes crippling anxiety, emotional flashbacks, or even triggers suicidal thoughts, all you want is to regain some control. This is where My MindSweeper comes in.
What It Does
My MindSweeper is a primarily mobile app that lets users sync their Facebook Messenger data and SMS Text Messages with our servers, allowing us to programmatically monitor mental health and identify the user's most relevant triggers. This gives users the power to take more control over their lives and conquer their mental illness.
How It Works
Server and Web App
The server is hosted on AWS and all data is managed by Google OAuth for the security of sensitive user data. From the web app, users have the option to log into Google to upload their Facebook Messenger data to our server. This data is obtained by downloading a data dump from Facebook, available to any user of the platform. This optional step serves as the initial upload of user messages that can almost immediately inform users of their mental health patterns and possible triggers upon downloading the mobile app and again syncing with their secure Google account.
Mobile App
The mobile app is a native Android app that uses the same Google OAuth security as the server and web app to make sure sensitive user data remains private. The app monitors the user's SMS text messages, sending them to the server on a regular basis to give users real-time updates as their mental health fluctuates and possible triggers are identified. Graphs and trigger data are displayed in-app as the server completes the necessary computations and pushes data back to the user's mobile phone.
Data Processing
Facebook Messenger data is downloaded as HTML files, so we first used the Python package BeautifulSoup to scrape this data, extracting the message text as well as meta-data such as other individuals in the conversation and the timing of each message. These messages were stored in the same JSON format as the SMS messages and both were fed into a common Python script that compiled this data into 20-minute increment "clumps". Two sets of clumps were compiled: the first contained set of clumps contained all messages from a single thread within each 20-minute timespan, and the other only those sent by the user. This allowed for much simpler processing in later steps.
Natural Language Processing
Each message clump is analyzed using NLP algorithms to determine an "at risk" score and extract relevant keywords and concepts: potential triggers. To compute the scores, we first run each clump through the Natural Language Understanding module of IBM Watson to obtain the sentiment and emotions contained in each. Then from here, we used a statistical technique called Linear Contrast, a method of combining variables to accurately measure the effects of the components relative to each other. The resulting equation was used on every clump to compute the "at risk" score. Stop words (filler words such as "the", "and", or "then") were filtered from the keywords to more accurately identify triggers. The final risk score was paired with its time and features (e.g. keywords and concepts) extracted by the IBM Watson API in preparation for later statistical analysis.
Statistics
We used Statistical Process Control (SPC) on our risk score analysis. Due to the law of large numbers we would expect in the long run (over the course of 30,000 messages) the data to tend to a normal distribution for people who are not prone to mental illness. The idea behind SPC is that there is normal variation around the expected process mean, as long as there is this normal process variation around the mean the process is considered to be in control. When those with mental illness have an episode and are exposed to their triggers, that effect will appear in their social interactions and everyday messages with other people, but aside from the triggers their process would fall in normal ranges.
SPC uses a series of quality control charts to help ensure the quality of a process and is designed to detect variations in the overall process. If the human social interaction model formulated above gets out of control (beyond the normal process variation) then this critical point would indicate someone is having an episode. This is more extreme than just someone having a bad day, because that is accounted for in normal process variation. SPC charts are a commonly used and proved statistical tool, normally used in manufacturing, but we were able to adapt the same principles to mental health.
There were five types of graphs we were able to create based on the data. One of the most important ones was the OC Chart, which is used to measure the probability of a type II error when an out of control point is detected. This chart shows that our process is robust, meaning that our predictions are secure and verified against abnormal data.
The X-Bar Chart is used to measure the variations in process mean. Each conversation is considered a sample, and an individual message is a data point within the sample. X-Bar Chart is good for short run predictions, so it can be used to measure immediate problems more accurately.
The S Chart is used to measure standard deviation of processes. While it is normally used to verify the accuracy of the X-Bar Chart, we were able to use it to detect when there is a high variability in the topic of conversation, like sudden short lived drops in mental health score. Both the charts are useful for measuring short term risk and the most recent data.
Two more charts, the Cumulative Sum Average Chart and EWMA Chart are for long term data; they utilize all of the 30,000 messages. The Cumulative Sum Chart tracks process variation overtime and is good for tracking larger prevalent episodes that last for long periods of time. The EWMA Chart is meant for long term tracking of a process. It shows moving limits, and measures shifts in variability over time. It also plots the major influential points that pull on the direction of the graph. This is good for analyzing the influential points and comparing how they affect the process overtime.
We then took all the out of control points that crossed the control limits and analyzed the principle components of the messages. We took these, filtered points and we used them to find the key triggers.
Challenges We Had
The largest obstacle we faced was data collection and management. Since we are not researchers, we do not have access to the wealth of data often required to build advanced models for textual and statistical analyses. We got around this by downloading a dump of one of our team member's Facebook Messenger data, which goes back half a decade and contains almost 30,000 messages. Since they had a history of mental illness, they became our primary testing resource for not only the data itself, but also as a validation that our results were accurate.
However, with this wealth of data came more problems. We had 30,000 messages, and a limit of 30,000 API requests to IBM Watson. To solve this, we clumped the messages into groups, which also improved accuracy. We also did very small sample tests throughout the hackathon and only ran the full data set a handful of times to save on our API calls. We actually did end up hitting the limit this weekend, so shared accounts and credentials between team members to allow us to perform almost 50,000 total API calls.
Another issue that arose was the fact that many of the components of our app relied on each other in a linear fashion. The statistical portion of the hack could not begin until the NLP portion of the hack was complete, which could not be attempted until the Facebook Messenger scraper was working, etc. This meant we had to communicate constantly and switch off working, coordinating sleep and coding hours to make sure that everyone completed their portion of the app in order, as quickly as possible, and it all worked together seamlessly at the end.
Things We Learned
Technically, we learned a variety of new statistical tools such as Linear Contrast, but more importantly, we learned a lot about ourselves and our mental health. The data revealed many trends that we were aware of, but also many that we weren't, allowing us to better monitor and manage our mental illnesses.








Log in or sign up for Devpost to join the conversation.