-
-
Thumbnail
LAME: Legacy Architecture Modernization Engine
💡 What Inspired Us
The biggest bottleneck in enterprise-grade AI isn't the reasoning capability of the models; it's the context. Big tech companies (like Qualcomm, Google, and Apple) are sitting on millions of lines of legacy code, intertwined with decades of undocumented dependencies.
When developers try to modernize these monoliths, they run into the "Global vs. Local Context" trap. An AI agent looking at a single 500-line file might write a perfect refactor, but it doesn't realize it just broke a telemetry service 2,000 files away. We were inspired by the Nozomio Labs track to solve this exact problem. We realized that with the Nia API, we didn't just have a search tool—we had the ultimate "institutional memory" engine. We wanted to build an autonomous swarm that could migrate legacy systems safely because it knew everything about the codebase.
⚙️ How We Built It
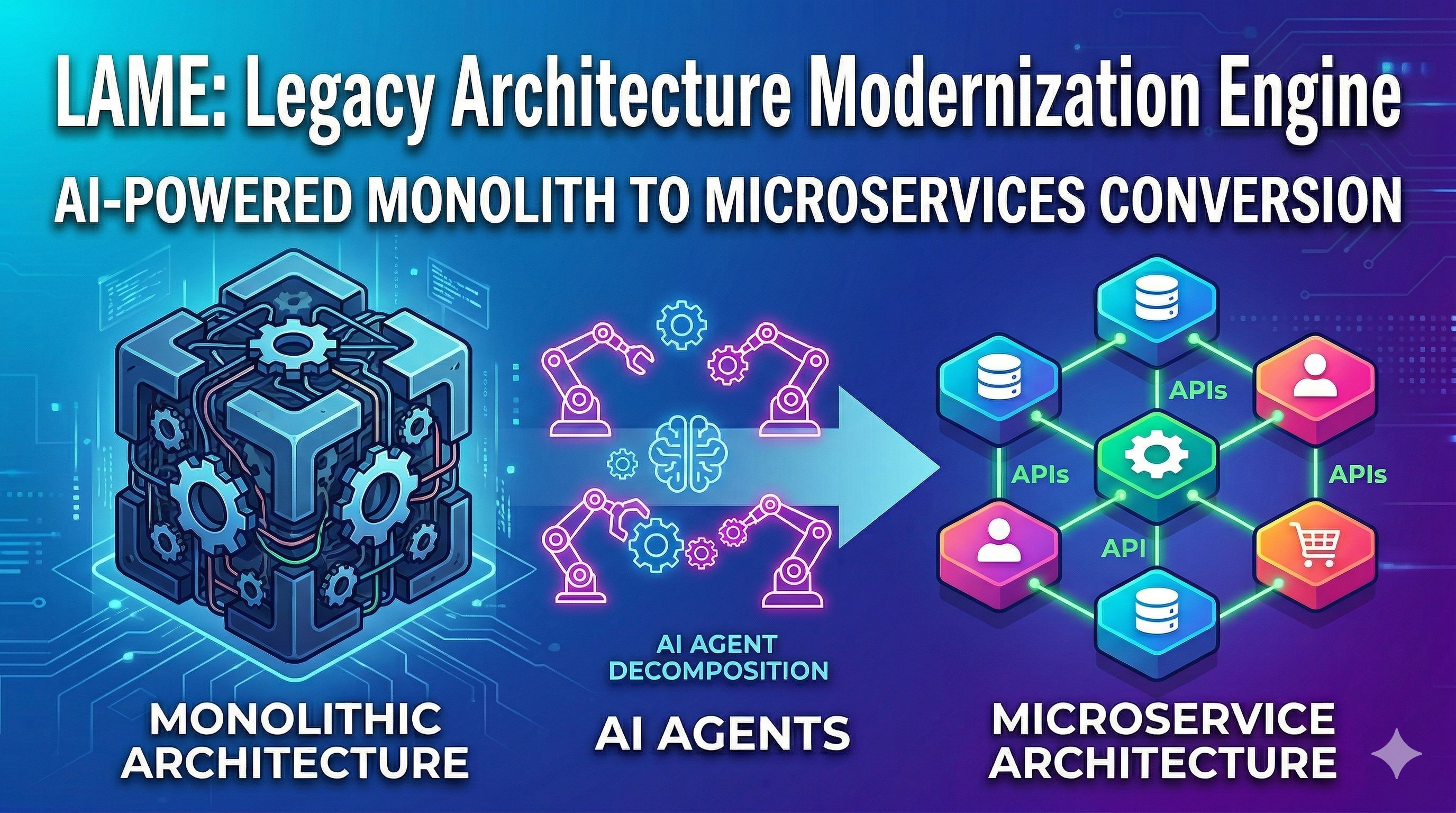
We engineered LAME as a "System-of-Systems"—a hierarchical, multi-agent architecture divided into three distinct, decoupled modules:
- The Core SDK (NiaClient): A robust wrapper around the Nia API that handles deep indexing, semantic search, and global codebase tree retrieval.
- The Architect Agent: The planner. It scans the repository using Nia, builds a massive dependency graph, and uses an LLM to generate a strict, topologically sorted
RefactorPlanstored in JSON. - The Worker Orchestrator: The execution engine. It parses the JSON plan, dispatches smaller "Worker Agents" to write the code diffs, and then immediately runs a "Validator Agent" to verify the changes against global context.
We relied heavily on Pydantic to enforce a rigid data contract between the agents. To quantify the search optimization our architecture achieved using Nia, consider the dependency graph $G = (V, E)$, where $V$ represents the set of all files and $E$ represents the cross-file dependencies.
In a traditional grep-based refactoring loop, verifying a single function change requires scanning the entire repository, leading to a time complexity of:
$$T_{local}(V) = O(|V|^2)$$
By pre-indexing the repository with the Nia API, our Validator Agent reduces the dependency conflict check to targeted semantic retrieval, fundamentally altering the validation time complexity to near constant time per symbol:
$$T_{nia}(V) \approx O(1) \text{ per node retrieval}$$
This meant our agents could validate massive architectural changes in seconds rather than minutes.
🚧 Challenges We Faced
Our biggest hurdle was parallel development. In a 48-hour sprint, we couldn't wait for Person A to finish the Nia API wrapper before Person C started the Worker Agent.
We solved this by establishing our Pydantic JSON contract at Hour 1. We built a MockNiaClient that returned deterministic dummy data, allowing the Orchestrator team to build and test the entire topological sort and execution loop in complete isolation. When we finally merged our branches at 3:00 AM, the integration was almost flawless because the data boundaries were perfectly respected.
Another significant challenge was LLM Hallucination during refactoring. Early on, the Worker Agent would invent dependencies that didn't exist. We countered this by weaponizing Nia as a "Safety Net." Before any code was committed, the Validator Agent took the LLM's output and cross-referenced the newly generated symbols against Nia's global index. If it found an orphaned reference, it rolled the step back.
🧠 What We Learned
- Agents need constraints, not just freedom: The most powerful part of LAME isn't the code it writes; it's the code the Validator Agent refuses to write. Structuring multi-agent systems as a series of checks and balances (Architect -> Worker -> Validator) yields vastly more reliable results than a single "god agent."
- Data Contracts are magic: We learned firsthand that defining strict schemas (like our
RefactorPlanJSON) is the ultimate hackathon cheat code for team velocity. - Search is the foundation of autonomy: The Nia API proved that when an agent can instantaneously recall the exact commit history, technical specs, and Slack discussions behind a piece of legacy code, "technical debt" becomes a solvable engineering problem rather than a permanent nightmare.
Built With
- nia
- python

Log in or sign up for Devpost to join the conversation.