-
-

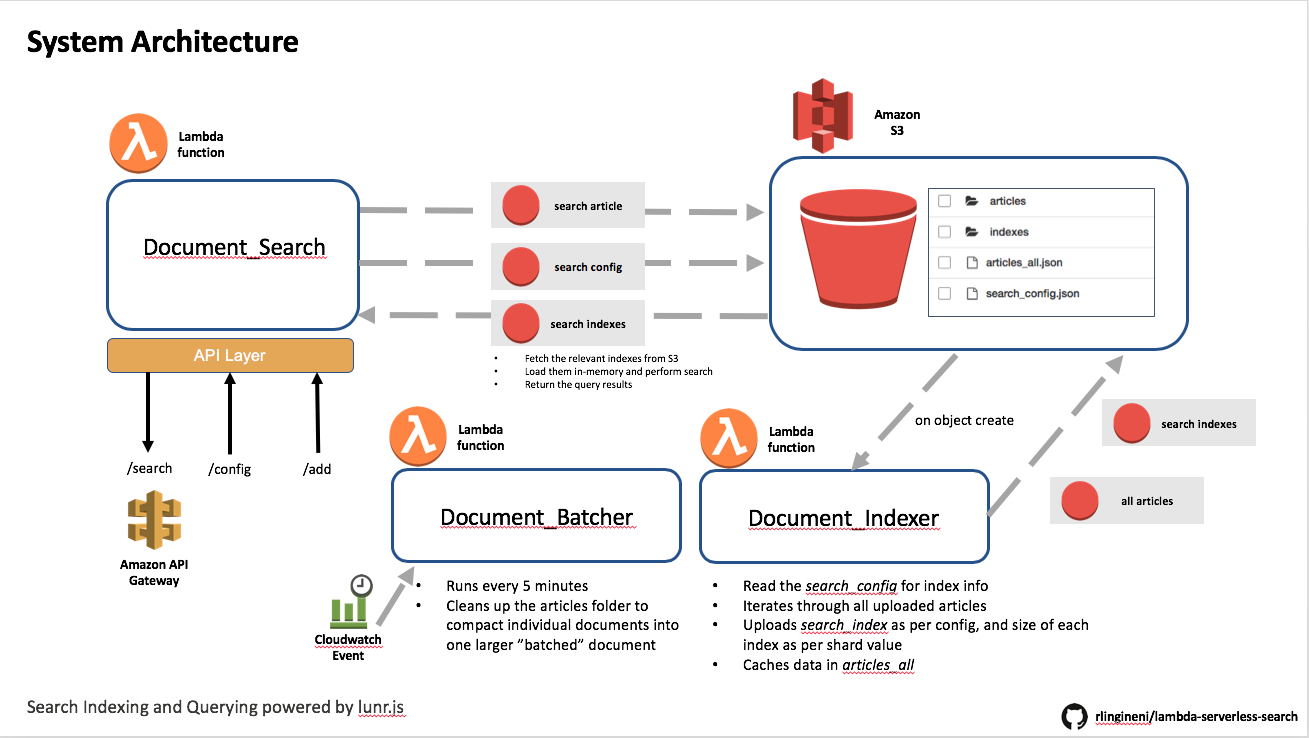
Architecture
-
Graph on how long after upload it takes to see a document
-

Querying Latency Metric

Lambda Serverless Search
I love elasticsearch. I love serverless functions. But I love serverless functions more because they're cheaper to run. The purpose of this project is to allow the benefits of free text searching but work and scale at the most minimal cost.
The search algorithm powering the system is lunrjs.
Limitations
Remember, this is a poorman's elastic search.
- Great for exposing search for sets of new data and existing data
- You only get the index id, not the entire document
- Use as a lite api before migrating to a full scale search solution
- More documents can mean slower performance - how much? Below I've noted my performance observations
- AWS Lambda Memory requirements might need to be updated as per dataset
- This is not a database, it is a search service. You will get results with the reference id only, not the entire document.
AWS Components
- S3
- Lambda (256mb)
- API Gateway
Design

Getting Started
You may head over to the Serverless Application Repository and deploy the service.
You will have to provide two parameters when you deploy:
TargetBucket - The Name of S3 Bucket that should be created, this is where all the documents will sit
Note: remember the S3 bucket naming conventions, only lowercase and alphanumberic
InternalAPIKey - This API Key is a secret string. Do not share this key with anyone, it will allow you to change your index configuration
You may test the API in postman. Be sure to update the BaseURL. Read below for route docs and design.

API Routes
You may view the routes and docs in the Github Readme
Challenges I Ran Into
- Minimizing data loss was a priority. I didn't want to index every article again, but I also didn't want any articles to be lost. So this cost me in indexing speed. Perhaps a stream or queue would be better for next time.
- Indexing and building a large singular index was no good. I had to "shard" and build smaller indexes, that would allow me to retrieve an object from S3 much faster and query faster
- Launching things in parallel consumed more memory, but at times, offered large performance gains that proved helpful
Things I learned
- Searches over 10 seconds are not acceptable
- The Lunrjs data structure isn't necessarily designed for the server, so it needs work
- AWS SAM CLI was very convenient to test locally and deploy
- Milliseconds matter in search. Even a one-second optimization feels like light years faster. I had to really dig and find small places to make optimizations
- AWS Serverless Repo is convenient when trying to share information
- Network latency is non-negotiable. I read Algolia keeps their servers close to the data. Unfortunately, I didn't find a good way to speed this up -Writing a scalability test and understanding how the service fared over time was helpful information to understand the scenarios and places to optimize
Performance
Here are some graphs on performance that I have done. It's not going to win any races, or even come close to algolia or elasticsearch. The real killer is network latency which is a non-negotiable ~2s depending on the index size. There might be a better way to query it with Athena that might speed things along.
DocumentSearchFunction:
- All search indexes are loaded in parallel to improve concurrency
- The higher the memory for a Lambda function, the more the compute power, hence faster index searching. (you can see up to 75% increase in speed), just adjust the slider.
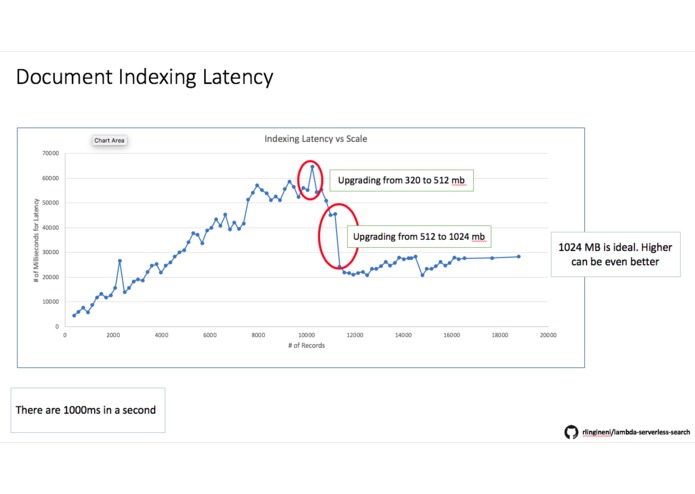
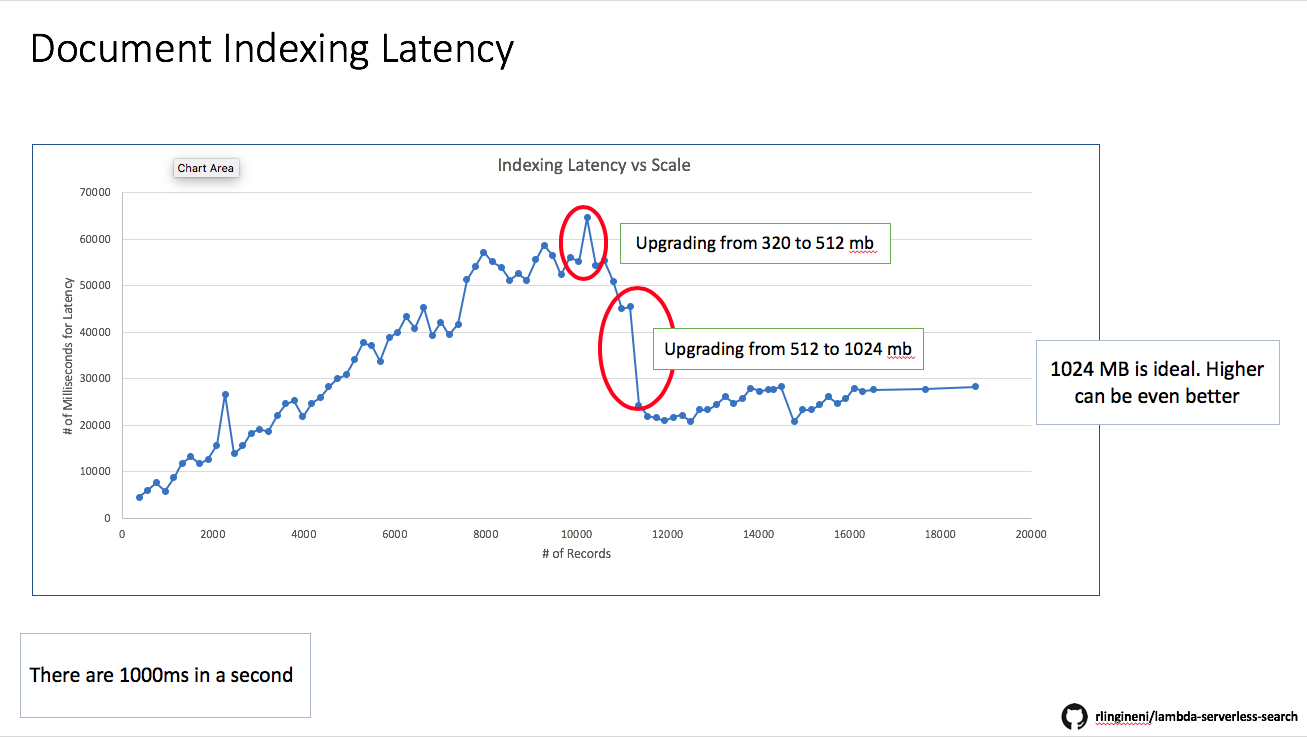
DocumentIndexingFunction:
- The lower the number of individual articles, the faster the indexing time
- You may see my
scale testfolder in the code above. It checks how long it takes to see a record appear in the results after it's uploaded. Latency of indexing operations degrades to about 30X over the course of 12K records. - Bulk uploads tend to decrease the amount of time
- The higher the memory for a Lambda function, the more the compute power, hence faster index building
Next Steps, Optimizations and Future
- Add pagination for large sets of results
- Optimize lunrjs to allow for index merging and cross index searching
- Upload Index directly to the Lambda Function (this would radically improve performance)
- Update to get all S3 Articles and Content via AWS Athena
- Utilize stream and SQS to perform indexing on only necessary documents
- Use Cloudfront with S3 to cache the index document
- Add Cache to keep track of most popular results in order to dynamically perform result boosts
Built With
- amazon-web-services
- aws-sam
- cloudwatch
- javascript
- lambda
- lunrjs
- node.js
- s3
- serverless
- serverless-repo


Log in or sign up for Devpost to join the conversation.