-
-

-
-
Lambdas
-
-

-


Inspiration
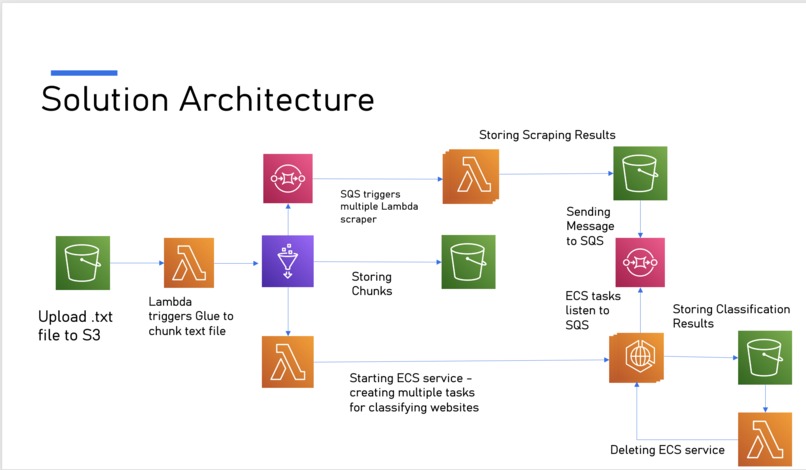
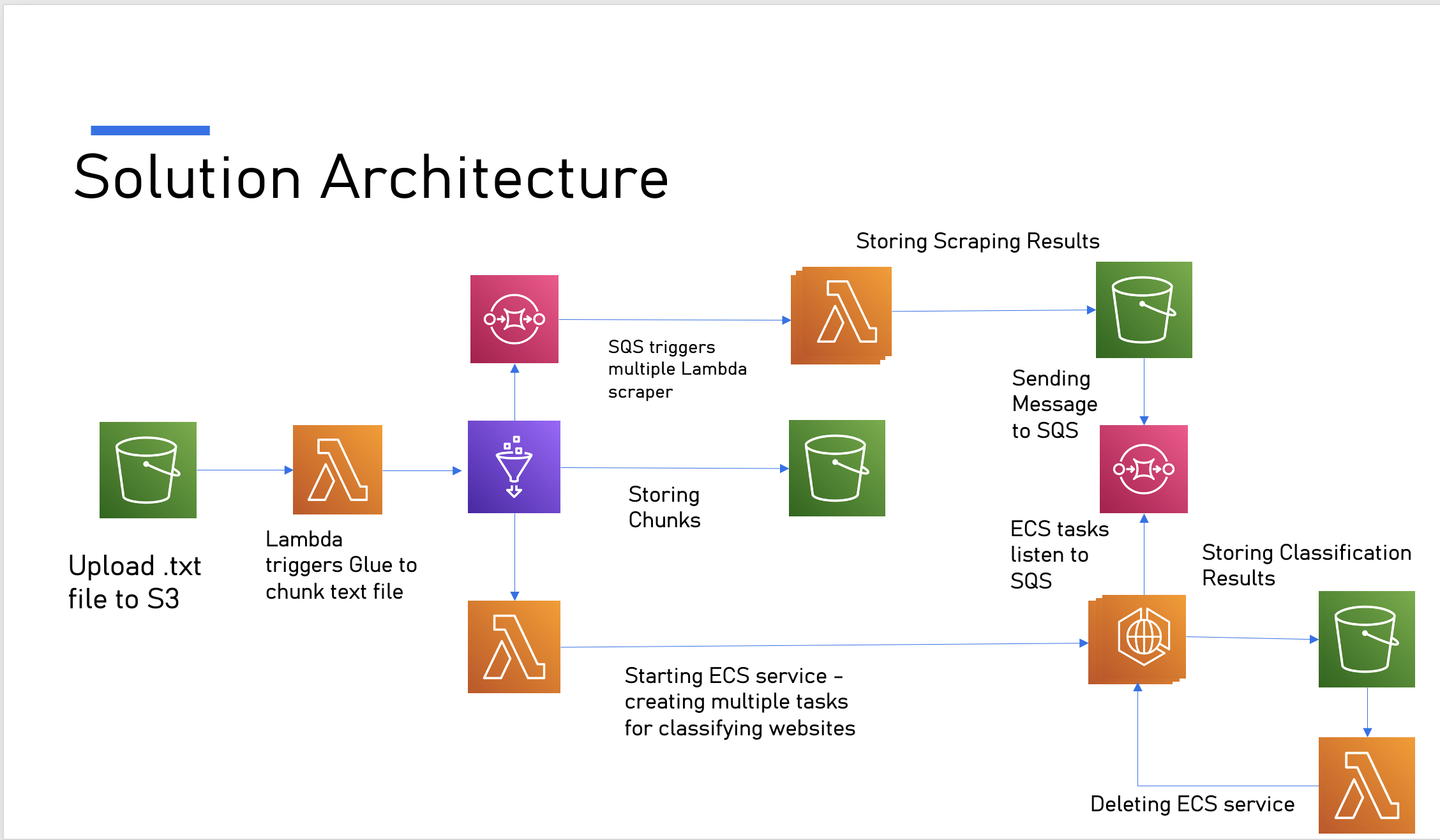
I built Lambda Everywhere to show that AWS Lambda can be more than simple event handlers — it can orchestrate, execute, and automate an entire scalable pipeline for large-scale website scraping and classification. Organizations need to monitor millions of websites for competitive intelligence, compliance, and insights, but running that at scale with traditional servers is costly and operationally heavy. My goal was to prove that with a serverless, event-driven design, even this complex workflow can run efficiently and cost-effectively.
What it does
Lambda Everywhere fully automates website scraping and classification using AWS Lambda, Glue, SQS, ECS Fargate, and S3. A single file upload triggers chunking, scraping, classification, and automatic cleanup — all serverlessly and massively scalable.
How we built it
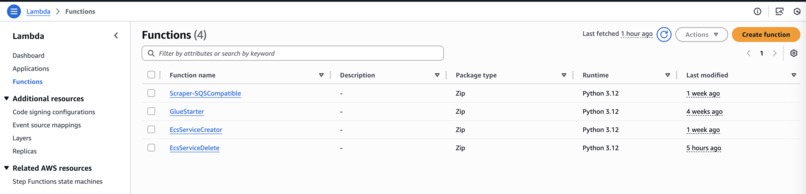
I combined multiple AWS services to build the pipeline:
- Glue chunks huge input files and sends messages to SQS.
- Lambda functions scrape websites in parallel, respecting
robots.txtusingrequestsandBeautifulSoup. - ECS Fargate tasks run containerized workers that classify the scraped content using a Hugging Face zero-shot model.
- SQS queues coordinate scraping and classification steps.
- Lambda lifecycle functions start and stop ECS tasks automatically.
Challenges we ran into
One of the biggest challenges was finding the right architecture for large-scale scraping and classification. I tested multiple architectures — including using EventBridge to start tasks — but found that having Lambda trigger ECS directly gave me much better control over scaling, timing, and concurrency. Another key challenge was designing and refining the classification worker (worker.py) so it could continuously poll the SQS queue, process chunks efficiently, run Hugging Face zero-shot models at scale, and handle failures gracefully. Balancing cost, performance, and reliability made this one of the most rewarding parts of the project.
Accomplishments that we're proud of
I’m proud that I designed a fully serverless pipeline that scales horizontally and can handle millions of websites efficiently, while keeping it cost-effective, modular, and easy to extend.
What we learned
I deepened my knowledge of serverless orchestration and coordinating different AWS services for large-scale data processing. I learned how to balance performance, cost, and design trade-offs for real-world scraping workloads.
What's next for Lambda Everywhere
I’d love to extend this with Selenium inside container images for JavaScript-heavy websites, explore using AWS Bedrock for managed classification, and add Infrastructure as Code with CDK or Terraform to make deploying the pipeline even easier.
Built With
- amazon-web-services
- docker
- huggingface
- lambda
- python
- s3
- sam
- sqs


Log in or sign up for Devpost to join the conversation.