-
-
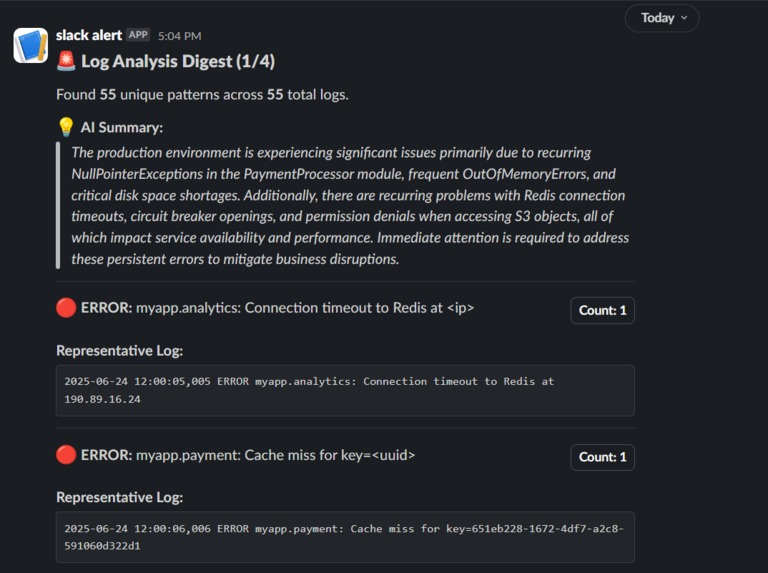
Example of slack alert
-
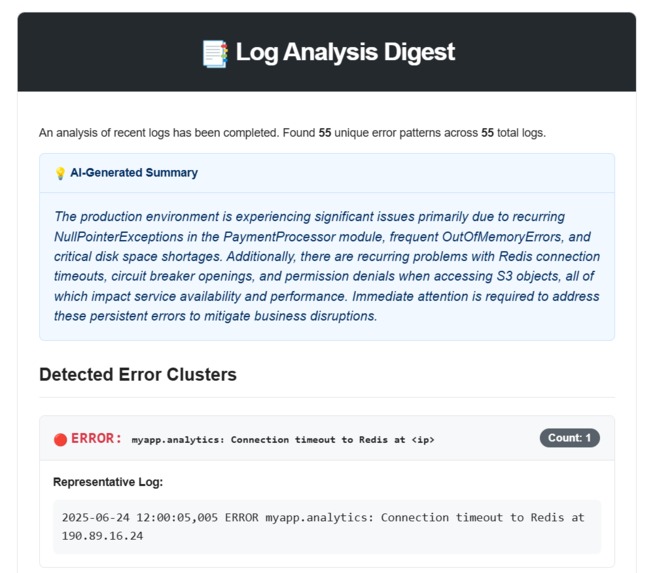
Example of email alert
-
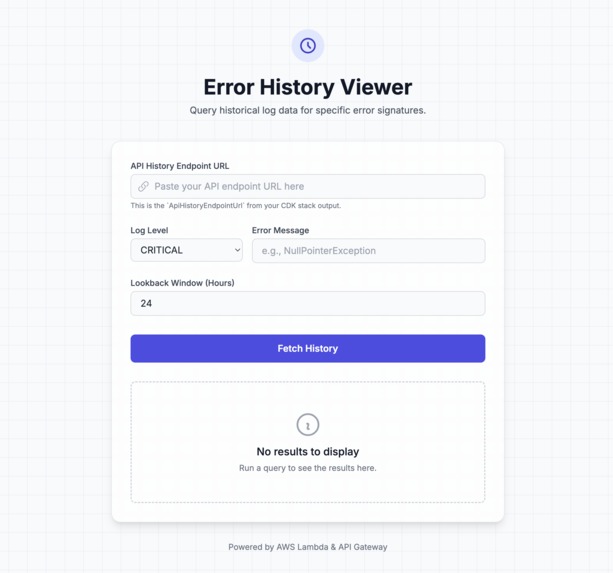
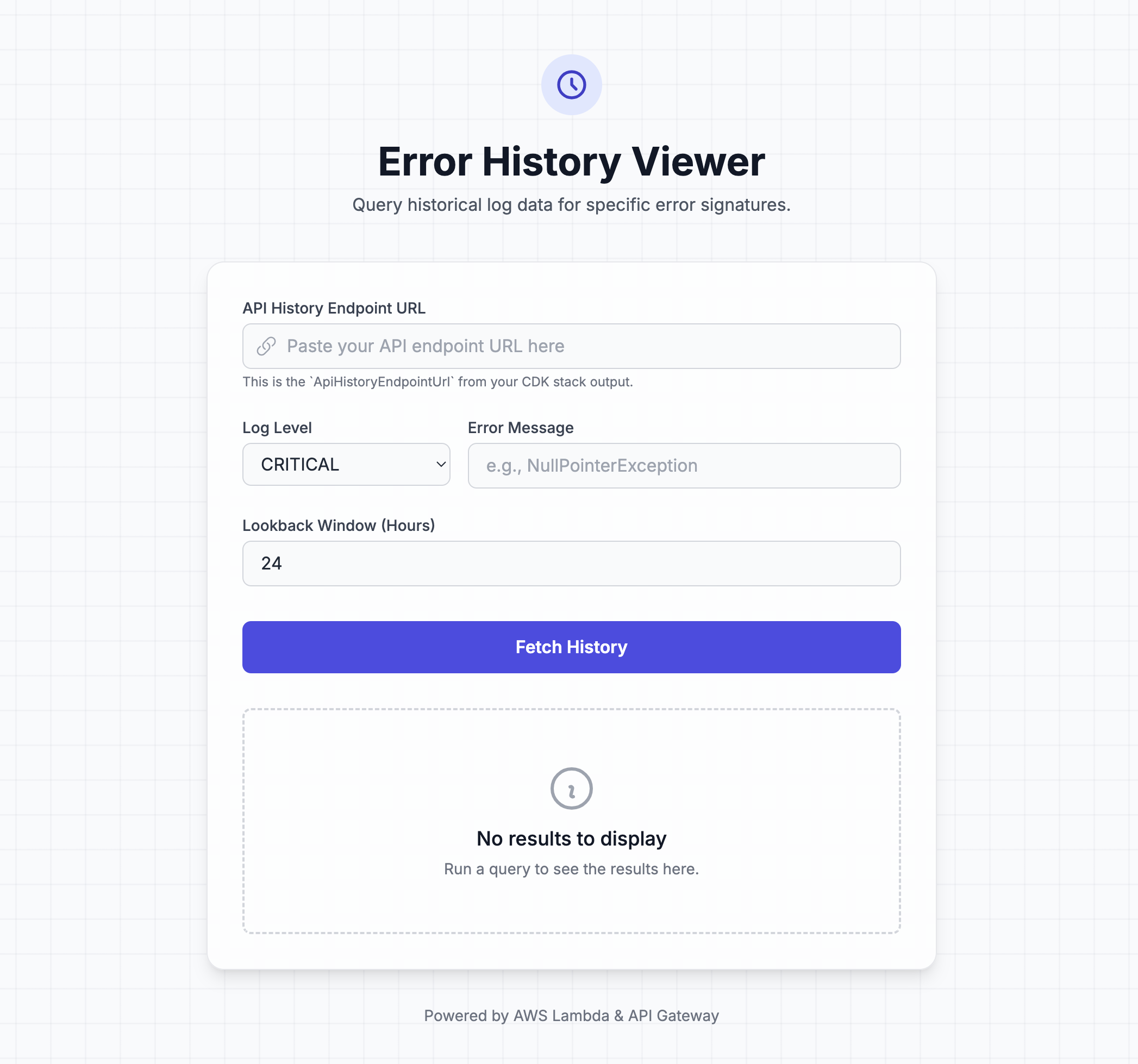
Frontend for Viewing History
Inspiration
Our inspiration came from a shared experience common to all developers and DevOps engineers: log fatigue. In any production system, logs are a firehose of information, making it incredibly difficult to find the true "signal" in the "noise." We've all spent hours sifting through terabytes of logs to find the root cause of an issue, often getting spammed by low-priority alerts that weren't actionable. We wanted to build a smarter system—a tool that automates the tedious parts of log analysis and only alerts us when it's truly important, providing the context needed to fix problems fast.
What it does
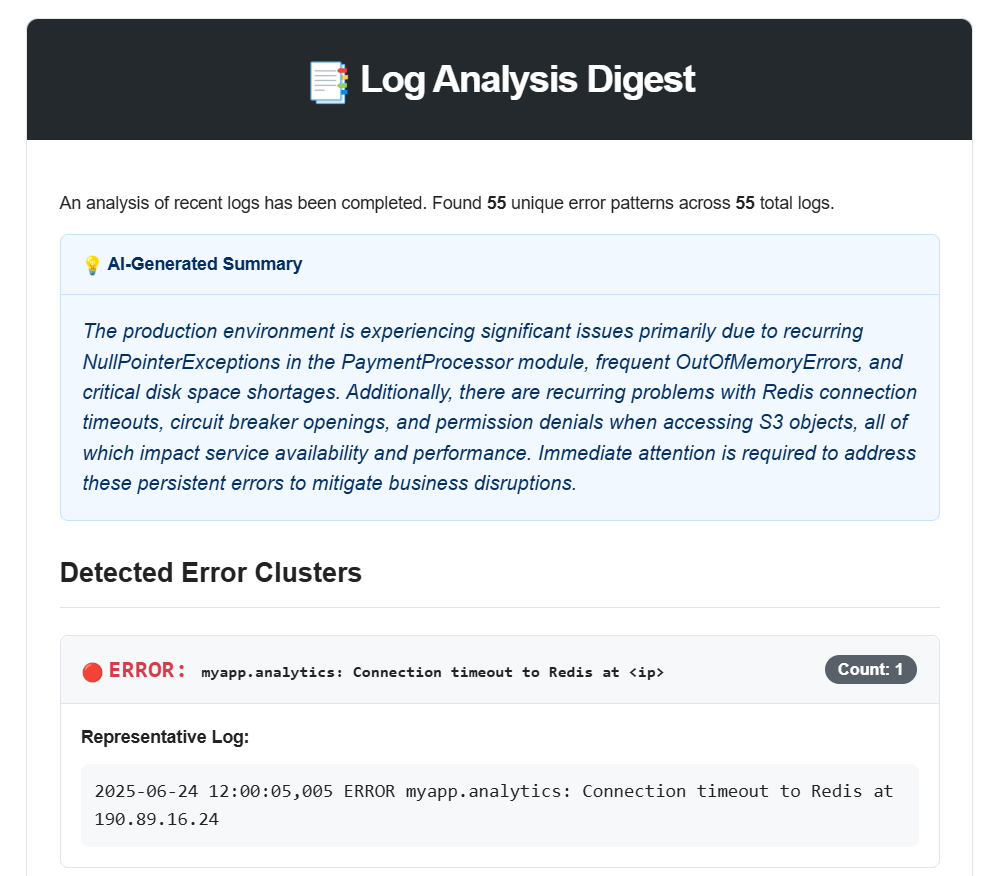
The Lambda Error Analyzer (LEA) is an end-to-end, automated log processing pipeline on AWS. It ingests raw logs from any application via a simple API endpoint, intelligently clusters them to identify unique error patterns, and uses Amazon Bedrock's Generative AI to create concise, human-readable summaries of what's going wrong. A key feature is its stateful filtering system, which analyzes the frequency of errors over time to distinguish between normal background noise and a genuine, anomalous spike. When a truly critical or recurring issue is detected, it sends a polished, actionable alert to developers via Email and Slack.
How we built it
We built LEA on a completely serverless and event-driven architecture to ensure maximum scalability and cost-efficiency.
Infrastructure as Code: The entire stack—from S3 buckets to Lambda functions and IAM roles—is defined and deployed using the AWS CDK that allows for one-command deployment and teardown.
Data Pipeline: The core of the system is a 4-stage pipeline orchestrated by AWS services. An API Gateway and Lambda handle initial ingestion, an S3 event triggers the analysis Lambda, a DynamoDB Stream triggers the filtering Lambda, and an SNS Topic triggers the final notification Lambda. This decoupled design makes the system highly resilient.
AI Summarization: We integrated Amazon Bedrock (specifically, the Amazon Nova Micro model) to provide the AI-powered summaries, which are the core "intelligence" of the system.
Stateful Analysis: We used two separate DynamoDB tables. One acts as a historical log of all analysis results, while a second, smaller table maintains the "state" (e.g., past timestamps) for each unique error signature, enabling our intelligent filtering logic.
Challenges we ran into
Integrating a brand-new service like Amazon Bedrock into a serverless pipeline was a fantastic learning experience that came with several challenges. Our biggest hurdle was a series of AccessDeniedException errors when our Lambda function tried to call the Bedrock API. We systematically worked through the problem:
IAM Policies: We first ensured the Lambda's execution role had the bedrock:InvokeModel permission.
Model Access: We then realized that, unlike other services, Bedrock requires you to manually enable model access on a per-region basis in the console.
Region Mismatch: The final piece of the puzzle was discovering a subtle mismatch between our CDK deployment region and the region where we had enabled model access. Aligning these two was the key to solving the permission issues.
API Schema Differences: We also learned that different model families on Bedrock (like Amazon Nova vs. Anthropic Claude) have slightly different JSON schemas for their API requests. This required us to write a robust request builder that could create the exact payload required by the specific model we were using, a challenge we overcame through careful documentation reading and debugging.
Accomplishments that we're proud of
We are incredibly proud of building a complete, professional-grade, end-to-end serverless application in such a short time. Specifically, we're proud of:
The Fully Event-Driven Architecture: Creating a 4-stage, decoupled pipeline that uses a variety of AWS services (API Gateway, S3, DynamoDB Streams, SNS) shows a deep understanding of modern cloud architecture.
The Intelligent Filtering: Designing the stateful filtering mechanism using a separate DynamoDB table to track error history is a feature that provides real business value by dramatically reducing alert noise.
Successful GenAI Integration: We didn't just call an AI model; we successfully integrated it into a complex data pipeline, figured out the specific permissions and API formats required, and used its output to create a polished, user-friendly result.
What we learned
This project was a deep dive into practical serverless application development. Our key learnings were:
The Nuances of IAM: We learned that AWS permissions are multi-layered. It's not just about the IAM policy attached to a role; service-specific settings, like Bedrock's "Model Access" page, are just as important.
The Power of IaC: Using the AWS CDK was a game-changer. It allowed us to define our entire architecture in code, making it repeatable, version-controlled, and easy to tear down and redeploy, which was invaluable for debugging.
Debugging in a Distributed System: When a log goes through four different Lambda functions, finding where an issue occurred requires a methodical approach to checking CloudWatch logs for each component in the chain.
What's next for Lambda Error Analyzer (LEA)
This project has a solid foundation that can be extended in many exciting ways:
ML-Powered Anomaly Detection: A key future step is to introduce true anomaly detection using machine learning. Models like Isolation Forest and DBSCAN could identify rare outliers, while STL (Seasonal-Trend decomposition) could distinguish genuine spikes from normal, cyclical error patterns.
Broader Integrations: The alerting system could be extended to support other channels like PagerDuty, Microsoft Teams, or custom webhooks.
Enhanced Web UI: The frontend could be developed into a full-fledged dashboard, displaying graphs of error trends over time, allowing users to "snooze" alerts, and providing a UI for directly configuring alerting rules.
Cross-Account Ingestion: The ingest_log API could be secured with IAM and resource policies to allow other teams within a company to securely send logs from their own AWS accounts into this central analysis system.
Efficent and Scalable-Deployments: Create Terraform modules that provision fine-frained IAM, EKS, and IRSA roles, then deploy LEA as KEDA-autoscaled containers via Helm chart eliminating manual policy setup and enabling one-command, enterprise-scale rollouts.
Built With
- amazon-api-gateway
- amazon-bedrock
- amazon-dynamodb
- amazon-lambda
- amazon-ses
- amazon-sns
- amazon-web-services
- aws-cloudformation
- aws-cloudwatch
- aws-iam
- cdk
- css
- dbstream
- docker
- firehose
- html
- javascript
- python





Log in or sign up for Devpost to join the conversation.