About LakeScope
💡 Inspiration
The inspiration for LakeScope came from a stark realization: we are trying to save 21st-century ecosystems with 20th-century tools.
Dissolved oxygen (DO) is the heartbeat of a lake. When it drops below $4 \text{mg/L}$, fish begin to die. Below $2 \text{mg/L}$, the water becomes a "dead zone." Currently, environmental agencies rely on manual sampling—sending a person out on a boat to dip a probe into the water. This process is:
- Expensive: costing ~£50-100 per sample.
- Slow: taking 3-5 days for lab validation.
- Reactive: telling us what happened last week, not what will happen next week.
I wanted to change this paradigm. I asked: Can we use the laws of physics and biology—thermal inertia and photosynthesis—to predict these dead zones before they happen?
🏗️ How I Built It
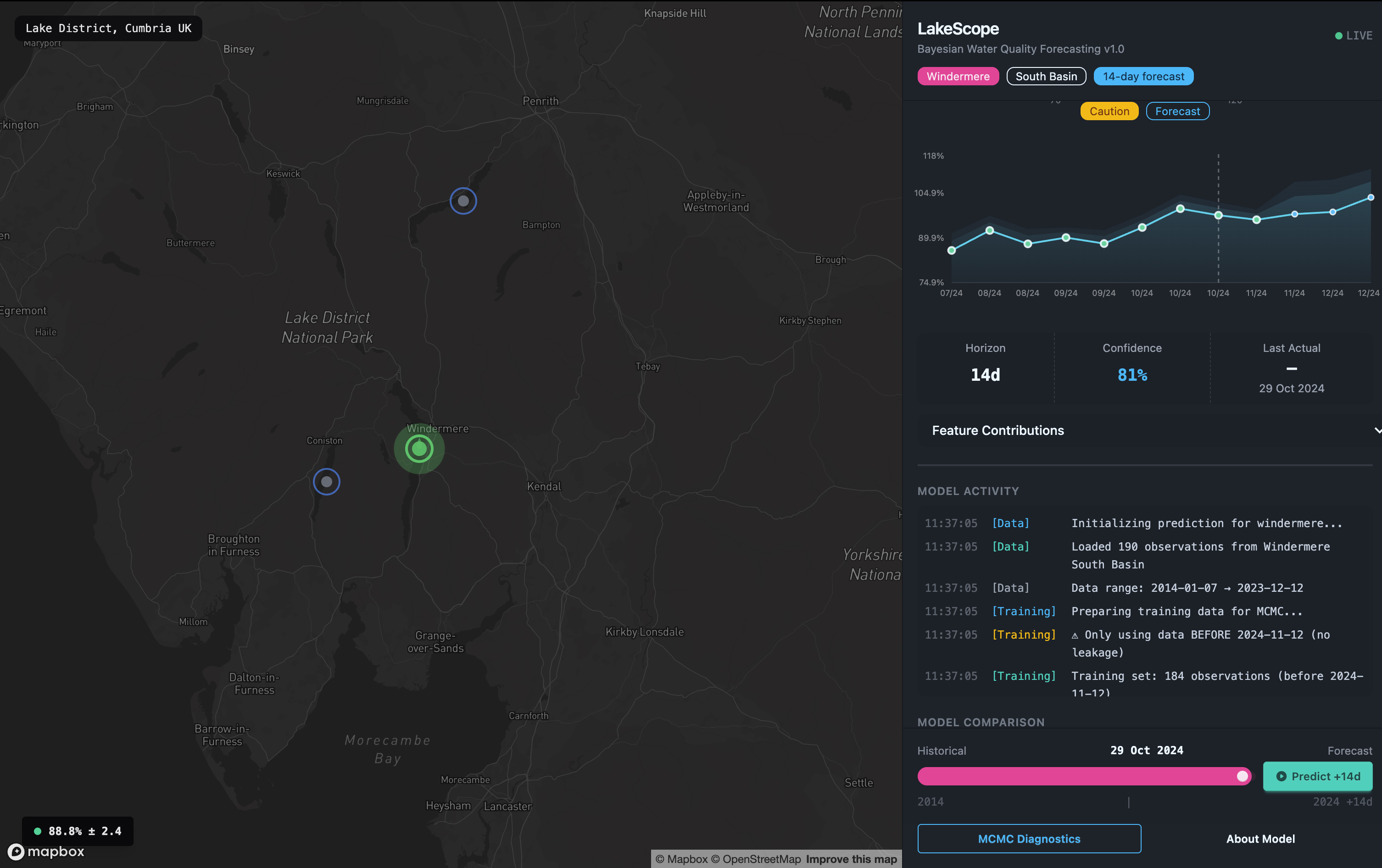
LakeScope is a full-stack Bayesian forecasting system designed for reliability.
1. The Data Engine
We integrated over 10 years of historical data (2014-2023) from three disparate sources:
- UK Environment Agency: Biweekly water chemistry (Oxygen, pH, Temperature).
- Met Office MIDAS: Hourly weather data (Air Temp, Wind Speed, Pressure).
- NRFA: Daily Hydrological data (River Flow, Rainfall).
2. Leakage-Proof Feature Engineering
The biggest trap in time-series ML is data leakage. It's easy to get a high $R^2$ by using today's temperature to predict today's oxygen... but you don't have today's temperature 14 days in advance.
We built a strict temporal feature pipeline that explicitly removed 148+ features prone to leakage. We restricted the model to three "safe" tiers of information:
- Pure Temporal: Deterministic astronomical cycles like photoperiod.
- Autoregressive Lags: $y_{t-14}$ (the measurement from the last boat trip).
- Historical Weather: Weather aggregates from the $t-28$ to $t-14$ day window.
3. Bayesian Modeling with PyMC
We chose a Bayesian approach over traditional "black box" ML because environmental decisions require risk management. We implemented a Hierarchical Seasonal Model:
$$ \begin{aligned} Oxygen_t &\sim \mathcal{N}(\mu_t, \sigma) \ \mu_t &= \alpha_{season} + \beta X_t \end{aligned} $$
This gives us a full posterior distribution, not just a single guess.
🧠 What I Learned
1. Physics > Algorithms
The most powerful feature wasn't complex neural architecture; it was Photoperiod (day length). Simple physics-> longer days = more sunlight = more photosynthesis = more oxygen outperformed almost every other indicator.
2. The "Leakage" Mirage
I initially had a model with $R^2 = 0.98$. It felt amazing, but it was fake. I had accidentally included a rolling mean of air temperature that overlapped with the prediction window. Hunting down that leak taught me that if a model looks too good to be true, it probably is.
3. Bayesian Thinking
Moving from "Point Predictions" (The oxygen will be 95%) to "Probabilistic Thinking" (There is a 95% chance oxygen is between 90-100%) is a paradigm shift. It makes the tool useful for policymakers who manage risk, not just data.
🚧 Challenges I Faced
- Sparse Data: Real-world environmental data is messy. Sampling happens every 14 days, effectively missing 13 out of every 14 days of "ground truth." Interpolation would introduce leakage, so we had to design a model that could learn robustly from sparse, irregular time steps. It took me ages to find the data.
- The "Cold Start": The UK Lake District is huge. Generalizing a model trained on Windermere to other lakes without local training data remains an open challenge (the "Transfer Learning" problem).
Built With
- numpy
- pandas
- plotly
- pymc
- python
- scikit-learn
- streamlit

Log in or sign up for Devpost to join the conversation.