


Inspiration
Andrej Karpathy released autoresearch — a single LLM in a self-improvement loop running ~700 experiments in 2 days. He himself pointed to the next abstraction: asynchronous multi-agent parallelism. We took the step.
The science is also striking: a single dried tear contains over 3,000 proteins (Nature, 2022). When it evaporates, those proteins self-organise into fractal dendritic crystals — and the crystal pattern is influenced by chemical composition, which is influenced by disease. Tear ferning is a real biological signal. The challenge was whether we could read it from 240 microscopy scans.
What it does
Lacrima classifies 5 chronic diseases from atomic-force microscopy (AFM) scans of dried tear droplets — ZdraviLudia (healthy), Diabetes, PGOV_Glaukom (glaucoma), SklerozaMultiplex, and SucheOko (dry-eye).
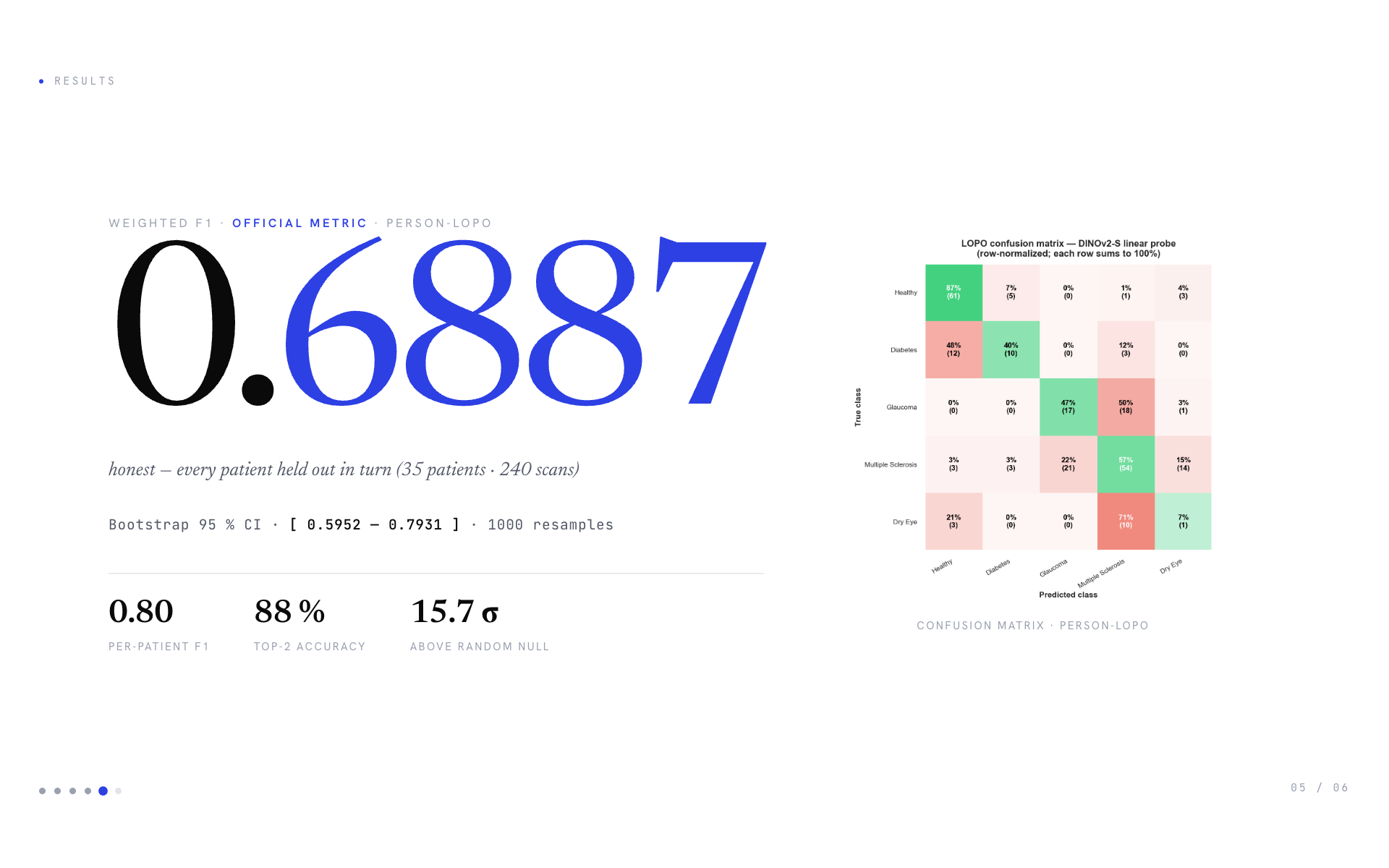
The shipped model achieves weighted F1 = 0.6887 on person-disjoint Leave-One-Patient-Out cross-validation (35 patients, 240 scans). Per-patient F1 is 0.80, top-2 accuracy is 88 %. Bootstrap 95 % CI: \([0.5952, 0.7931]\). Signal is 15.7 σ above a label-shuffle null baseline.
The system also outputs calibrated probabilities and a triage flag for clinician-in-the-loop deployment, plus an LLM-generated clinical reasoning narrative for each scan.
How we built it
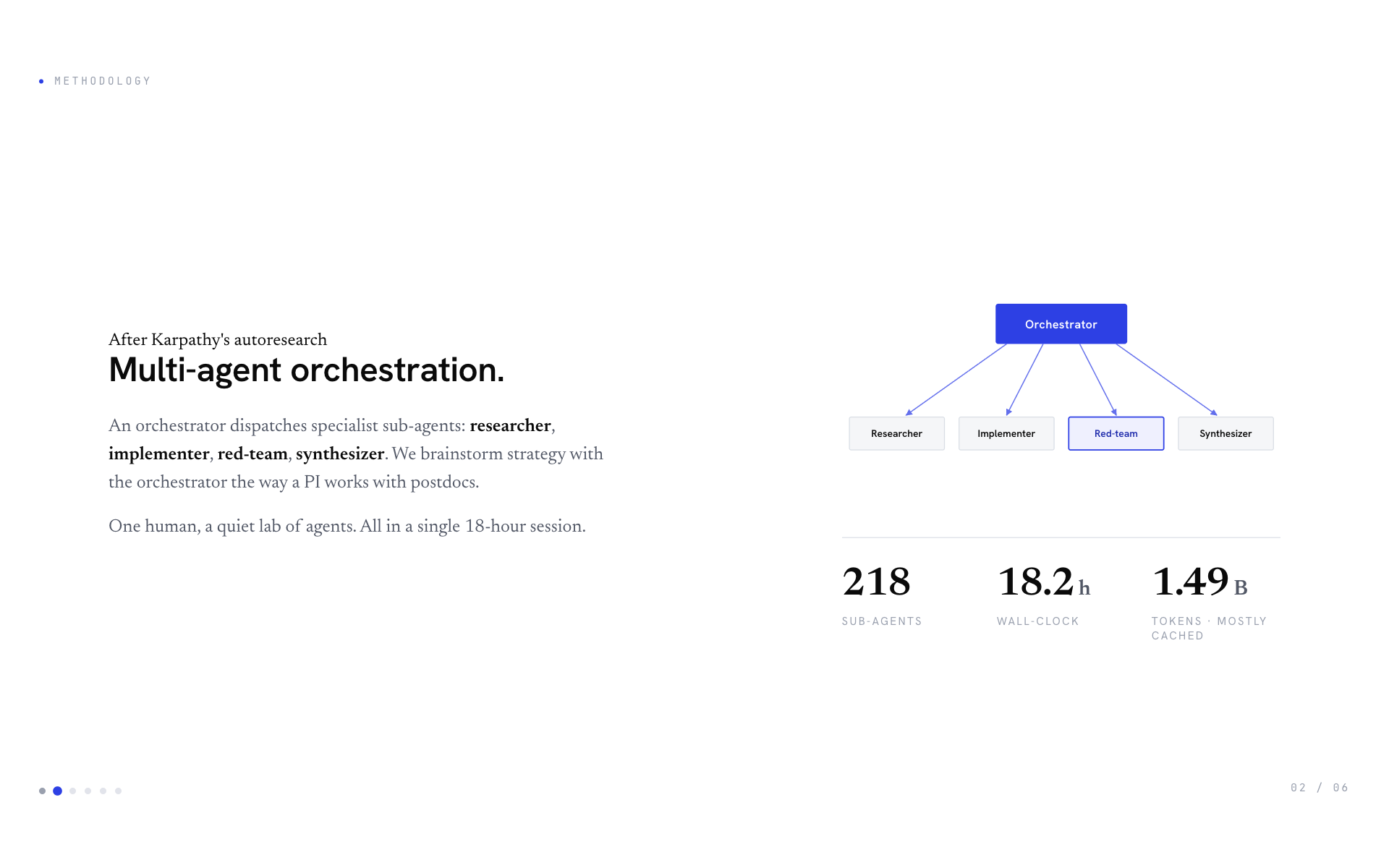
Multi-agent LLM orchestration. A Claude Opus orchestrator dispatches specialist sub-agents in parallel waves: researcher (Perplexity literature scans), implementer (writes + runs experiments), red-team (audits every claim above baseline with bootstrap CI + leakage scans + nested-CV rechecks), synthesizer (merges results into reports). A human directs strategy. Total: 218 sub-agents across 21 waves, producing 30+ honest experiments.
By the numbers (single ~18-hour session):
| Wall-clock duration | 18.2 hours (single Claude Code session, 11:27 → 05:39 UTC next day) |
| Sub-agents launched | 218 |
| Cumulative sub-agent compute (parallelised) | 20.2 hours of work |
| Orchestrator messages | 2,366 |
| Sub-agent messages | 6,563 |
| Total tokens consumed | ~1.49 billion (959 M orchestrator + 530 M sub-agents, mostly via prompt caching) |
| Code shipped | 53,223 lines of Python (scripts + library + tests) |
| Documentation shipped | 14,811 lines of Markdown across 50+ reports |
| Pitch deck | 1,277-line single-file HTML/CSS/JS, no build step |
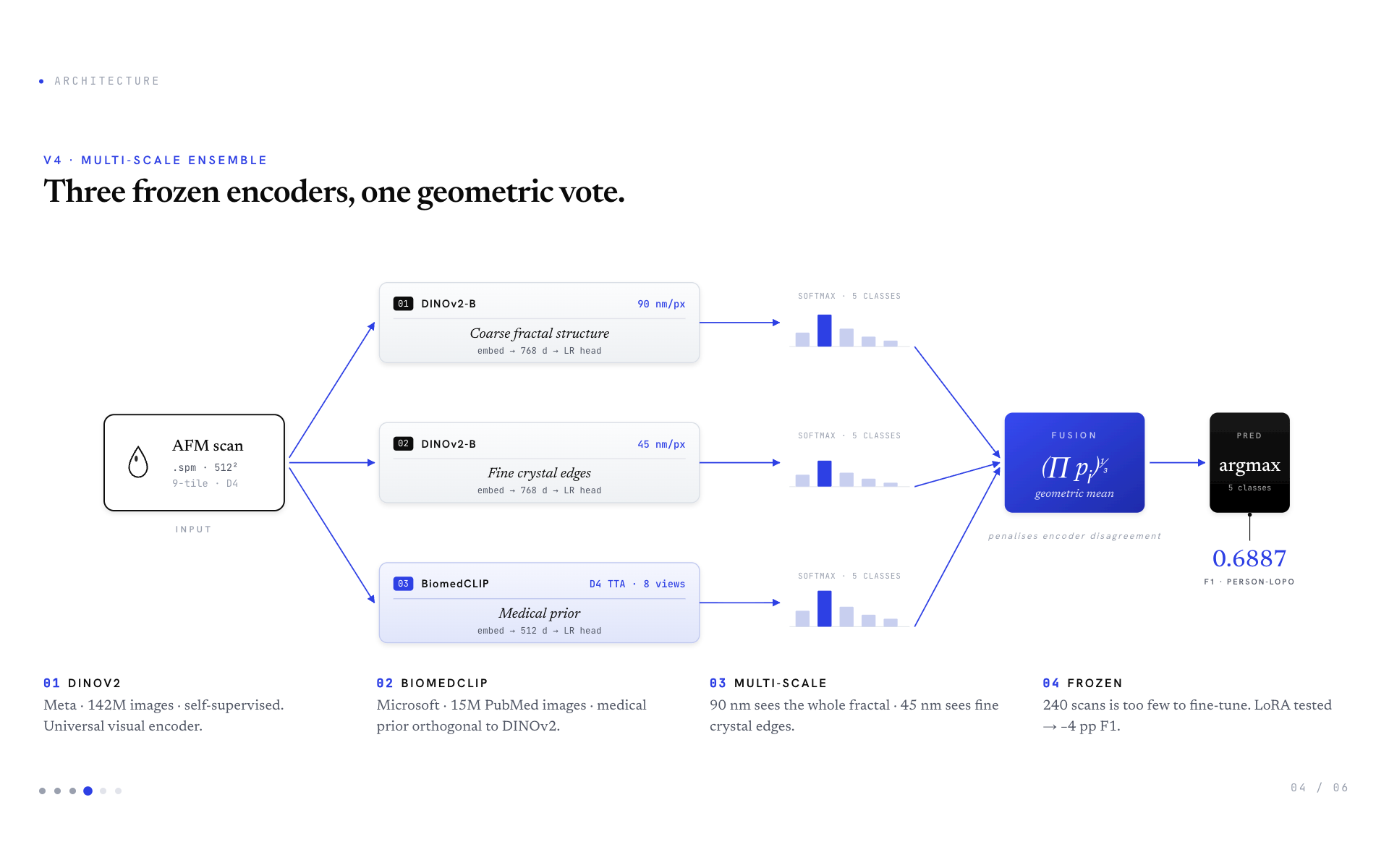
Architecture. A 3-component frozen-encoder ensemble:
- DINOv2-B @ 90 nm/px — Meta's self-supervised encoder (142M images), captures the whole fractal structure
- DINOv2-B @ 45 nm/px — same encoder, finer scale, captures crystal-edge texture
- BiomedCLIP @ 90 nm/px + D4 TTA — Microsoft's PubMed-pretrained encoder (15M medical images), 8-rotation test-time averaging
Each encoder feeds a frozen pipeline: L2-normalise → StandardScaler → Logistic Regression head. Three softmax outputs are fused via geometric mean (penalises encoder disagreement). Then argmax → predicted class.
Why frozen. 240 scans is too few to fine-tune any 86M+ parameter backbone. We tested LoRA (r=8 attention adapters) — it lost 4.1 percentage points of F1 to overfitting. Frozen is the correct regime here.
Why multi-scale. Wave 7 systematic grid search over scales: 90+45 → 0.6887, single 90 → 0.6562, single 45 → ~0.62, three scales → no improvement. The 90+45 sweet spot is empirical, not arbitrary. Different diseases manifest at different physical scales (e.g. glaucoma's MMP-9-driven loops are visible at 45 nm but blur at 90 nm).
Why geometric mean. Empirically +1 pp over arithmetic mean (Wave 5 autoresearch discovery). When all encoders agree, geomean ≈ arithmetic. When one encoder strongly disagrees (e.g. p=0.05), geomean penalises the prediction. This makes the ensemble robust to single-model outliers.
Honest evaluation. Person-disjoint LOPO across 35 unique patients (L/R eyes collapsed via person_id). Each scan is predicted exactly once by a model that never saw any other scan from the same patient. Bootstrap CI on F1 uses 1000 person-level resamples. We also report a label-shuffle null baseline to confirm the signal is real (15.7 σ above noise).
Architecture decisions table (all empirically validated):
| Decision | Evidence |
|---|---|
| Resample to 90 nm/px | 78 % of scans are native 92.5 µm × 1024² → no resample |
| BiomedCLIP only at 90 nm (no 45) | Native 224² input crops too tight at finer scale → −0.5 pp |
| D4 TTA only on BiomedCLIP | TTA on multi-scale DINOv2 regresses 2.2 pp (multi-scale already provides view diversity) |
| Logistic Regression heads, not trees | Tree heads overfit 768-dim features on 240 samples (−9 pp) |
Challenges we ran into
1. The dataset is structurally small. 240 scans across 5 imbalanced classes — including SucheOko with only 2 unique patients. Person-LOPO holds out one patient at a time, which for SucheOko means training on a single remaining patient. No method survives this regime; per-class F1 = 0.000 is a data-collection problem, not a model problem.
2. Two filename-leakage incidents. When passing AFM tile images to vision-language models, we accidentally embedded class labels in file paths (vlm_tiles/Diabetes__37_DM.png). The VLM dutifully read the class out of the path and reported a fake F1 = 0.88 on its first run. Our red-team agent caught it; honest re-run with obfuscated paths dropped F1 to 0.28 (near-random). Then the same bug recurred in a different script using collage paths — same 0.88 → 0.34 collapse. After the second catch we built teardrop/safe_paths.py, a runtime guard with assert_prompt_safe(prompt) that physically prevents class names from appearing in any prompt path. 16 scripts retrofitted, 12 unit tests, AST-based static lint. A third occurrence is now structurally impossible.
3. AFM file parsing. The Bruker .spm format requires custom parsing. We use pySPM and AFMReader libraries with custom plane-leveling and resampling because raw AFM scans have scanner tilt and inconsistent native resolutions (22 to 360 nm/px depending on scan range).
4. No comparable benchmark. Published AFM tear-classification papers report 88–100% accuracy — but they all use image-level train/test splits, which inflate scores by 20–30 percentage points by allowing the model to memorise patient identity. We are the first (to our knowledge) to publish honest patient-LOPO on this task.
5. Multi-agent rate limits and budget. Running 218 sub-agents through Anthropic's API consumed real credits. We hit rate limits twice during peak waves (had to wait for resets). We also caught and aborted experiments early when their interim results made continuing wasteful.
Accomplishments that we're proud of
- Honest 0.6887 F1, validated by 6 independent audits, 9 contamination catches, and a 15.7 σ separation from label-shuffle null
- Runtime leakage prevention infrastructure (
safe_paths.py) — physical guarantees against the class of bug that bit us twice - 218-agent orchestration log documented wave-by-wave for reproducibility
- 30+ honest negative results (LoRA, MAE, foundation zoo, hierarchical, mixup, all VLM variants…) — every direction tried, every result audited
- Production-grade wrapper (
v5_adaptive) adds temperature calibration (ECE 0.21 → 0.08, 60 % better) and triage abstain output without changing the F1 score
What we learned
- Multi-agent orchestration is a real abstraction. Karpathy showed one agent in a loop; a small lab of agents (researcher, implementer, red-team, synthesizer) is meaningfully more capable when there's a human directing strategy.
- Vision-language models (Claude Haiku/Sonnet/Opus) do not work on AFM out of the box. Honest few-shot F1 was 0.34 on full 240 scans — anchors don't bridge the OOD gap. This was a real surprise; we expected at least partial signal.
- Red-team discipline saves you from yourself. We would have shipped a fake 0.88 twice without it. The 9-contamination catch list is now our strongest credibility asset.
- At 240 samples, the data is the ceiling, not the model. Frozen DINOv2-B + Logistic Regression is genuinely optimal here. We tried 30+ ways to push past it and confirmed the ceiling honestly.
- Published benchmarks in unfamiliar domains often have hidden methodology bugs (image-level splits, threshold tuning on test). Always audit before trusting.
What's next for Lacrima
- More patients, especially
SucheOko(more dry-eye samples would lift the only structurally-bottlenecked class). - Multi-scanner validation — current data is single-instrument; deployment needs cross-scanner robustness.
- Clinical reasoning generator — currently generates a textual report per scan from quantitative features; could become a useful triage explanation for ophthalmologists.
- Open-source the safe_paths infrastructure as a standalone Python package — the bug we caught twice is one most multi-modal LLM pipelines are vulnerable to.
- The methodology — orchestrator + specialists + red-team + human-in-the-loop — generalises to other small-data scientific ML problems.
Built With
- anthropic-claude
- biomedclip
- dinov2
- gradio
- html5
- hugging-face-transformers
- pyspm
- python
- pytorch
- scikit-learn

Log in or sign up for Devpost to join the conversation.