-
-

Home page for Labophase to show the design
-
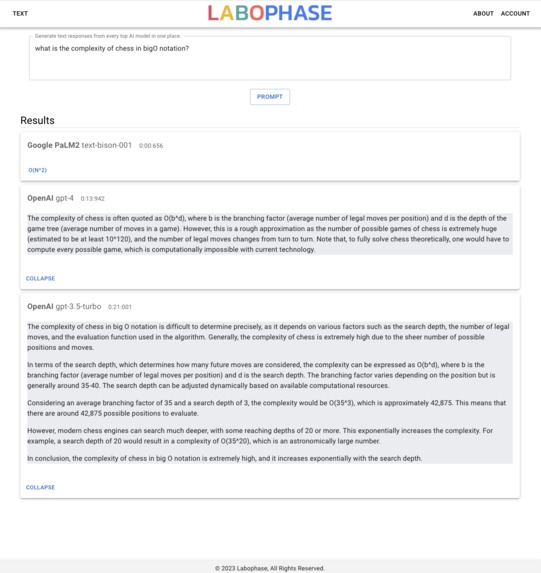
Results page to show how labophase shows expanded results from all the other llms.
-

About page to discuss data privacy and privacy policies.


Inspiration
After experimenting with LLM's, I've noticed that they often hallucinate and fabricate facts and solutions, despite their lack of knowledge about the subject matter. As a result of this unreliability, I frequently resort to cross-verification of their responses either through Google or with a different LLM. With the increasing interest in ai tools and serverless containers, I realized there was an opportunity to leverage both to create a scalable solution.
What it does
Labophase is a web application that prompts all the top LLM's simultaneously and consolidates their results. Labophase is like Google but the search results are all ai responses so all results are relevant and ad-free unlike google results.
How I built it
The project was built using docker containers for local development and deployed to production using Google Cloud Run (serverless containers). All API keys required for development were managed using dockerfiles for secrets injection.
For local development, which was done on an ARM-based Apple M1 machine - docker buildx was essential for cross platform building. Cloud Run only supports x86 architecture, so my local builds were failing. I had no easy way to recreate the failures I was seeing on Cloud Run until I used docker buildx, which allowed me to build and run x86 containers on my ARM machine.
The majority of the website's load is on the Golang backend. Containerizing the backend and frontend allows me to easily scale and leverage serverless solutions to meet demand as Labophase grows. Additionally, containerizing the frontend and backend mitigates security concerns by launching each container in a separate VM on Cloud Run. This can be considered a security boundary in case the frontend is compromised, my api keys on the backend would not be compromised.
As a result, docker containerization has been critical for a solo developer to maintain a strong security posture, deployments to production environment, and enabling me to design for scalability via serverless containers.
Challenges I ran into
There were multiple challenges I ran into:
- API throttling from both google, openai made development and scale testing very expensive. As a result, I prototyped an optimization technique where I attempted to make a dynamic vector cache of prompt results to both speed up and eliminate costs for common prompts. During implementation of the caching, I realized that a search engine interface as opposed to a chat bot lends itself much better for cache optimizations and can be a competitive advantage once dynamic vector cache is production ready.
- Poor observability on deployed applications, as the logs captured by cloudrun were often not specific enough to determine the root cause or fix.
Accomplishments that I am proud of
After a certain point in development, I was using Labophase to make Labophase because it allowed me to iterate much faster than using chatgpt, palm2 or anthropic alone. I had not touched the frontend or written a dockerfile from scratch in 3 years and I relied entirely on Labophase itself to help me write the frontend and dockerfile for Labophase itself.
An additional optimization was made possible with Labophase for the construction of the Dockerfile. While gpt4 and 3.5 only made outdated recommendations such as using old versions of node and golang in the dockerfile, the overall structure was functional and it allowed me to leverage palm2 to update parts of the dockerfile to get my docker images working and at much smaller image sizes than I would with just gpt4 alone.
What I learned
Throughout the development of Labophase, I learned a lot about LLMs and their inherent characteristics and how containerization is going to be critical for scaling Labophase in production.
For learnings related to LLM's, I learned that PaLM 2 is more succinct and significantly faster in response latency than any other API by an order of magnitude, but it also gets confused easily. GPT4 has a tendency to hallucinate and give a correct sounding response despite not knowing what something means. GPT3.5-turbo often has the same latency as GPT4's response if not longer, while being significantly worse in comprehension.
For learnings related to containerization, I learned to leverage it for multi-platform builds and it's place in accelerating deployments. Although I am experienced with AWS's serverless container offerings, it was my first experience using Google Cloud Platform where I was extremely unfamiliar with the tools and platforms available. With the containerization of my application, I was able to easily navigate deployment and onboard onto Google CloudRun's serverless containers with little knowledge of Google Cloud.
What's next for Labophase
I am excited to release Labophase with support soon for GPT4-turbo, Llama2, Claude, DALL-E 3, a 21-day vector caching policy, accounts, and pricing. I believe that Labophase has the potential to be a valuable tool for anyone who wants to get the most accurate and comprehensive answers to their questions. Personally, I believe that Labophase for Dockerfile construction and debugging would be extremely beneficial for developers as the world moves towards using more serverless containers for low maintenance scalability.

Log in or sign up for Devpost to join the conversation.