-
-
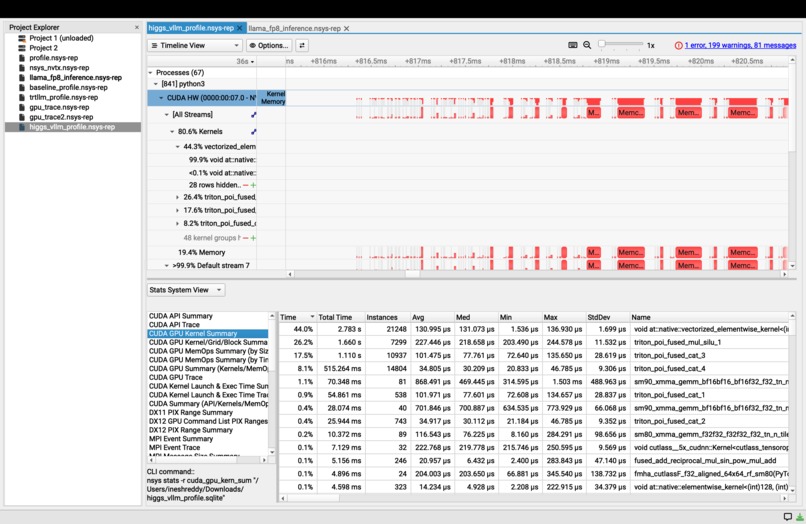
Bottleneck_Before_Optimization
-
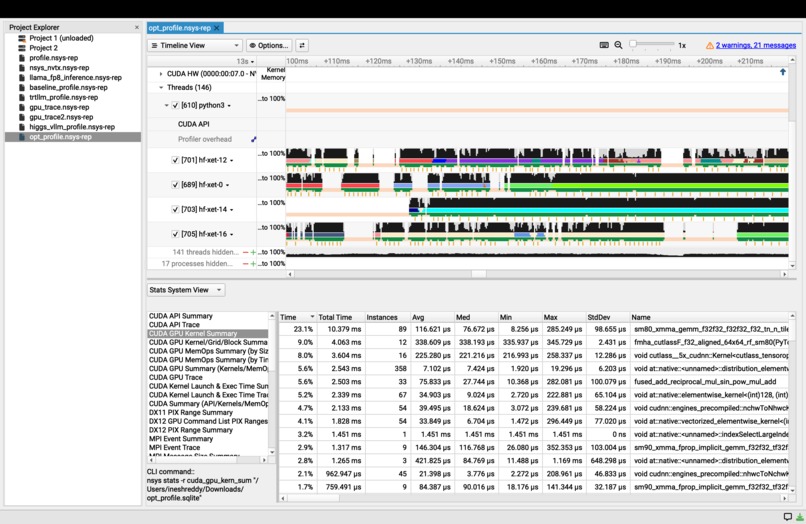
Optimzed _Graph
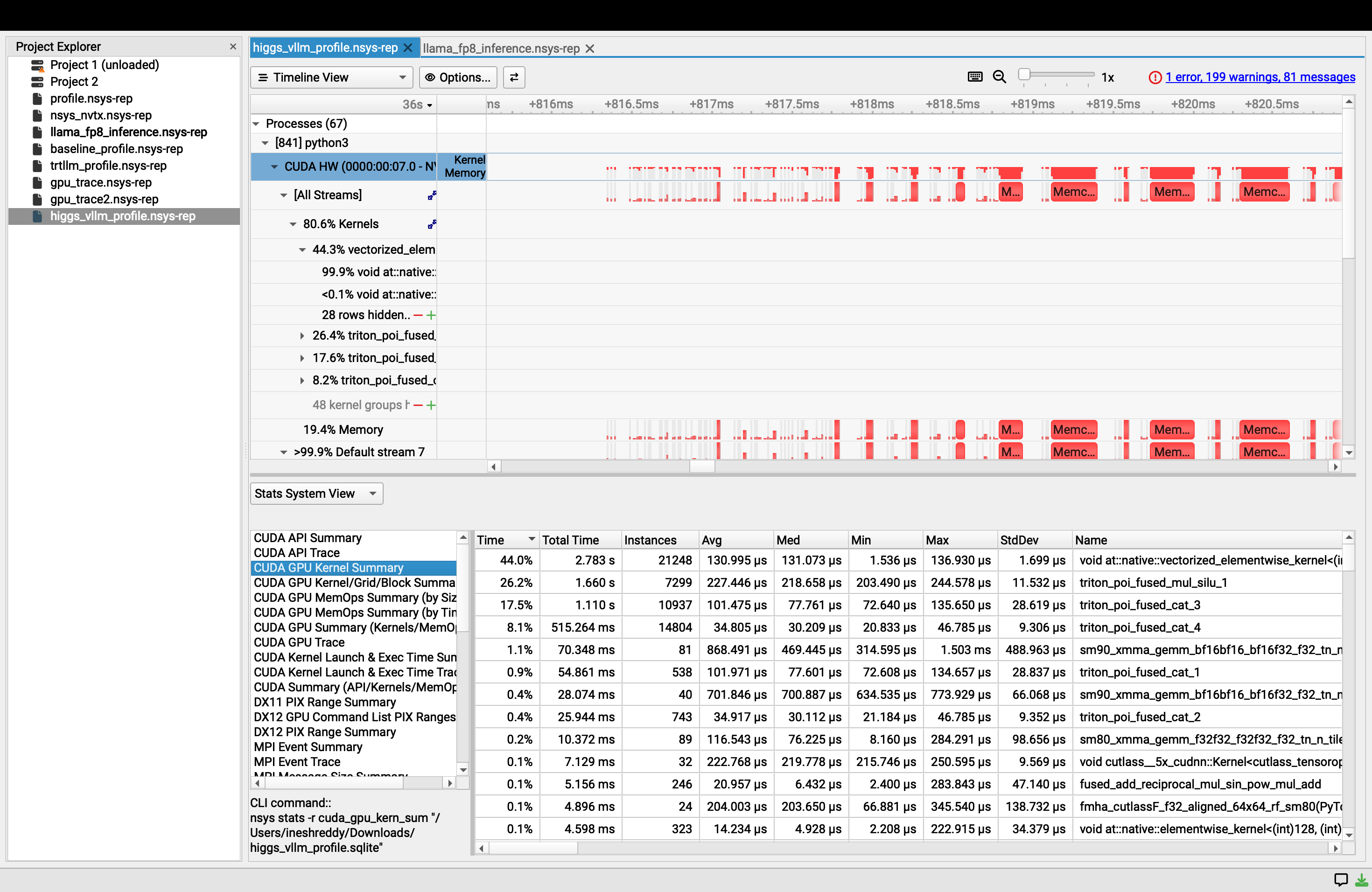
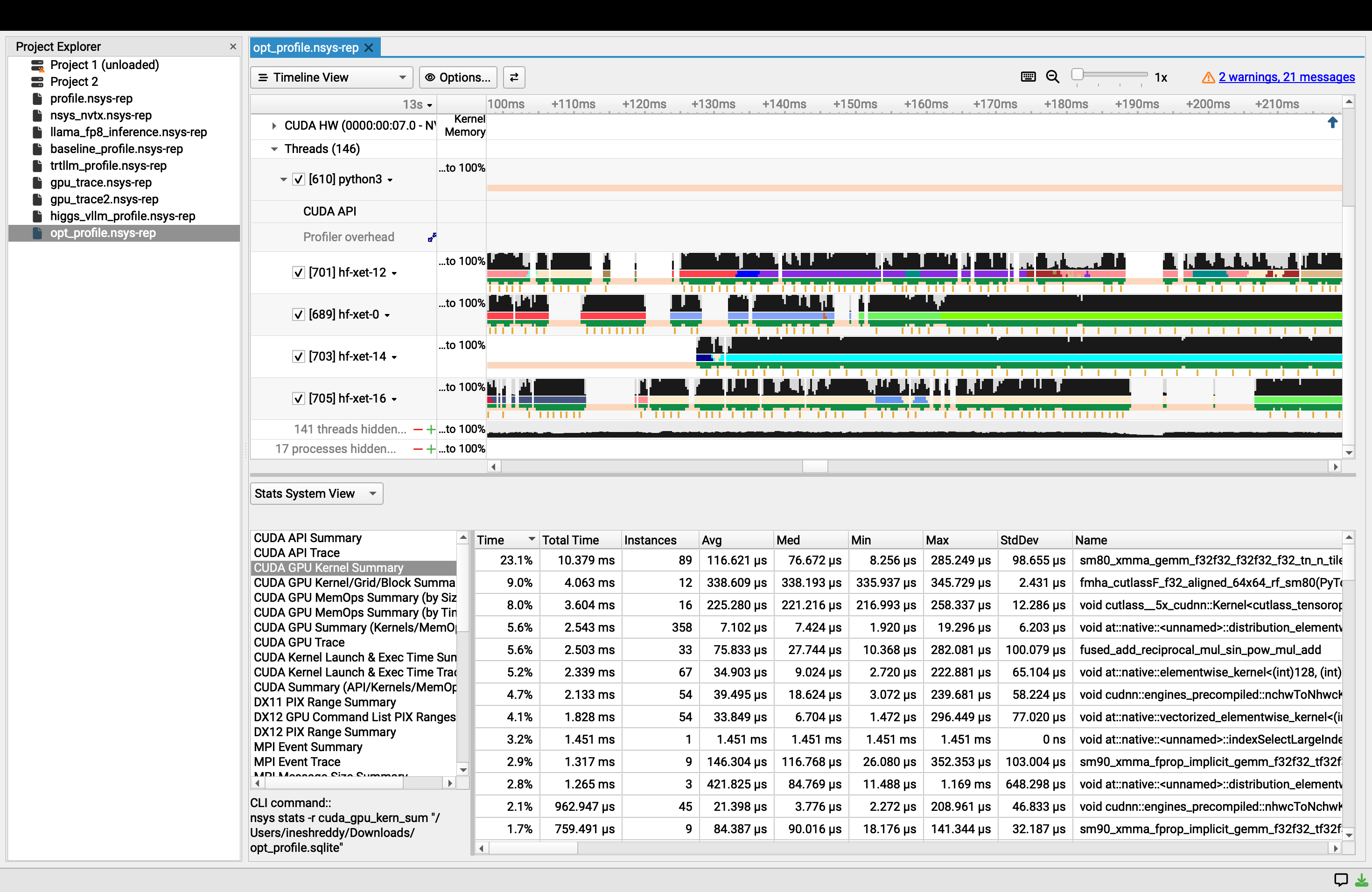
Inspiration
As an LLM inference engineer, I wanted to push Higgs Audio V2's TTS performance to its limits on H100. Instead of guessing at optimizations, I started with NVIDIA Nsight Systems profiling to find the actual bottleneck.
What I Found
Nsight revealed that 44% of GPU time was consumed by vectorized_elementwise_kernel (FillFunctor) — vLLM's KV cache allocator calling torch.zeros to write zeros into every cache block. Meanwhile, actual GEMM compute was only 1.1% of GPU time. The H100's tensor cores were barely being used.
The Fix
One line change in vLLM's V1 KV cache allocator:
# Before: torch.zeros(kv_cache_shape, dtype=dtype, device=self.device)
# After: torch.empty(kv_cache_shape, dtype=dtype, device=self.device)
torch.empty allocates the same memory without writing zeros. The zeros are unnecessary because vLLM overwrites every block with real KV values before attention reads from it.
Results
- Nsight Profile: FillFunctor dropped from 44% → 4.1%. GEMM became #1 kernel at 23.1%
- Allocation speedup: 56.7x faster (0.360ms → 0.006ms per block)
- Engine TTFT: 83ms → 15.1ms (5.5x faster)
- TPS: 99.3 tok/s, TPOT 10.0ms, RTF 0.27 (3.7x real-time)
- Concurrent scaling at 16 users: 35x real-time audio generation
- Multilingual: Tested EN, ES, ZH — zero errors across 270 requests
- Zero accuracy loss
What it does
KV-Zero optimizes Higgs Audio V2 text-to-speech inference on NVIDIA H100 by eliminating unnecessary memory operations in vLLM's KV cache allocator. It profiles GPU kernels with Nsight Systems, identifies waste, and applies a surgical one-line fix that makes the GPU spend its time on real compute instead of writing zeros.
How we built it
Profiled the vLLM serving stack with NVIDIA Nsight Systems to identify GPU kernel bottlenecks. Traced the 44% FillFunctor overhead to torch.zeros in vLLM's V1 KV cache allocation code. Patched the source inside the Docker container, re-profiled to verify the fix, and benchmarked across multiple languages, input lengths, and concurrency levels. Built a Reflex dashboard for live TTS demo with real-time vLLM engine metrics and GPU monitoring.
Challenges we ran into
The TTS endpoint returns audio bytes, not streaming tokens, making per-request metric extraction difficult — solved by diffing vLLM's prometheus metrics before/after each request. Attempted a DualFFN selective indexing optimization but it produced variable tensor sizes that broke CUDA graph capture. Learned to isolate optimizations and verify each one independently.
Accomplishments that we're proud of
Eliminated 44% of GPU waste with a single line of code. Proved it with Nsight Systems before/after profiling — FillFunctor gone, GEMM became the #1 kernel. Achieved 35x real-time audio generation at 16 concurrent users across English, Spanish, and Chinese with zero errors and zero accuracy loss.
What we learned
Profile first, optimize second. The bottleneck was not compute (GEMMs were 1.1% of GPU time) — it was memory operations. Understanding vLLM's paged KV cache architecture was key to knowing the fix was safe. The biggest wins in inference optimization come from eliminating waste, not adding complexity.
What's next for KV-Zero: Audio LLM Inference Optimizer
Submit the torch.zeros → torch.empty patch upstream to vLLM as a PR. Explore CUDA graph compatibility for the DualFFN architecture to recover the 30% TPS gap from enforce-eager. Investigate fusing the dual MLP paths with custom Triton kernels to eliminate the remaining tensor concatenation overhead (25.6% of baseline GPU time).
Tech Stack
- Model: Higgs Audio V2 (5.8B params, Llama-3.2-3B + DualFFN + xcodec)
- Serving: vLLM V1 engine with Flash Attention, prefix caching, chunked prefill
- GPU: NVIDIA H100 PCIe (81GB)
- Profiling: NVIDIA Nsight Systems
- Dashboard: Python Reflex with real-time GPU/vLLM metrics
- Infrastructure: Shadeform cloud GPU

Log in or sign up for Devpost to join the conversation.