-
-
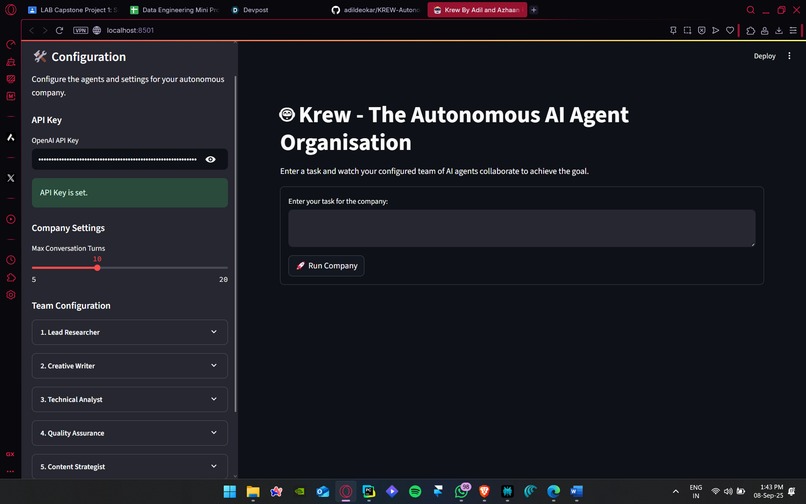
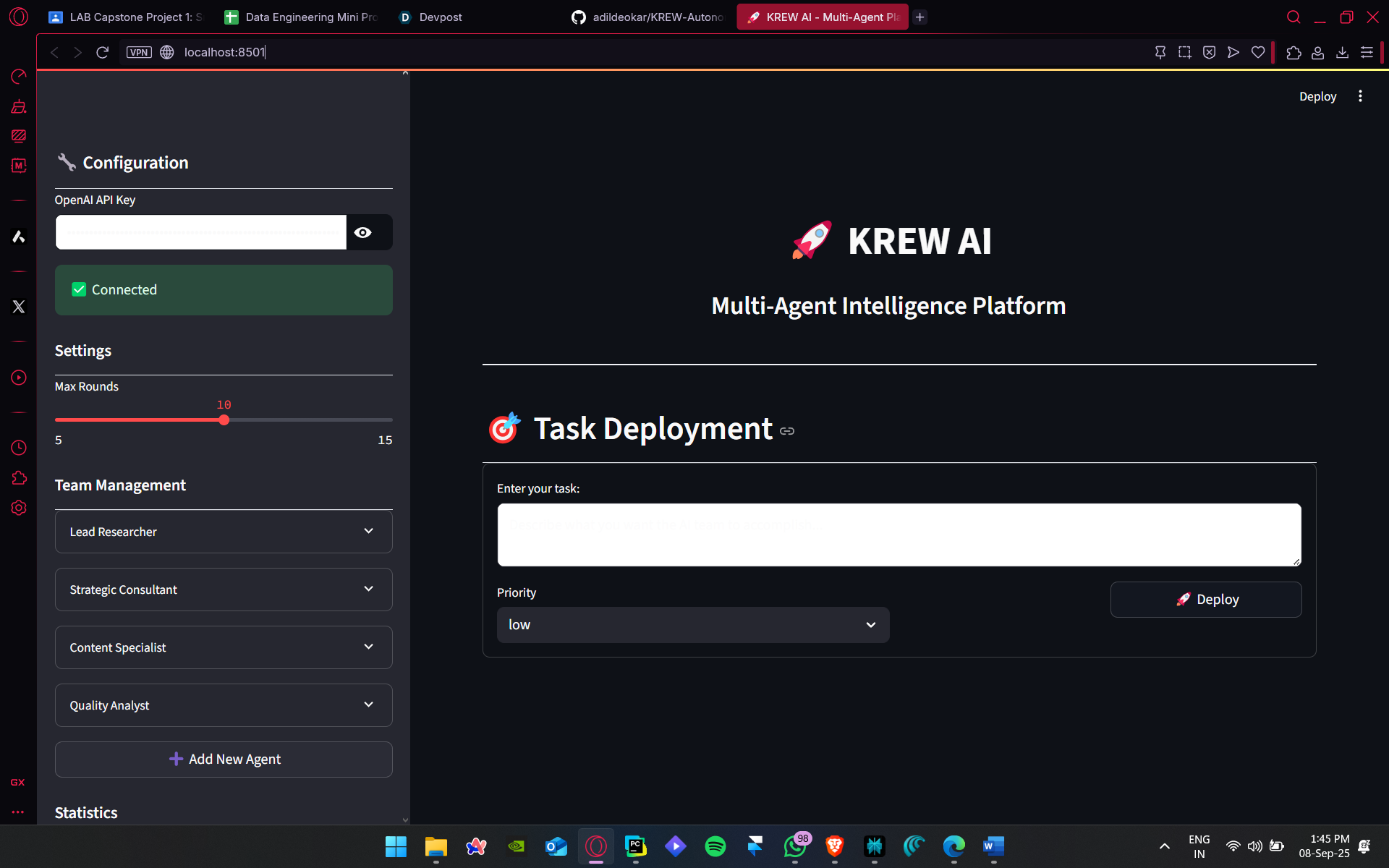
Krew Prototype V1 home page
-
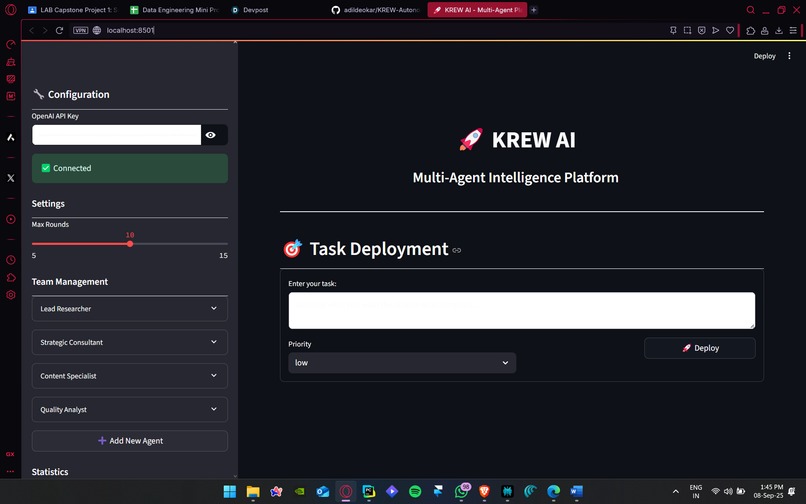
Krew Prototype V3 home page with new functionality
-
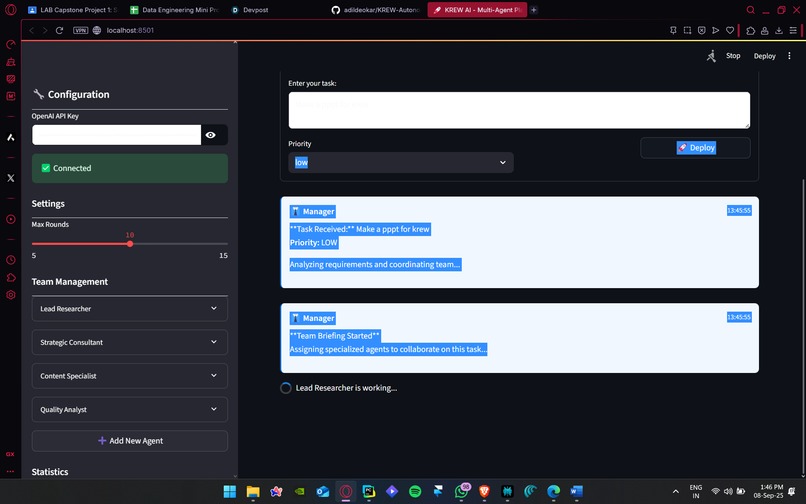
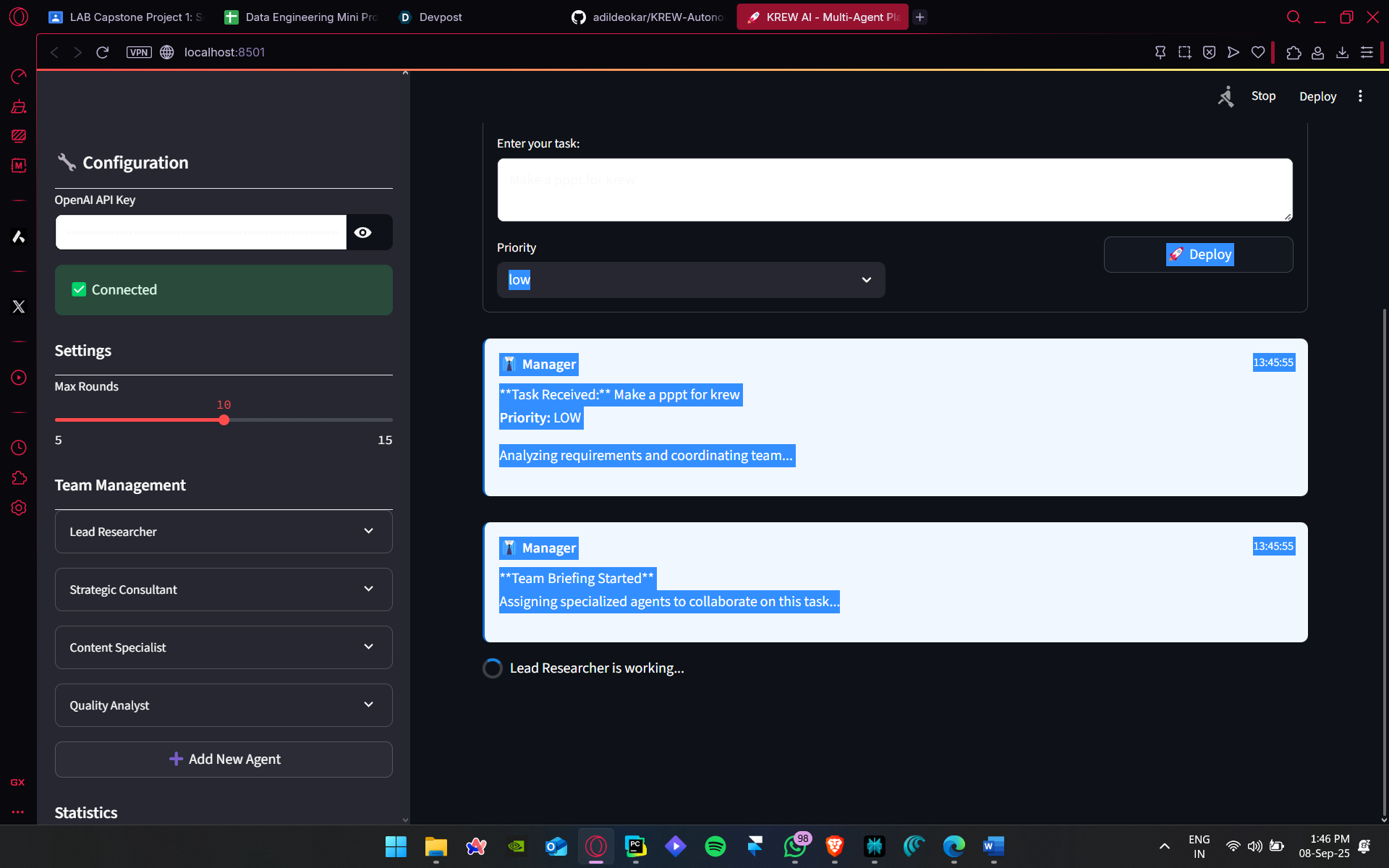
KREW V3 in action showing the thinking process
Inspiration
Krew was born from a simple realization during real client work: most knowledge tasks don’t fail at “language,” they fail at “workflow.” A single prompt can draft a decent paragraph, but it rarely researches deeply, challenges its own claims, or enforces a standard of quality that enterprises trust; teams do that, not soloists. I wanted an AI system that felt like working with a crew of specialists—research, writing, technical validation, and quality assurance—coordinated by a manager who knows when to stop and how to present the result cleanly. A second spark came from orchestration patterns documented by major architecture guides: group‑chat and orchestrator–worker designs consistently outperform ad‑hoc multi‑turn chats when they add determinism and termination. That validated my hunch to make governance a first‑class feature: fixed turn‑taking, explicit FINAL_ANSWER:, and max‑turn caps, all in a transparent, one‑page UI that non‑technical stakeholders could operate without fear.
What it does
Krew is a role‑orchestrated, multi‑agent AI platform. A Manager agent delegates to a small roster of Employees Lead Researcher, Creative Writer, Technical Analyst, Quality Assurance, and Content Strategist, each guided by a role‑specific system prompt. The Manager kicks off, cycles agents in a deterministic round‑robin, detects FINAL_ANSWER:, synthesizes the deliverable, and streams it back live. The whole experience runs inside a single Streamlit page with a sidebar to configure roles, keys, and limits. Under the hood, the first production‑ready prototype standardized on GPT‑4o‑mini for a strong latency–cost–quality balance, while keeping the design model‑agnostic so each role can be routed to a best‑fit model over time. That combination delivers researched, coherent, and QA‑checked outputs that feel “client‑ready,” not just “chat‑ready.”
How we built it
At architecture level, I chose an orchestrator–worker pattern with a single Manager mediating all communication. Agents take turns in a fixed schedule, which guarantees airtime, prevents runaway debates, and keeps spend predictable via max_turns. The stop signal is explicit—FINAL_ANSWER:—so termination is driven by agents, not heuristics. The Manager then performs a brief synthesis pass to ensure structure and polish. Implementation-wise, I intentionally kept the codebase compact—about 251 lines in Python using Streamlit 1.35 and OpenAI Python 1.x—so iteration and deployment remained fast. Everything the app needs—agent configs, chat history, max turns—lives in Streamlit’s session_state, enabling stateless hosting and easy reload resilience without external databases for the prototype phase. A lightweight Agent base class wraps generation; Employees inherit it, receive role‑specific system prompts, and produce role‑appropriate contributions. On UX, a single‑page interface reduces cognitive load. The sidebar edits roles on the fly (add/rename/delete), flips feature flags, and manages keys and caps; the chat area streams intermediate messages so stakeholders can “see the debate,” which builds trust and auditability. Error states surface visibly (API exceptions, timeouts), and streaming preserves responsiveness even across multi‑turn loops.
Challenges we ran into
Prompt injection and safety: The biggest risk in LLM systems is input that tries to override system behavior or exfiltrate data. I hardened system prompts, added post‑generation semantic checks for unsafe content, and scoped tools/permissions by role under least‑privilege principles. For production, secrets move from UI into environment variables or vaults.
Token growth and context limits: Full transcript replay each turn is simple but risky as conversations scale. To mitigate, I implemented sliding‑window summarization and designed for per‑role vector memory to keep context focused as projects lengthen.
Single‑manager bottleneck: Serializing all requests through one Manager keeps rate‑limit handling simple and improves predictability, but imposes latency ceilings under heavy load. The roadmap includes federated managers and concurrent sub‑teams with quorum voting.
Cost/latency trade‑offs: I standardized on GPT‑4o‑mini for the prototype to hit a sub‑20‑second ten‑turn loop while preserving output quality. The platform remains model‑agnostic, allowing later per‑role routing by cost, SLA, or capability
Accomplishments that we're proud of
A production‑feasible loop in a tiny codebase: In ≈251 LOC, Krew implements deterministic multi‑agent orchestration, live streaming, and role editing—all the essentials needed to test the thesis quickly and credibly.
Measured improvements vs single‑prompt baselines: Across 30 runs, the ten‑turn loop averaged ~18.6 seconds and stayed under ~200 MB RAM in a 1 GB container; quality scored ROUGE‑L ≈ 0.41 on a 25‑question set, and blind human review judged 72% of Krew answers “acceptable” vs 48% for a single‑prompt baseline. That’s an orchestration‑driven gain, not a model‑swap mirage.
UX that “brings people along”: The one‑page Streamlit app with a transparent transcript gave non‑technical reviewers confidence in the method and the output. This mattered more than any single metric; adoption hinges on trust, and trust hinges on visible process.
What we learned
Specialization reduces cognitive load and improves coherence. Giving each agent a narrow mandate (e.g., “As Lead Researcher…” or “As Quality Assurance…”) yielded cleaner intermediate artifacts and made the Manager’s final synthesis more mechanical and reliable. It felt like editing a panel of experts instead of fixing a monologue. Deterministic governance is a quality feature, not just an ops feature. Fixed turn‑taking, explicit stops, and caps transformed open‑ended “group chats” into predictable, auditable collaboration. This is how multi‑agent stops feeling like a demo and starts feeling like a system.
What's next for KREW - Autonomous AI Agent Organisation
Federated manager mesh and concurrent sub‑teams: Introduce hierarchical or mesh managers to parallelize strands of work, add quorum voting for diverse‑thought generation, and implement health checks for graceful degradation at scale.
Role templates and memory: Migrate to declarative crew templates (YAML) and equip each role with vector memory, enabling rapid domain onboarding and sustained long‑form projects without context blow‑ups.
Adaptive speaker selection and structured debate: Move beyond round‑robin where helpful—use utility‑based scheduling and structured critic–resolver patterns for complex problem solving.
Evaluations and governance: Add dashboards for ROUGE/BERTScore and reference‑free metrics such as Ragas, wire RBAC and DLP policies per role, and polish observability via OpenTelemetry to make cost, latency, and safety first‑class.
Multi‑model, least‑privilege tooling: Route each role to the best‑fit model and toolset—search, code‑exec, retrieval—under strict scopes, turning Krew into a governed, modular AI organization ready for regulated environments.
Built With
- 251?line-krew.py
- 251?line-krew.py-minimal-codebase
- adaptive-speaker-selection-(critic/debate/resolver)-(planned)
- alb/elb
- autoscaling
- bleu/bertscore/ragas-dashboards-(planned)
- ci/cd-via-github-actions-(lint
- claude
- deepeval
- deterministic-round?robin-orchestration
- embedding-cache-(planned)
- embedding?similarity-prompt-cache-(planned)
- employee-specializations
- enterprise-connectors-and-plugin-marketplace-with-sandboxing-(jira/confluence/slack/drive)-(planned)
- env?vars-for-secrets
- environment-variables-for-secrets
- error-banners/spinners
- error/exception-banners-and-spinners
- evaluation-stack-with-rouge?l-baseline-(0.41)
- faiss/pgvector-role-memory-(planned)
- federated/hierarchical-manager-mesh-with-quorum-voting-and-health-checks-(planned)
- federated/hierarchical-managers-+-quorum-(planned)
- function?calling-tools-+-least?privilege-scopes-(planned)
- function?calling-tools-for-web-search/code?exec/rag-(behind-flag)
- gemini-via-bedrock/vertex/azure-openai)-(planned)
- github-actions-ci/cd
- gpt?4o?mini
- gpt?4o?mini-(128k-context)-primary-llm
- https)
- image-push)
- least?privilege-tool-scopes-per-role
- loop-timing/guards
- manager-supervisor)
- manager?employee-agents-with-round?robin-orchestration
- manager?employee-class-hierarchy-(agent-base
- multi?model-routing-(openai/claude/gemini)-(planned)
- multi?model/provider-routing-(gpt?4o?standard
- observability-dashboards-for-cost/latency/tokens
- openai-python-sdk-1.x-(chat-completions)
- opentelemetry-hooks-(planned)
- opentelemetry-hooks-for-tracing/metrics-(planned)
- optional-docker-on-aws
- optional-dockerized-deployment-to-aws-ec2/ecs/kubernetes
- per?role-vector-memory-with-faiss/pgvector-(planned)
- plugin-marketplace-+-enterprise-connectors-(planned)
- postgresql-for-persistent-logs/audit-trails-(planned)
- prompt-tests
- prototype-hosting-on-streamlit-cloud-(1-vcpu/1-gb-ram
- python-3.11
- rbac/dlp/soc?2-logging-(planned)
- rbac/policy-engine-and-dlp-filters-(planned)
- redis/elasticache-session-offload-(planned)
- redis/postgresql/s3-(planned)
- regex-final-answer-detection
- regex-final-answer:-detection
- role?specific-system-prompts
- role?specific-system-prompts-per-agent
- s3/blob-storage-for-artifacts-(planned)
- server?side-calls-with-markdown-streaming
- server?side-network-calls-with-progressive-markdown-streaming
- sliding?window-summarization-(planned)
- sliding?window-summarization-for-token-control
- soc?2-logging/retention/audit-exports-(planned)
- streamlit-1.35
- streamlit-1.35-single?page-ui
- streamlit-cloud-hosting
- streamlit-session-state
- streamlit-session-state-persistence
- zero?trust-boundaries-with-token?level-redaction-and-output-pii/policy-filters

Log in or sign up for Devpost to join the conversation.