



Inspiration
We noticed how difficult and** time-consuming** it is to compress AI models for deployment on different hardware. Most tools are fragmented and require manual tuning, which slows down innovation. We wanted to simplify this.
What it does
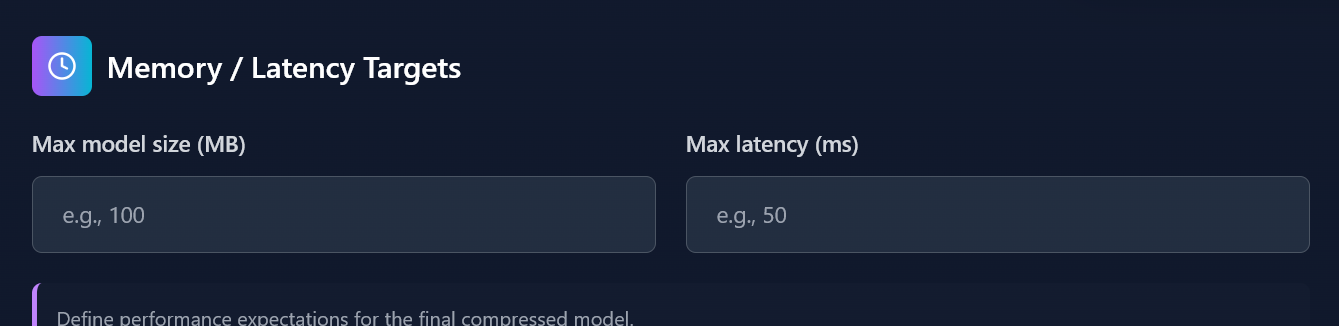
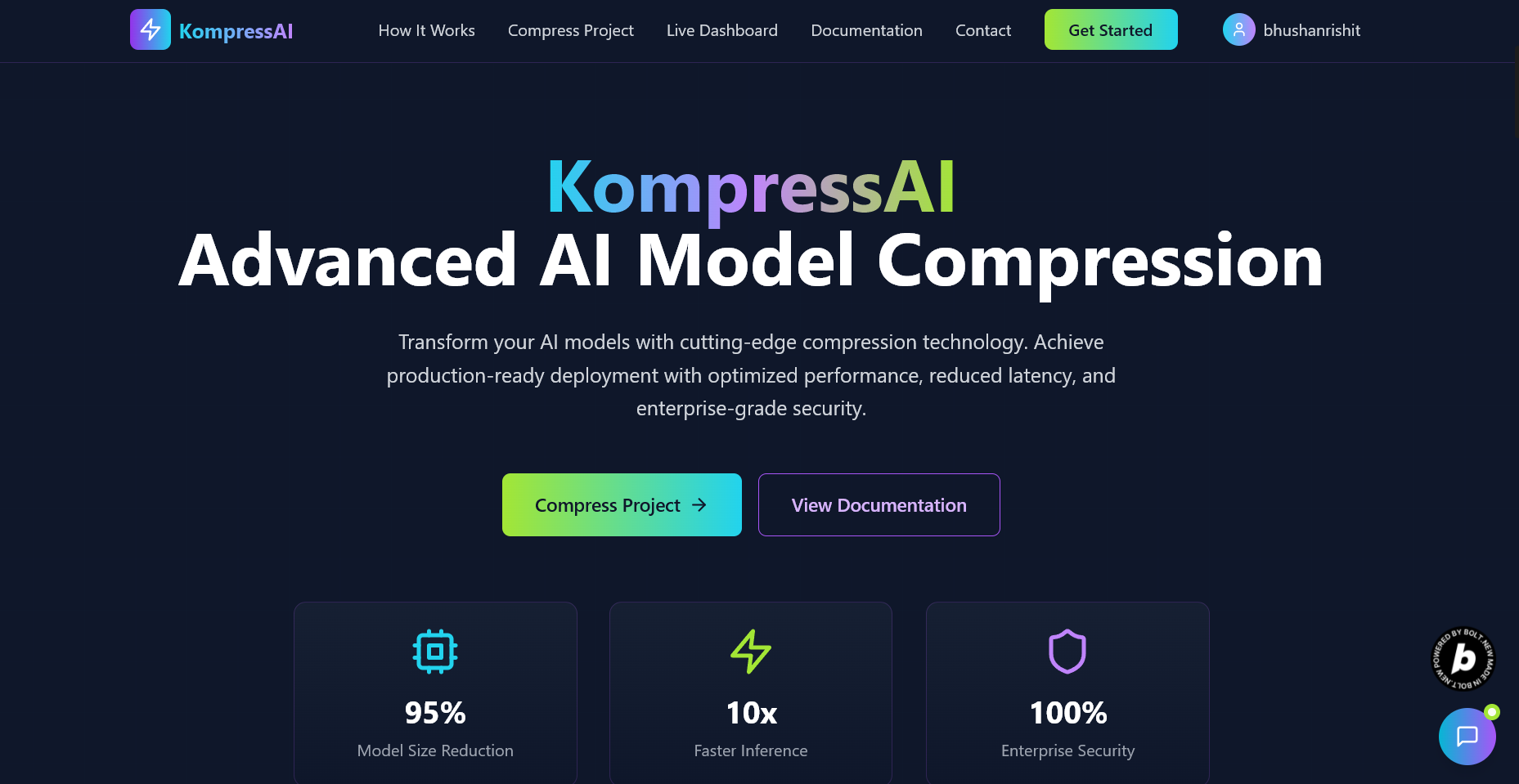
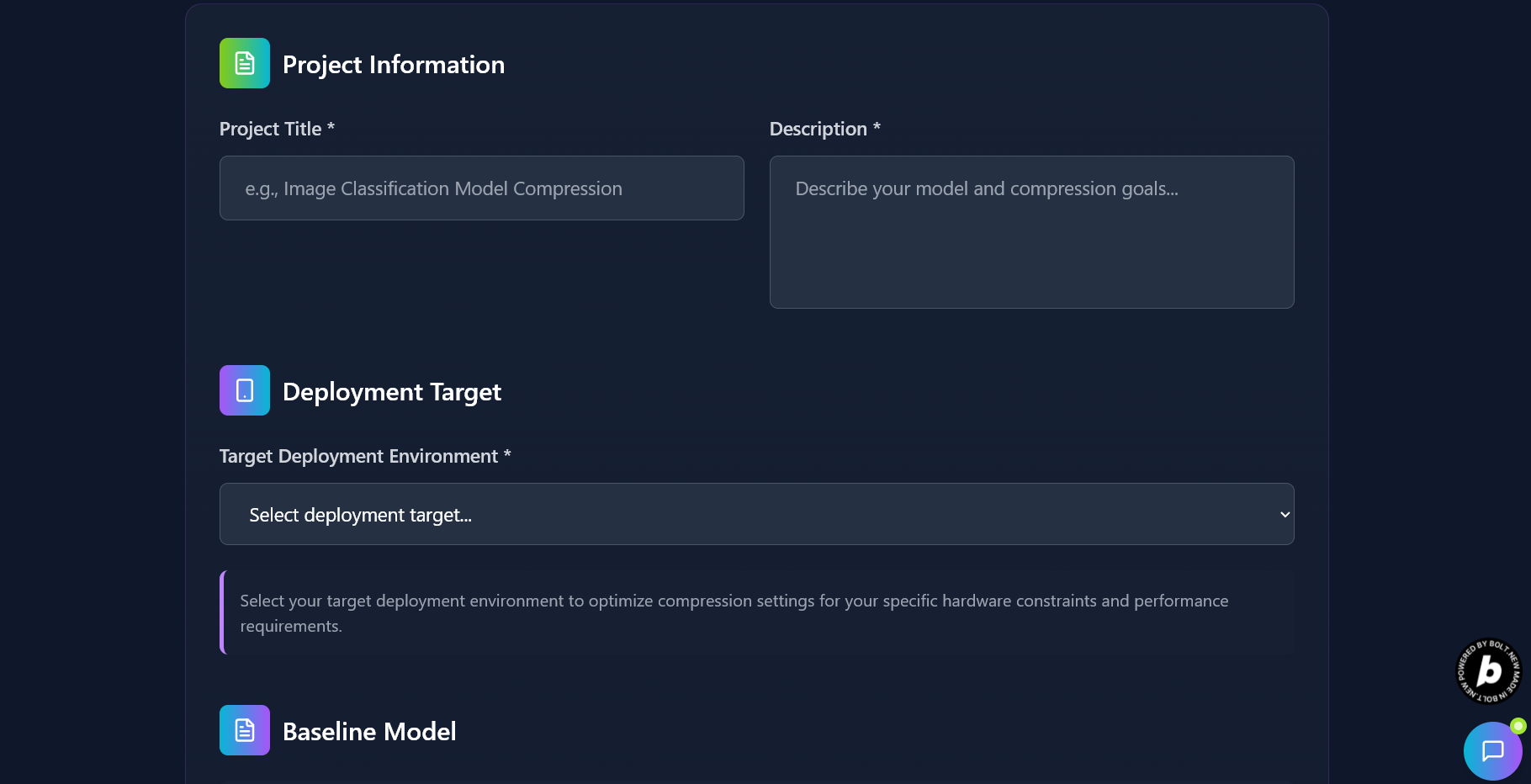
KompressAI is an AI-powered platform that simplifies the process of compressing machine learning models for deployment across a variety of devices—from microcontrollers to powerful edge GPUs. Instead of relying on multiple separate tools and manual tweaking, users can upload their AI model files, specify performance constraints (like max size, latency, or accuracy loss), and** KompressAI intelligently prepares a compressed version of their model.**
The platform automatically adapts the compression strategy based on the intended deployment environment—whether it’s a** CPU, GPU, mobile device, or microcontroller.** It supports multiple output formats such as ONNX, TFLite etc. making it suitable for a wide range of use cases.
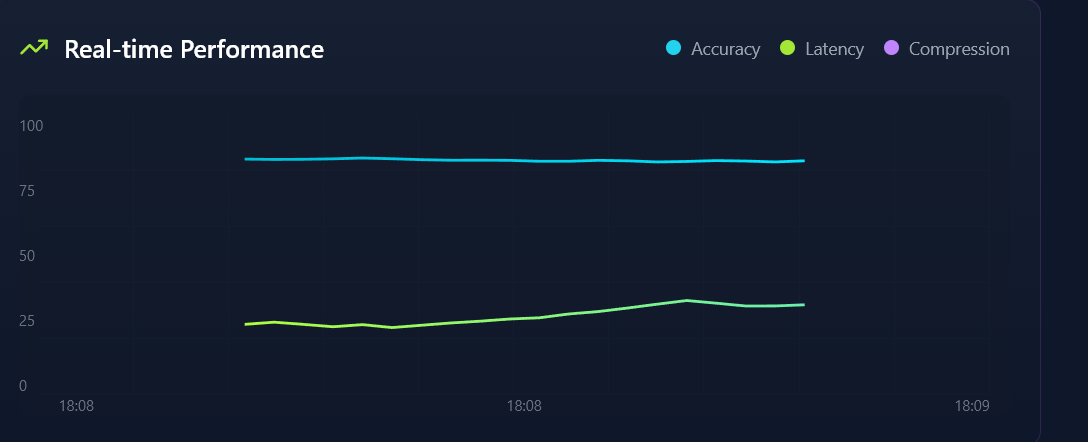
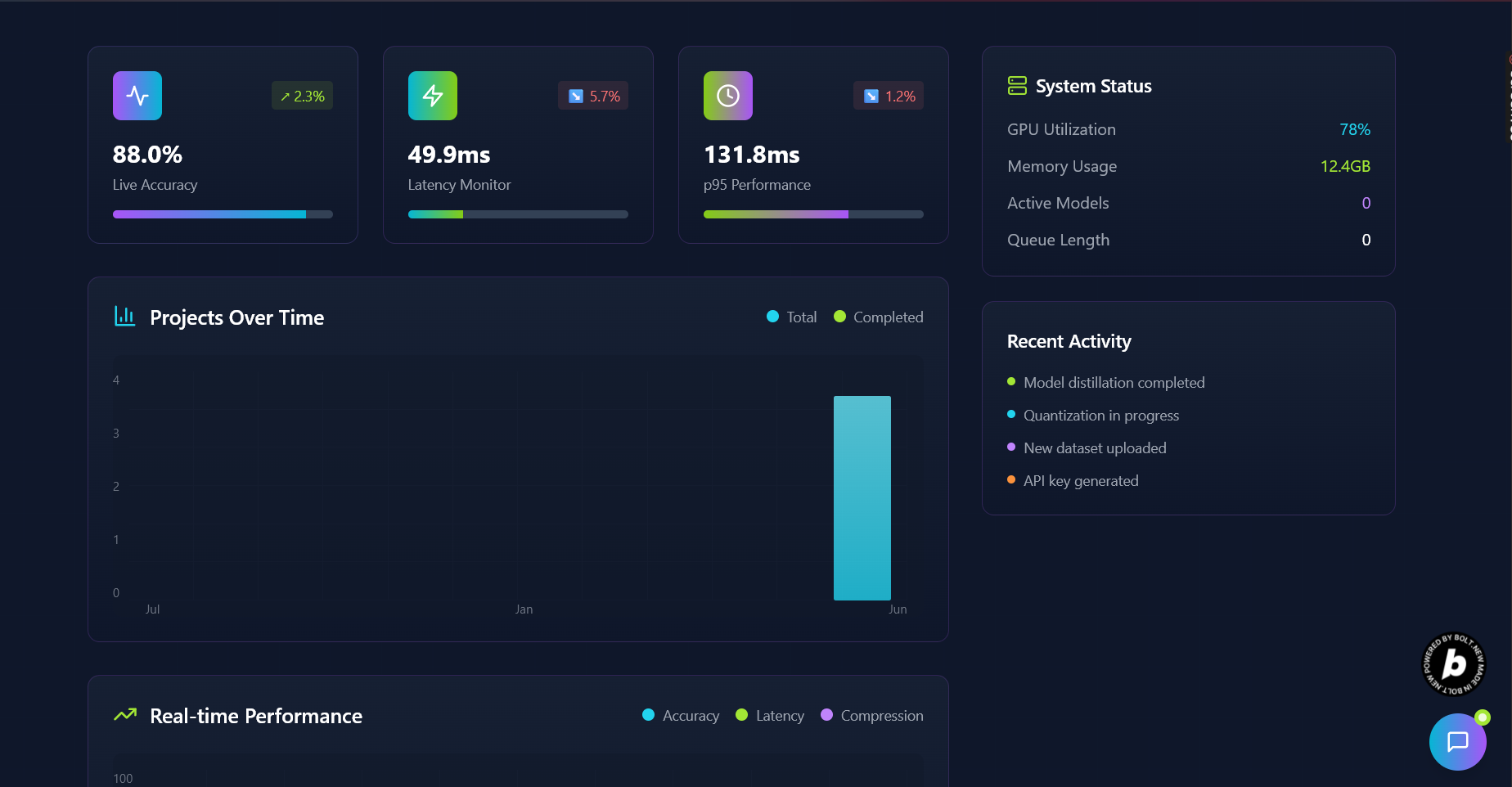
Users receive a transparent report showing how the model was compressed,** what techniques were applied, and how accuracy and size were affected. Ultimately, KompressAI enables developers to deploy models faster, lighter, and smarter
How we built it
We started by designing a clean and user-friendly frontend using** Bolt.new,** a no-code AI-powered website builder that let us prototype quickly. The site includes forms to collect user input, upload model files (like .onnx, .zip, .py, etc.), and define compression preferences.
For the backend and data handling, we integrated Supabase, which served as our real-time database, authentication provider, and file storage system. We created a table to store all project-related data—such as the model file, dataset, evaluation script, preprocessing pipeline, and constraints like accuracy floor or latency limits. Supabase’s storage buckets were used to securely store all uploaded files, with access control policies enforced via Row Level Security (RLS).
We also incorporated logic to simulate AI model compression, generate reports, and handle environment-specific configurations. Though compression wasn’t executed live (yet), the platform mimics the real pipeline and is designed to plug into actual compression engines in the future.
Finally, we deployed the entire platform on Netlify, ensuring fast, global access and easy continuous updates. Netlify's integration with Git and smooth deployment pipeline made it easy to go live and share KompressAI with others.
Challenges we ran into
Handling file uploads and access control via Supabase was tricky. Creating a universal format system and setting up real-time, constraint-aware processing also needed careful planning.
Accomplishments that we're proud of
We built a full-stack solution that automates a process many developers struggle with. The platform is flexible, environment-aware, and user-friendly—all within a limited time.
What we learned
We built a full-stack solution that automates a process many developers struggle with. The platform is flexible, environment-aware, and user-friendly—all within a limited time.
What's next for Kompress AI
We plan to integrate actual compression engines, support more formats, and make the system smarter with real-time meta-learning. We also want to add analytics and recommendations based on model type and hardware.




Log in or sign up for Devpost to join the conversation.