
Komachi Health
A conversational decision-support tool that learns what alcohol-drinking action to take at each point in a person's life to improve their long-term survival, and explains the resulting risk in plain language.
Inspiration
Public guidance on alcohol and cardiovascular health is contradictory and almost always population-level. One year a glass of red wine is good for you, the next no amount is safe. None of it answers the question a person actually has: given my health trajectory, what should I do over the next decade, and how much does it change my risk?
Medical evidence is powerful, but it is often not personalized. Most recommendations rest on population-level averages and limited datasets rather than an individual's health history, risk factors, and local context. As larger real-world datasets become available across communities, health systems, and hospitals, we saw an opportunity to combine personal health records, local real-world data, and global medical evidence to support better decisions for long-term health.
The question of what to do over time is longitudinal and counterfactual. It concerns a sequence of choices and their effect on a survival outcome, not a single snapshot. That is the problem studied in Survival Policy Learning as Inference (Shirakawa et al., NeurIPS 2026), a paper by two of our teammates: learning a treatment policy that maximizes counterfactual survival from longitudinal observational data, using causal inference rather than heuristic rewards.
For this hackathon we took that method out of the research code and built something a person can talk to. The result is a chatbot that collects a health history, estimates risk, and proposes a drinking plan, backed by the survival model and clinical evidence.
What it does
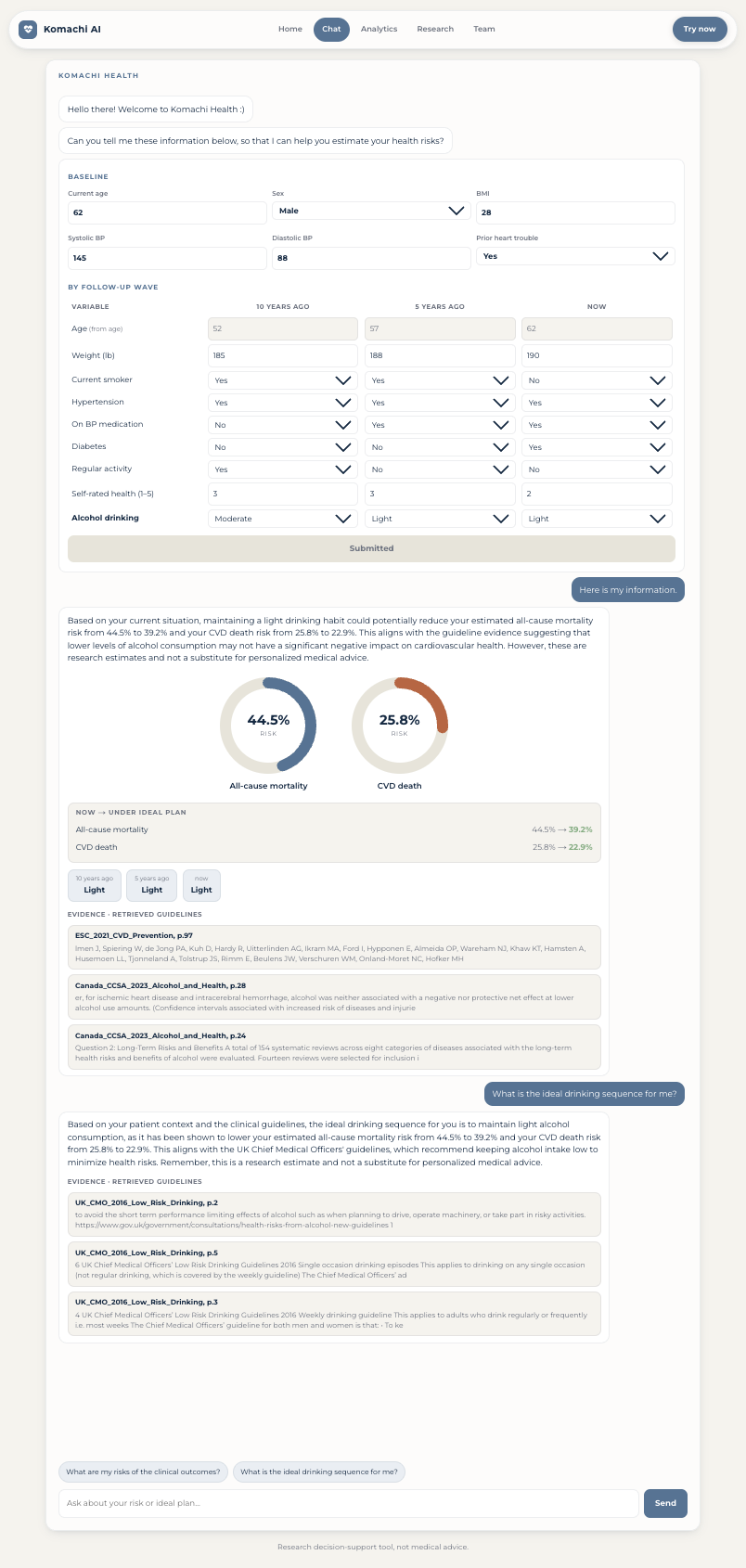
Komachi Health opens as a conversation. The chatbot greets the user, then asks for their information through a structured table of the variables the model was trained on, organized across time ("10 years ago", "5 years ago", "now"). From that input it does four things:
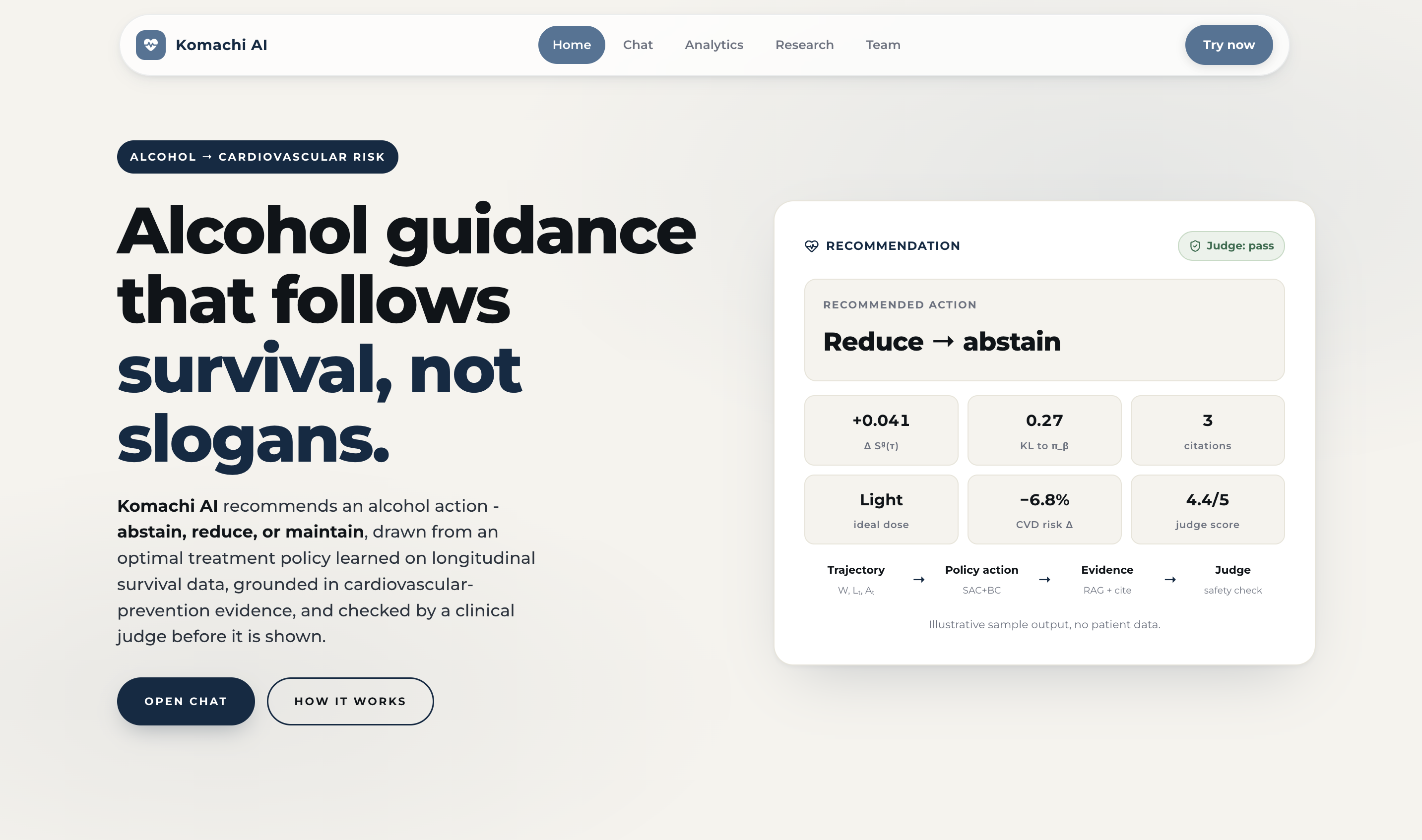
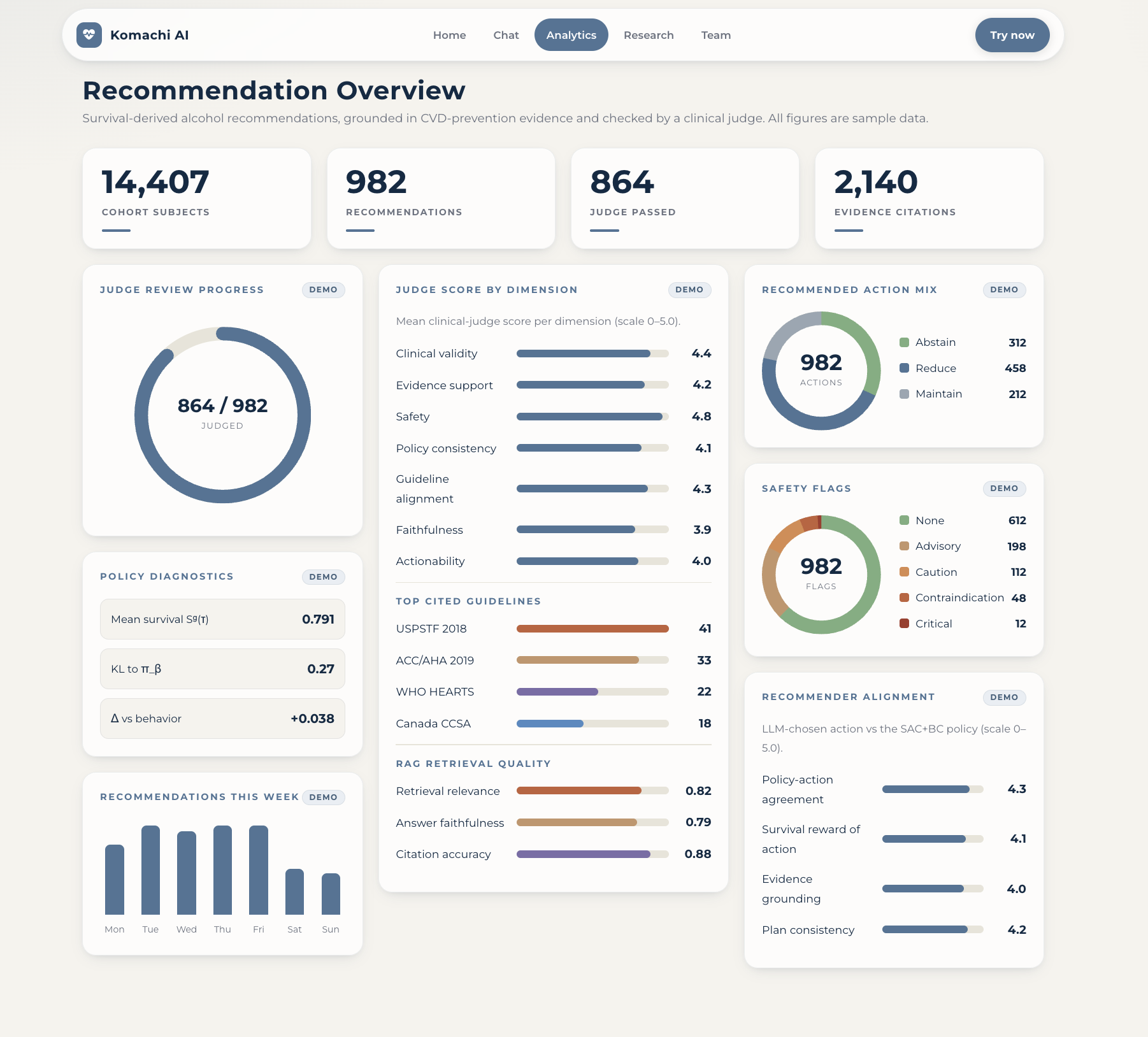
- Estimates clinical-outcome risk: cumulative all-cause mortality and cardiovascular (CVD) death risk over the modeled horizon, from the trained survival model.
- Recommends a sequence of alcohol actions, one of {abstain, light, moderate, heavy} at each time point, from the learned policy.
- Re-estimates risk under that plan, so the user can see the before-and-after effect of following the recommendation.
- Grounds and checks each recommendation inside the conversation. The proposed trajectory is grounded in retrieved cardiovascular-prevention guidelines (RAG over ACC/AHA, ESC, USPSTF, WHO, and alcohol-specific sources), then checked by an LLM clinical judge that decides whether it matches the lowest-risk, evidence-backed option and returns a verdict with a verbatim citation. Nothing is shown until it passes this check.
The policy is learned on the NHEFS / NHANES I Epidemiologic Follow-up Study: 14,407 subjects tracked across four waves (1971 to 1992), with all-cause and CVD mortality as endpoints.
How we built it
The model: survival policy learning as inference
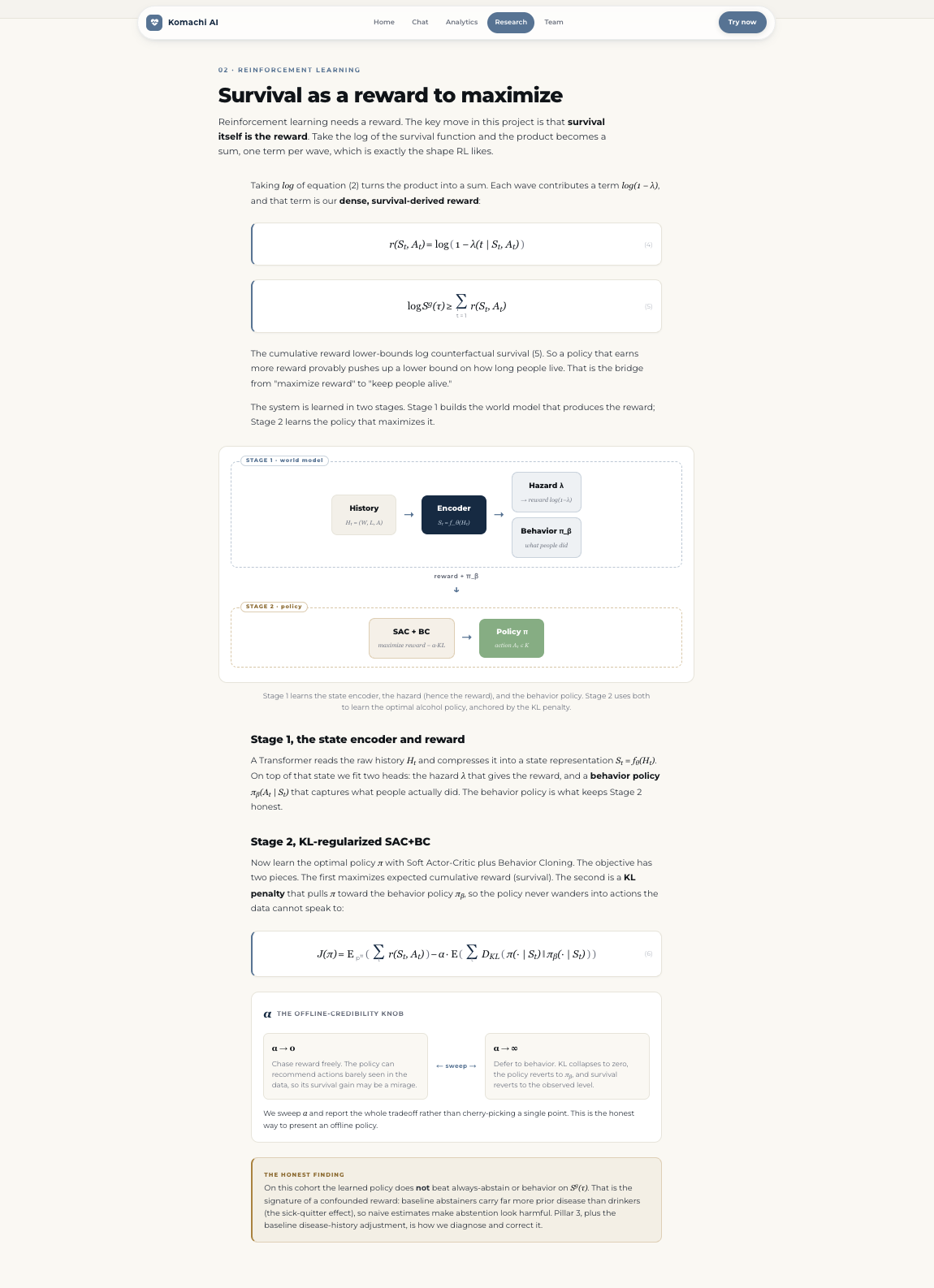
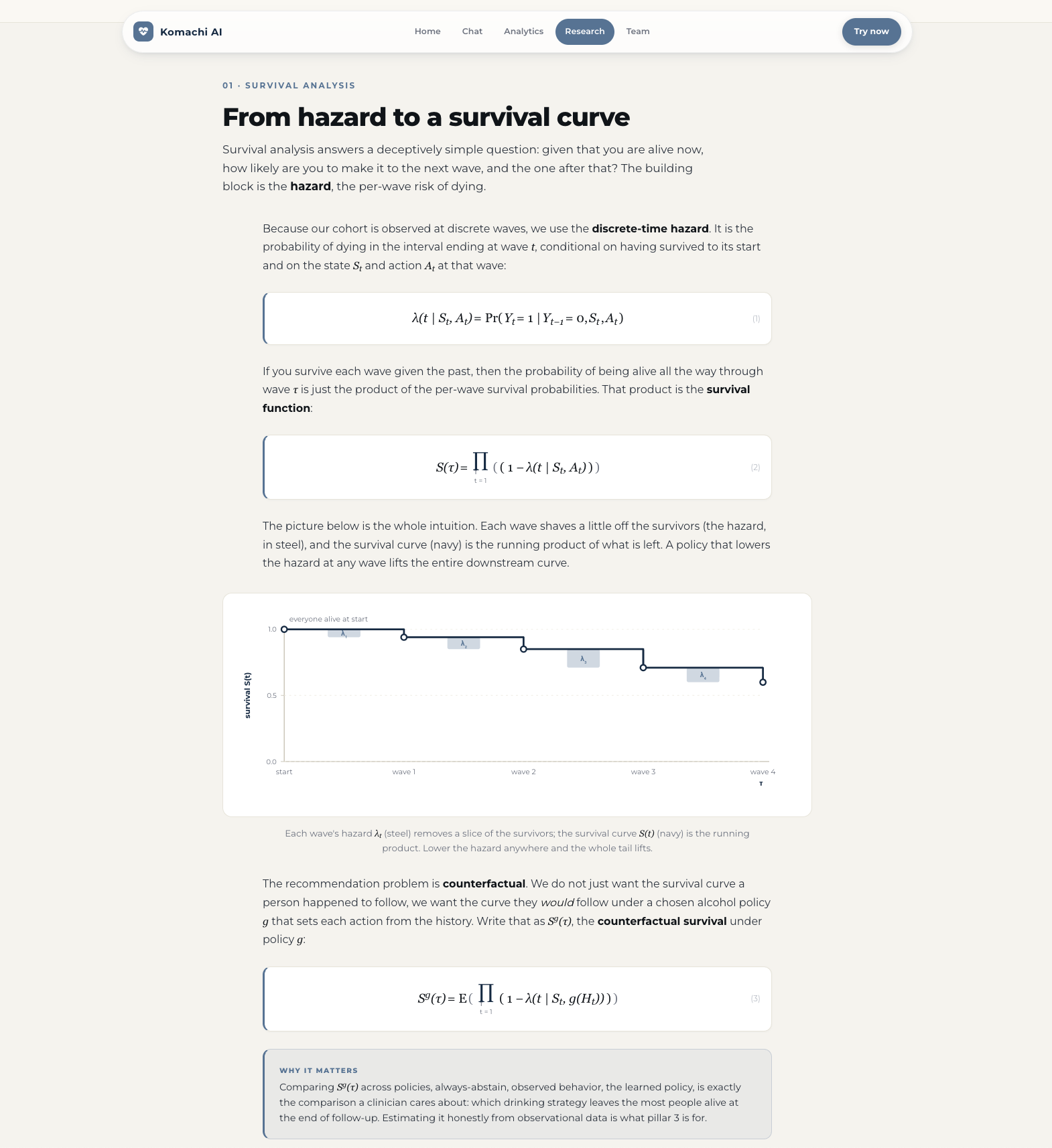
We use the paper's two-stage offline reinforcement learning method. It views survival policy learning through control as inference, with the optimality variable $O_t = 1 - Y_t$ (the patient survives interval $t$). This gives a dense reward, the log of one minus the hazard:
$$ r(S_t, A_t) \;=\; \log\bigl(1 - \lambda(t \mid S_t, A_t)\bigr), $$
where $\lambda(t \mid S_t, A_t)$ is the discrete-time hazard of the event in interval $t$ given state $S_t$ and action $A_t$. The reward is not a clinician-chosen heuristic. It is derived from the survival likelihood itself, which is what gives the learned policy its statistical grounding.
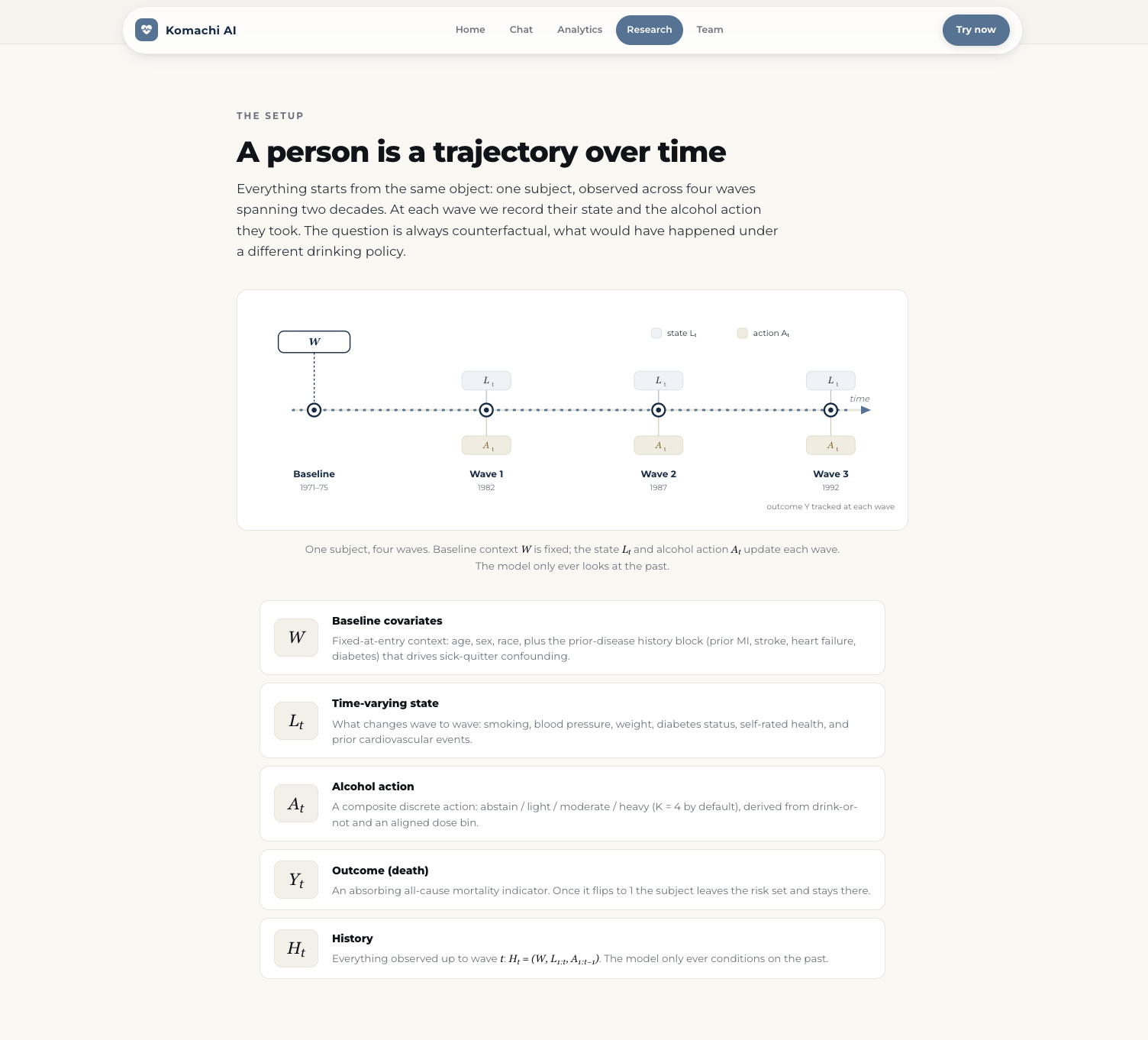
Stage 1 learns a state representation and the survival reward. We train an autoregressive state encoder that approximates the Markov property over the observed history,
$$ S_t = f_\theta(H_t), \qquad H_t = \bigl(W,\; L_{1:t},\; A_{1:t-1}\bigr), $$
together with the hazard $\lambda(t \mid S_t, A_t)$ and a behavior policy $\pi_\beta(A_t \mid S_t)$ that captures what was actually done in the data.
The reward connects to counterfactual survival. By the g-formula,
$$ \mathbb{E}{S_t,A_t \sim p^\pi}!\left[\prod{t=1}^{\tau}\bigl(1 - \lambda(t \mid S_t, A_t)\bigr)\right] \;=\; S^g(\tau), $$
and by Jensen's inequality the expected cumulative reward lower-bounds the log counterfactual survival:
$$ \mathbb{E}{S_t,A_t \sim p^\pi}!\left[\sum{t=1}^{\tau} r(S_t, A_t)\right] \;\le\; \log S^g(\tau). $$
Maximizing the reward therefore raises a lower bound on survival.
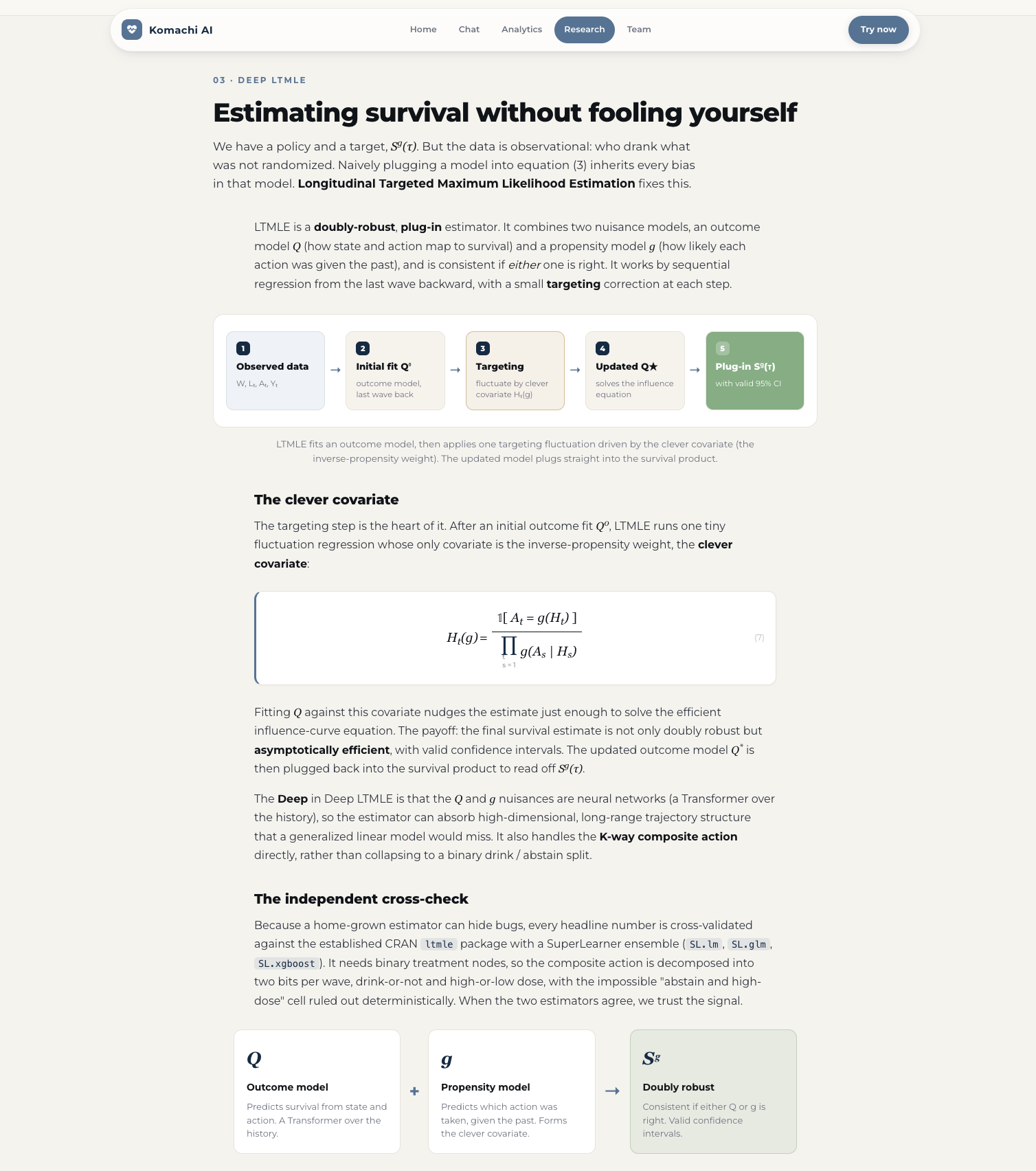
Stage 2 learns the policy with SAC+BC. Because we train entirely offline from observational data, the policy must not drift into actions the data never observed, where survival estimates are unreliable (a positivity problem). We use the paper's behavior-anchored, KL-regularized objective, a soft actor-critic with behavior cloning:
$$ \mathcal{J}(\pi) \;=\; \underbrace{\mathbb{E}{S{1:\tau},A_{1:\tau} \sim p^\pi}!\left[\sum_{t=1}^{\tau} r(S_t, A_t)\right]}{\text{cumulative survival reward}} \;-\; \underbrace{\mathbb{E}{S_{1:\tau} \sim p^\pi}!\left[\sum_{t=1}^{\tau} D_{\mathrm{KL}}\bigl(\pi(\cdot \mid S_t)\,\big|\,\pi_\beta(\cdot \mid S_t)\bigr)\right]}_{\text{KL anchor to behavior policy}} . $$
The first term maximizes the survival lower bound. The KL term keeps the learned policy $\pi$ within the support of the behavior policy $\pi_\beta$, which protects against positivity violations and keeps the offline estimates credible.
We evaluate the learned policy against baseline regimes (always-abstain, observed/natural, the behavior policy, and the learned SAC+BC policy) by their counterfactual survival $S^g(\tau)$, estimated with a Deep LTMLE estimator.
The action and the data
The action is a composite discrete action with $K=4$: {abstain, light, moderate, heavy}, where the dose bins come from an empirically quantile-aligned, coarsely-binned measure of ethanol intake. The baseline covariates $W$ (demographics, BMI, blood pressure, prior CVD) and time-varying covariates $L_t$ (smoking, hypertension, weight, diabetes, activity, self-rated health, per wave) follow the NHEFS schema. The at-risk mask $R$ is used only as a loss weight, never as a feature, to avoid leaking the outcome.
From research model to a product
The research code could only score the 14,407 training subjects. To serve new people, we built several pieces.
- Checkpoint persistence. We save the trained Stage-1 survival models (all-cause and CVD) and the Stage-2 actor, with the exact feature schema and normalization, so an arbitrary profile is encoded the same way as in training.
- A new-patient inference service that builds the encoder input $x_t = [W, L_t,\, \text{onehot}(A_{t-1})]$ from a person's entered variables, rolls the hazard forward, and returns the cumulative risk
$$ \widehat{\text{risk}} \;=\; 1 - \prod_{t=1}^{\tau}\bigl(1 - \lambda(t \mid S_t, A_t)\bigr) $$
for both all-cause ($Y$) and CVD ($Y^c$), and queries the actor for the recommended action at each wave.
- A FastAPI backend exposing
/risk,/recommend, and a/chatrouter, with every interaction logged in the cohort's data schema. - A conversation-first Next.js frontend: the scripted greeting, the in-chat variable-entry table with an age auto-calculator, risk plots, and before-and-after action plans.
- The evidence and safety layer, wired into the chat: a RAG retriever over 12 guideline PDFs and an LLM clinical judge that decides, in conversation, whether a recommended trajectory matches the lowest-risk evidence-backed option, and returns a verdict with a verbatim guideline citation. The recommender, retriever, and judge run together, so the final answer is optimized for survival, cited, and checked before it reaches the user.
Challenges we ran into
Offline credibility (positivity) was the central issue. A naive policy will recommend actions that barely appear in the data, where survival estimates are unreliable. The KL anchor to $\pi_\beta$ is our guard, and we spent time reasoning about where the conservatism should live: at the policy (SAC+BC) or at the value function (CQL).
The data was messy and provisional. Alcohol dose has a food-frequency-questionnaire scale break across waves, so absolute grams per day are not comparable; we quantile-align doses onto a common scale before binning. We also fixed a subtle label leak (any "alive" flag fed to the encoder leaks the outcome) by using the at-risk indicator strictly as a loss weight, and we handled informative missingness with carry-forward imputation.
Action positivity forced a design choice. A full action grid (beverage type by dose) thinned the per-action propensities below what offline RL can support, so we collapsed it to a dose-only $K=4$ action.
The gap between a research model and a product was larger than expected. Training only saved lookup tables indexed by cohort subjects. Serving a new person meant persisting the actual weights and re-deriving the exact encoder-input construction, so that a known cohort subject reproduces its training-time policy. We then validated this, with 100% agreement on the per-wave actions.
Finally, the full-stack plumbing took real work: port conflicts with the LLM server, browser and dev-server caching that hid UI changes, CUDA-versus-CPU device handling, and keeping user-entered health data out of version control.
Accomplishments that we're proud of
We took a causal-survival-RL method from a paper and turned it into a working pipeline, from raw longitudinal data to a live chatbot that returns personalized survival and CVD risk and a recommended drinking plan.
Our new-patient scorer reproduces the trained policy exactly on held-out cohort subjects, which gives us confidence that the product path is faithful to the research model.
The system is fast and lightweight. The survival and policy models are small, so risk estimates run in well under a millisecond on CPU, with no GPU needed for the interactive experience.
The recommendations are grounded. Each one traces back to a reward derived from the survival likelihood and an objective that lower-bounds counterfactual survival, and each passes an evidence-grounding and clinical-judge check before it is displayed.
What we learned
Control as inference unifies the reward design. Treating survival as the optimality variable turns the usual ad hoc choice of reward into a derivation: $r = \log(1-\lambda)$ follows from the survival likelihood, and its cumulative sum lower-bounds $\log S^g(\tau)$.
Offline RL is mostly about credibility, not optimization. The hard part is keeping the policy inside the data's support. We learned the difference between policy-constraint methods (SAC+BC, which keeps the actor close to $\pi_\beta$) and value-pessimism methods (CQL, which penalizes the critic on out-of-distribution actions), two routes to the same positivity guarantee.
Causal inference requires care with the data. Label leakage, informative missingness, unequal time intervals, and provisional measurements each quietly break a naive model. Getting the modeling contract right mattered more than model size.
Productizing research is its own task. The distance between "the model trains" and "a stranger can get a faithful estimate from it" was real engineering: checkpointing, reproducible feature construction, and validation against the source model.
What's next for Komachi Health
Next, we plan to expand Komachi Health beyond alcohol consumption to other chronic conditions, including hypertension, diabetes, obesity, and dyslipidemia. This is not a niche problem: chronic diseases drive most illness, disability, death, and healthcare spending in the U.S., while noncommunicable diseases kill more than 43 million people worldwide each year. By turning prevention into personalized, scalable guidance, Komachi Health aims to reduce this burden at national and global scale.
Concretely, our roadmap toward that vision is as follows.
- Generalize the action space from alcohol to multiple modifiable interventions, and their interactions, so a single policy can reason jointly across hypertension, diabetes, obesity, and dyslipidemia management, on more cohorts and outcomes.
- RL-posttrain the language recommender (GRPO) directly against the Stage-1 survival reward, so the language agent is aligned with the optimal policy and the words it speaks follow the survival model.
- Tighten the causal model (v2): an explicit censoring node with inverse-probability-of-censoring weighting, calibrated and uncertainty-aware risk outputs, and competing-risk handling for CVD.
- Improve cross-population robustness by extending the paper's cross-regional generalization experiments, so the policy transfers across populations with different baseline dynamics.
- Scale the deployment to a GPU box for the larger LLM components, and pursue clinician-facing validation.
Our goal is to make personalized, evidence-based guidance for long-term health usable by anyone.
Built With
- llm
- python



Log in or sign up for Devpost to join the conversation.