Inspiration
Splitting a check still ends with one person opening Venmo and the other person spelling out their username letter-by-letter while everyone else stares at the bill. Wallets keep getting more powerful, but the act of paying a human hasn't really changed since 2014. We wanted the friction to be zero — no usernames, no QR codes, no addresses on the clipboard. You already know who you're paying because you're looking at them. So we asked: what if your camera was the address book, your voice was the keypad, and the only thing you had to do was point and speak?
That question turned into Kolana.
What it does
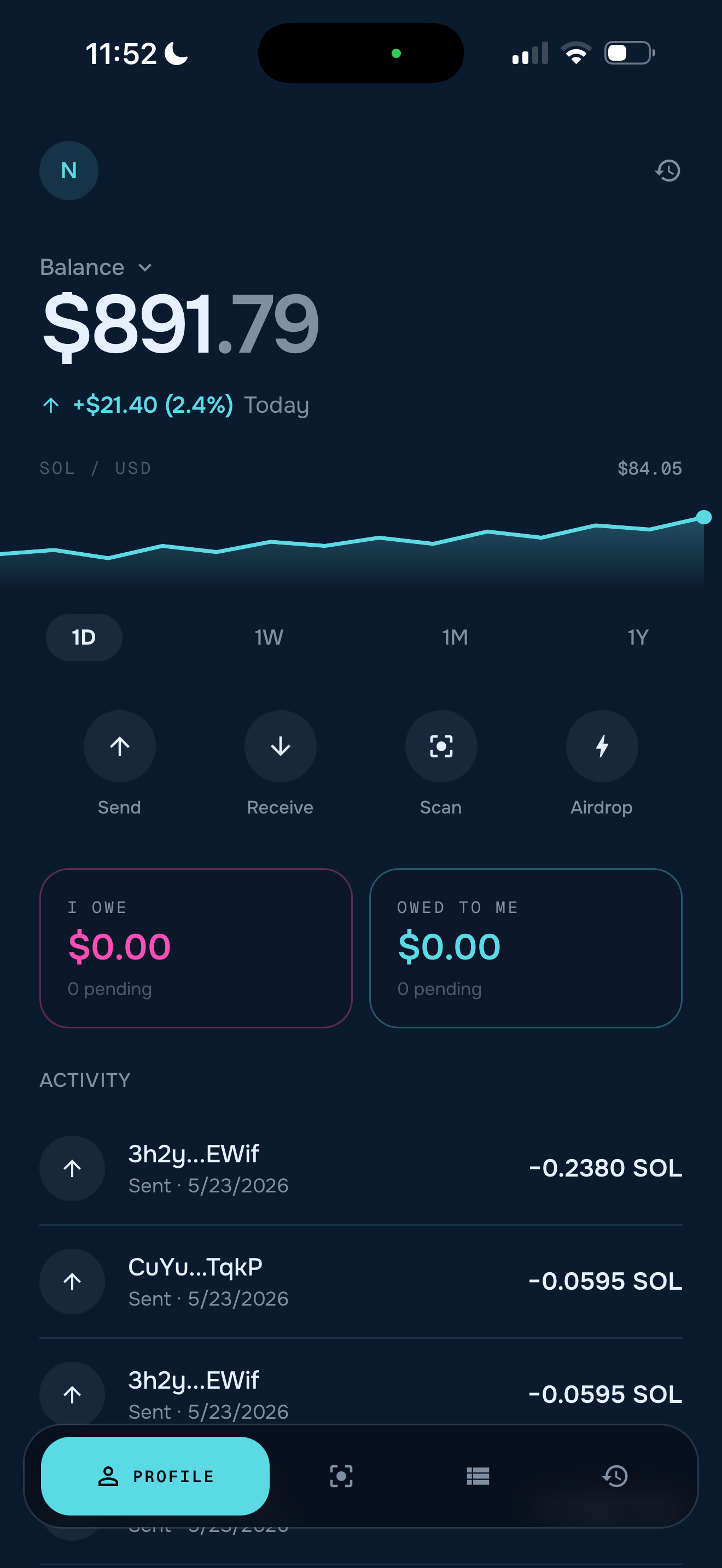
Kolana is a Solana wallet that recognizes the people you owe.
- Look — Open the app and aim the camera at a friend. We detect their face, run it through Atlas Vector Search, and surface the matching contact in under a second (with a confirmation step for low-confidence matches).
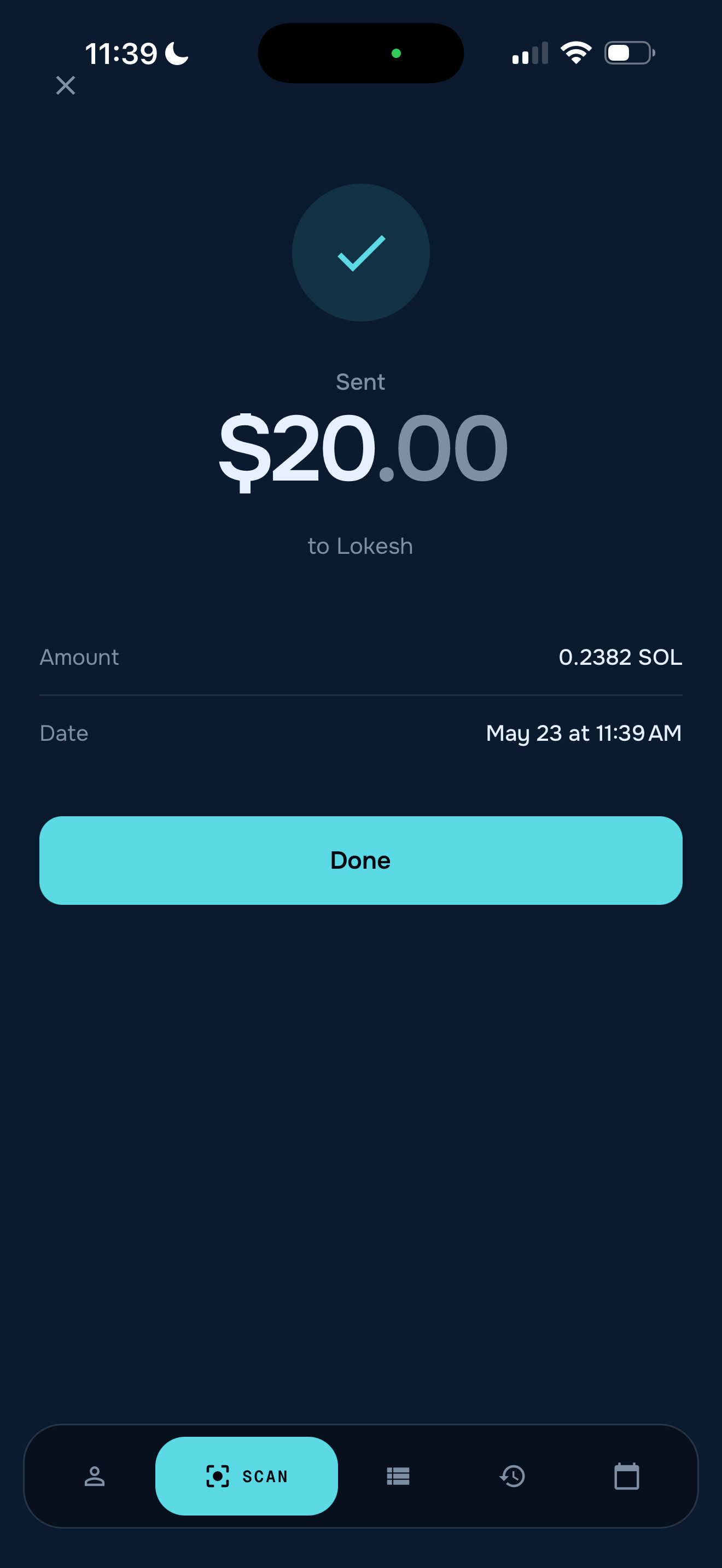
- Speak — Tap the mic and say what you want. "Pay them twenty bucks." "Send fifty by Friday." "A grand, on the fifteenth."
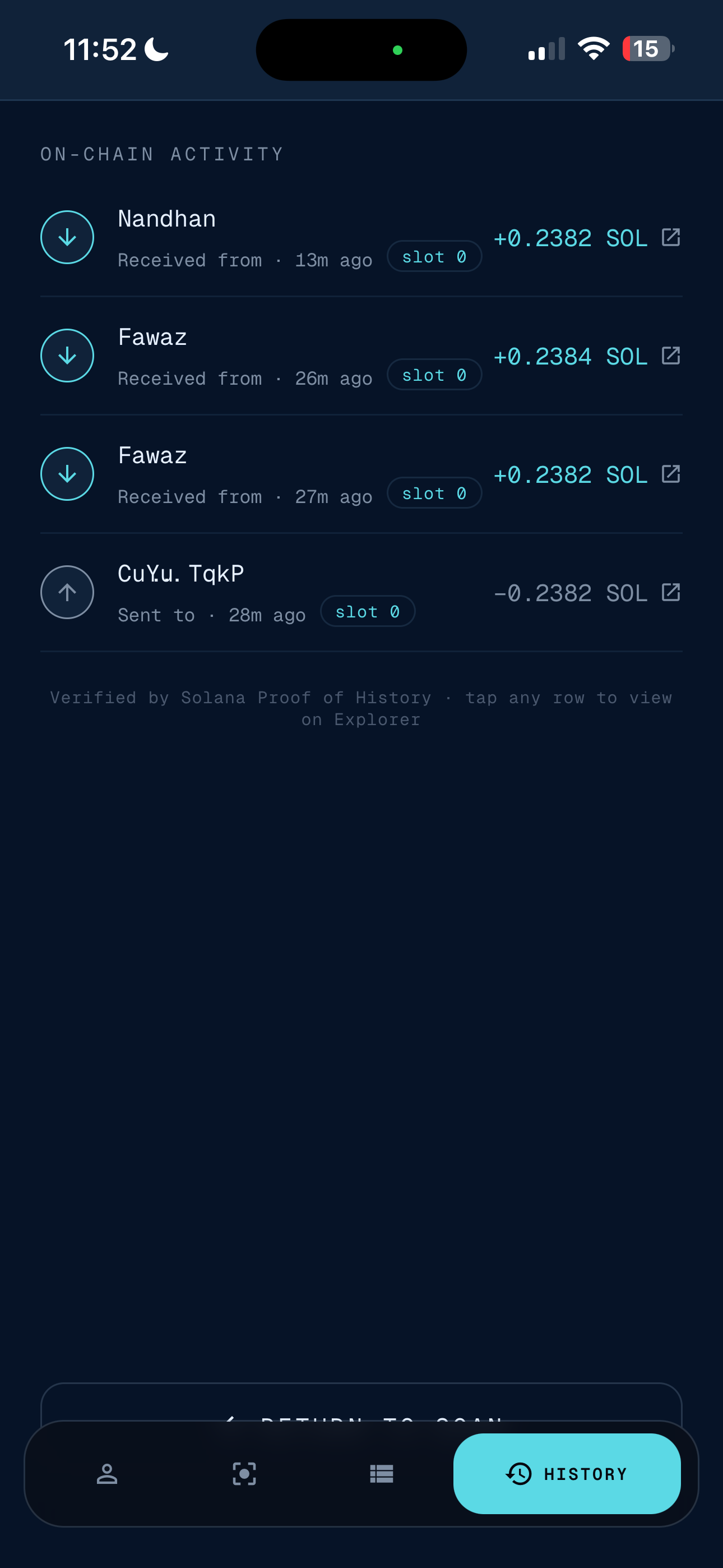
- Paid — If it's an immediate payment, Solana settles in ~400 ms on devnet. If you specified a date, Kolana schedules the payment, adds it to the in-app calendar, and reminds you when it's due.
Other things we shipped:
- Onboarding that sets up a Solana wallet, enrolls your own face, and adds your first contact in under a minute.
- Voice fallback to keypad so a noisy bar doesn't break the flow.
- Insufficient-funds queueing — under-funded payments get saved as debts and replayed when the wallet refills.
- Demo mode for hackathon judges (no real lamports get burned).
How we built it
Mobile — Expo / React Native (SDK 54), expo-router for navigation, expo-camera for the live face feed, expo-av for mic capture, @solana/web3.js for transaction signing, and zustand for state. The UI is a deliberately monospaced, terminal-flavored design system because crypto apps usually look like fintech and we wanted ours to feel like infrastructure.
Face recognition — InsightFace's buffalo_l ArcFace model produces a 512-dim L2-normalized embedding for every face the camera sees. We store enrolled embeddings in MongoDB Atlas with a vector index and query with cosine similarity:
[ \text{sim}(\mathbf{e}{\text{query}}, \mathbf{e}{\text{contact}}) = \mathbf{e}{\text{query}} \cdot \mathbf{e}{\text{contact}} \in [-1, 1] ]
Two thresholds gate the UX: high-confidence matches ($\text{sim} \geq 0.85$) skip straight to the payment flow, mid-confidence matches ($0.60 \leq \text{sim} < 0.85$) trigger a "Is this Alex?" confirmation, and anything below 0.60 is treated as a stranger.
Speech → intent — Audio recorded on the device is uploaded as multipart/form-data to a FastAPI endpoint, transcribed by ElevenLabs Scribe v1, then passed to Google Gemini 1.5 Flash with a strict JSON-output prompt. Gemini handles colloquial amounts ("five bucks", "a grand", "twenty dollars") and resolves relative dates ("by Friday", "next Monday", "in three days") into ISO YYYY-MM-DD. A regex fallback keeps the system alive even when the LLM is unreachable.
Payments — Solana devnet via @solana/web3.js. SOL price is fetched from CoinGecko, cached for 30s, and used to convert the user's spoken USD amount into lamports right before signing.
Backend — FastAPI with five routers (/recognize, /contacts, /voice, /payments, /sol/price), MongoDB Atlas for storage, deployed to a DigitalOcean droplet with CPU-only ONNX inference so it fits in a $5/mo box.
Challenges we ran into
- The mic was haunted. Our first cut auto-started recording the instant a face matched and auto-stopped after exactly 10 seconds. It felt like the app was interrupting you mid-sentence. We rewrote it as a manual tap-to-start / tap-to-stop button with a 60-second safety net.
- Gemini quietly falling back to regex. Our droplet was returning
intent: "unclear"for things like "pay twenty bucks" — turns out thegoogle-generativeaipackage wasn't installed in the deployed image, so every request was hitting the dumb numeric regex fallback. The giveaway was a suspiciously consistentconfidence: 0.7(our hardcoded fallback value). Took an hour of staring before we caught it. - iOS vs Android audio formats.
expo-avrecords to.cafon iOS and.m4aon Android, and ElevenLabs Scribe wants the correct MIME type. We had to introspect the extension on the client and setaudio/x-cafvsaudio/m4avsaudio/wavper platform. - Atlas Vector Search index naming. Our recognize endpoint silently returned zero matches for a full afternoon because the code referenced one index name and Atlas had been provisioned with another. No error, just an empty result set — the worst kind of bug.
- Face matching on bad lighting. Initial threshold of 0.5 cosine similarity gave us cousin-level false positives. Pushing to 0.85 for the auto-flow and 0.60 for the confirmation flow was the sweet spot.
- Silent UX failures. When voice transcription succeeded but Gemini couldn't extract an amount, the UI just snapped back to "Tap to speak" with no explanation. Adding explicit feedback states ("No amount detected", "Network error", "Didn't catch that") was a small change with huge UX impact.
Accomplishments that we're proud of
- Sub-second face-to-payment loop. From the moment the camera locks onto a face to the moment you can speak an amount: less than a second. The "wow" reaction in user tests was unanimous.
- Voice that actually understands humans. "Pay them a twenty," "fifty bucks by Friday," "a grand on the fifteenth" — all parse correctly into structured intents, including a future-dated scheduled payment.
- A real onboarding flow, not a hackathon stub: wallet generation, biometric self-enrollment, first contact added.
- Holding the whole pipeline — vision, speech, LLM, blockchain — in one FastAPI process under 200 MB of RAM, with graceful degradation at every layer (stub embeddings, regex fallback, demo mode).
- It feels finished. Custom design system, animated transitions, voice confirmations from ElevenLabs TTS, a proper queue tab and payment history. It looks like a product, not a demo.
What we learned
- Vector search collapses the gap between "biometric identification" and "database lookup." Once you have good embeddings, the database does the hard part for you.
- LLMs are excellent intent parsers but you have to constrain them aggressively — strict JSON schemas, today's date in the prompt for date resolution, and a deterministic fallback for when the model is slow, expensive, or down.
- Silent failures are the worst kind of failure. Every state that could be "we tried something and it didn't work" needs an explicit visible state, or your users will think your app is broken.
- Multimodal apps live or die on latency. Camera + STT + LLM + chain RPC is four network round-trips. Caching the SOL price, parallelizing face capture with embedding upload, and one-shot audio→intent endpoints kept the experience snappy.
What's next for Kolana
- Mainnet + USDC. Devnet is for demos; the real product is USDC stablecoin payments on Solana mainnet.
- Group payments. "Pay these three people $20 each" — multi-face detection plus a single-tap split.
- NFC handoff. For when the person you're paying is across the room or behind a counter.
- On-device face recognition. Move InsightFace inference to CoreML/TFLite so the camera never leaves the phone — better privacy, lower latency, works offline.
- Reputation graph. Built on top of the contact-and-payment data you generate naturally, your "wallet history" becomes a portable, opt-in trust signal.
- Calendar sync. Push scheduled payments into iOS / Google Calendar so reminders fire even when the app is closed.
Built With
- digitalocean
- fastapi
- google-gemini
- insightface
- mongodb-atlas
- python
- react-native
- solana
- typescript



Log in or sign up for Devpost to join the conversation.