-
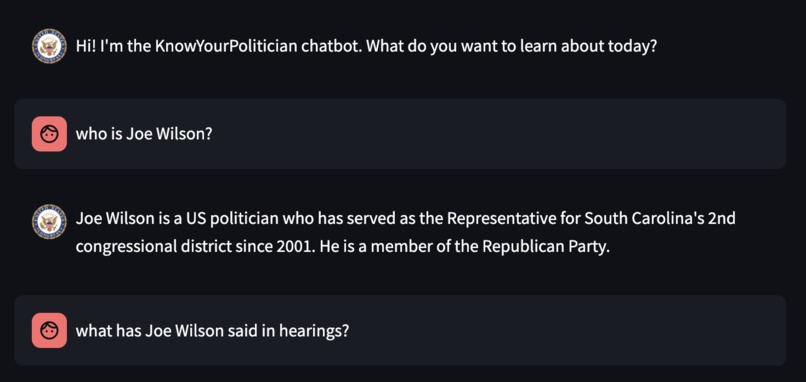
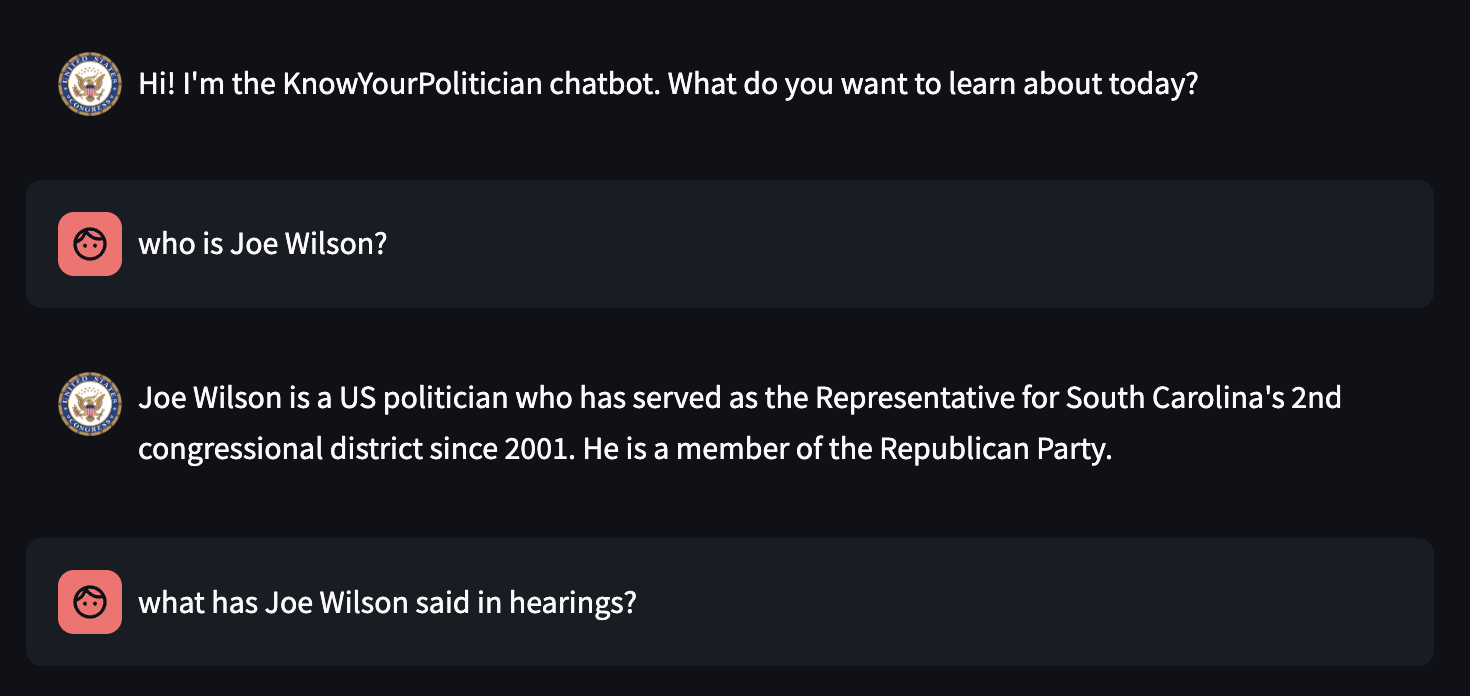
Example UI of the chatbot!
Inspiration
What actually happens behind the closed doors of Congress? Who are the senators representing me, and what actions are they actually taking with regards to topics that are important to me? While information on the full legislative process is publicly available on online websites, they are often too hard to parse through and read. Who spends their Saturday going through 60-page congressional reports anyway?
We believe a chatbot-style UI that provides answers to the user's burning questions will bridge the gap between Congress and voters, increase transparency on the legislative process, and help voters make more informed decisions during elections. Hence, KnowYourPoliticians was born.
What it does
Ask any question related to the US legislative system (e.x. Who is the senator of North Carolina? What has he said about climate change? What gun control bills have he supported?) and our chatbot-style UI will give you responses based on publicly available transcripts of hearings, speeches, and bills and also cite the exact source the response was based off of.
In addition, the Premium version of the app will provide further ML-driven insights in response to the question. For example, ask "How has Joe Wilson's opinion on climate change changed over time?" and you'll also see a graph of his sentiment towards climate change year-over-year. Ask about a senator's party affiliation, and you'll see a voting pattern chart that shows who the senator usually votes with and against.
How we built it
We primarily relied on Retrieval Augmented Generation (RAG) to create vector databases storing chunks of congressional reports, transcripts of hearings, past bills, etc. dating back to 2019. We scraped this legislative data mostly from govinfo.org. Each type of document from each year was embedded into its own vector database in order to minimize retrieval/inference time during deployment.
Once we create the vector databases, we used Langchain to access the OpenAI endpoint for retrieval and response generation. Lastly, the UI was rendered using Streamlit's chat application API, which allows us to store and display chat history in session.
For temporal sentiment analysis, we retrieved top 3 relevant chunks across each year, and ran sentiment analysis on each OpenAI response generated. We then plotted the change in sentiment over time on a Streamlit bar graph that complimented the OpenAI response.
For the voting pattern classification, we let every congressperson represent a node on a a weighted graph and weight each edge by the number of times those two congressmen vote together. The resulting adjacency list is our affinity matrix, and when we compute a spectral embedding, in theory we can visualize similarities in voting patterns in lower dimensional space (R2)
Challenges we ran into
There are a few of the unique challenges that this project runs into:
- Data Scraping: 1. Most of the text/pdfs we scraped aren’t actually posted on the gov websites for some reason so we had to reverse engineer the backend to get the urls to scrape text from. 2. Also many methods of scraping didnt work bc the gov websites would block them
- Embedding into Vector DBs: inserting embeddings into vector DBs caused a lot of issues because there was an OpenAI rate limit on number of tokens processed per minute. As a result, we had to use a workaround to upload embeddings to vector DBs with a delay in between batches of document chunks.
- Lost Information in Long Context Lengths: Because congressmen speak for long periods of time in many of these documents, the 1500 size chunks often do not contain information about who is speaking at the moment. We thus had to do extra metadata tagging to add information about who's talking in a given document chunk and filter our queries accordingly.
Accomplishments that we're proud of
We're proud of creating a full-stack chatbot that not only achieves its purpose but adds technical improvements to make the results even more accurate for end users.
What we learned
We learnt a lot about how Langchain works, and how it processes text to store in vector DBs.
What's next for KnowYourPoliticians (KYP)
- We want to extract and ingest more data into our local vector DBs
- We want to improve on and add more ML-driven analytical tools for our premium feature
- We want to make retrieval and inference much more accurate and quicker.
Built With
- langchain
- openai
- python
- streamlit

Log in or sign up for Devpost to join the conversation.