KleanSQL: Query Your Data at the Speed of Thought
Inspiration
Every data analyst knows the pain: you have a CSV file with thousands of rows, and you need insights fast. Traditional SQL requires learning complex syntax, and even then, you're often stuck debugging queries for hours. We wanted to bridge the gap between natural language and data analysis, making powerful analytics accessible to everyone—not just SQL experts.
The inspiration came from watching teammates struggle with basic data questions during hackathons. "What's the average grade for female students?" shouldn't require writing SELECT AVG(G1) FROM students WHERE sex = 'F'. It should be as simple as asking the question in plain English.
What it does
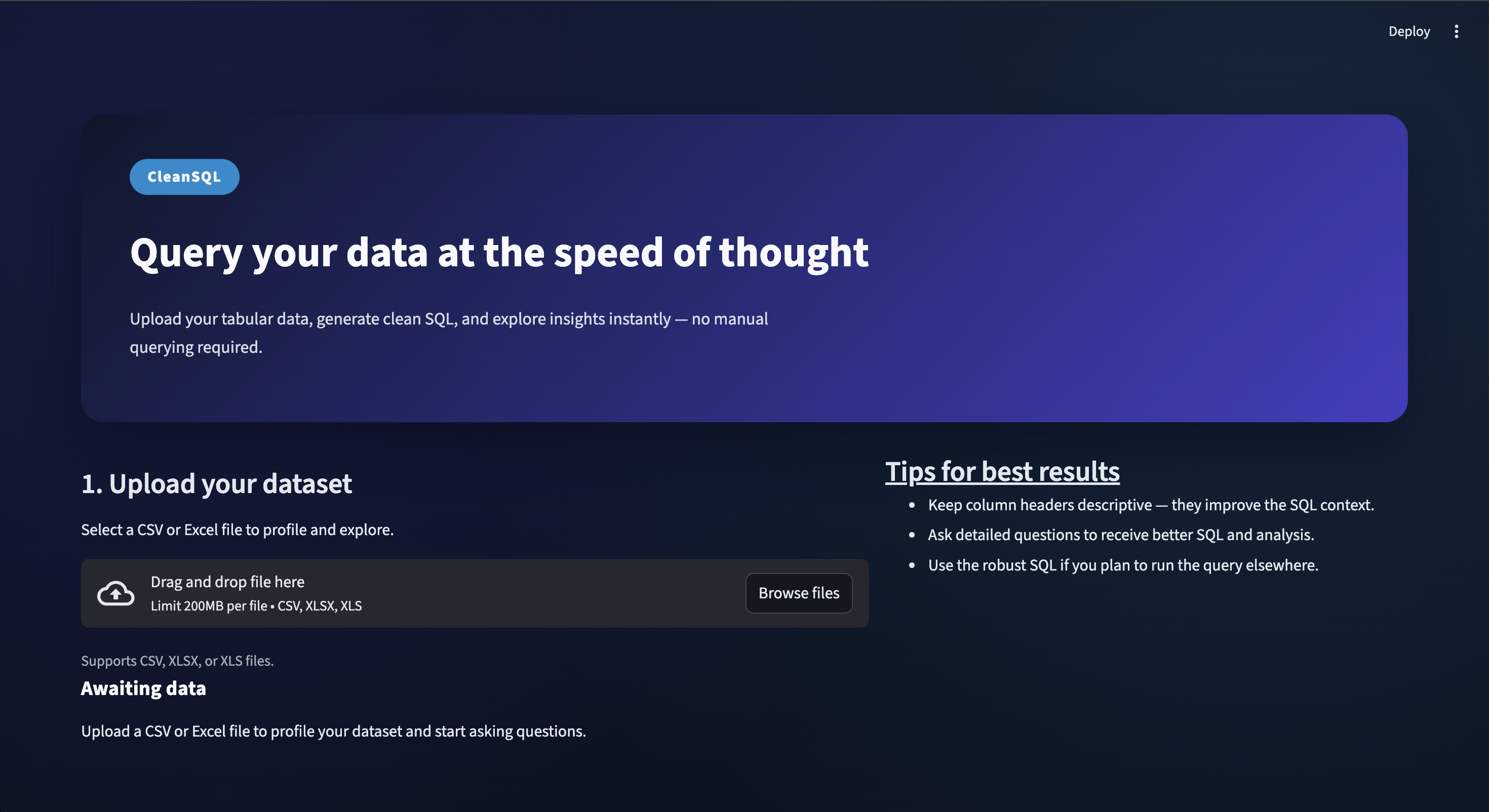
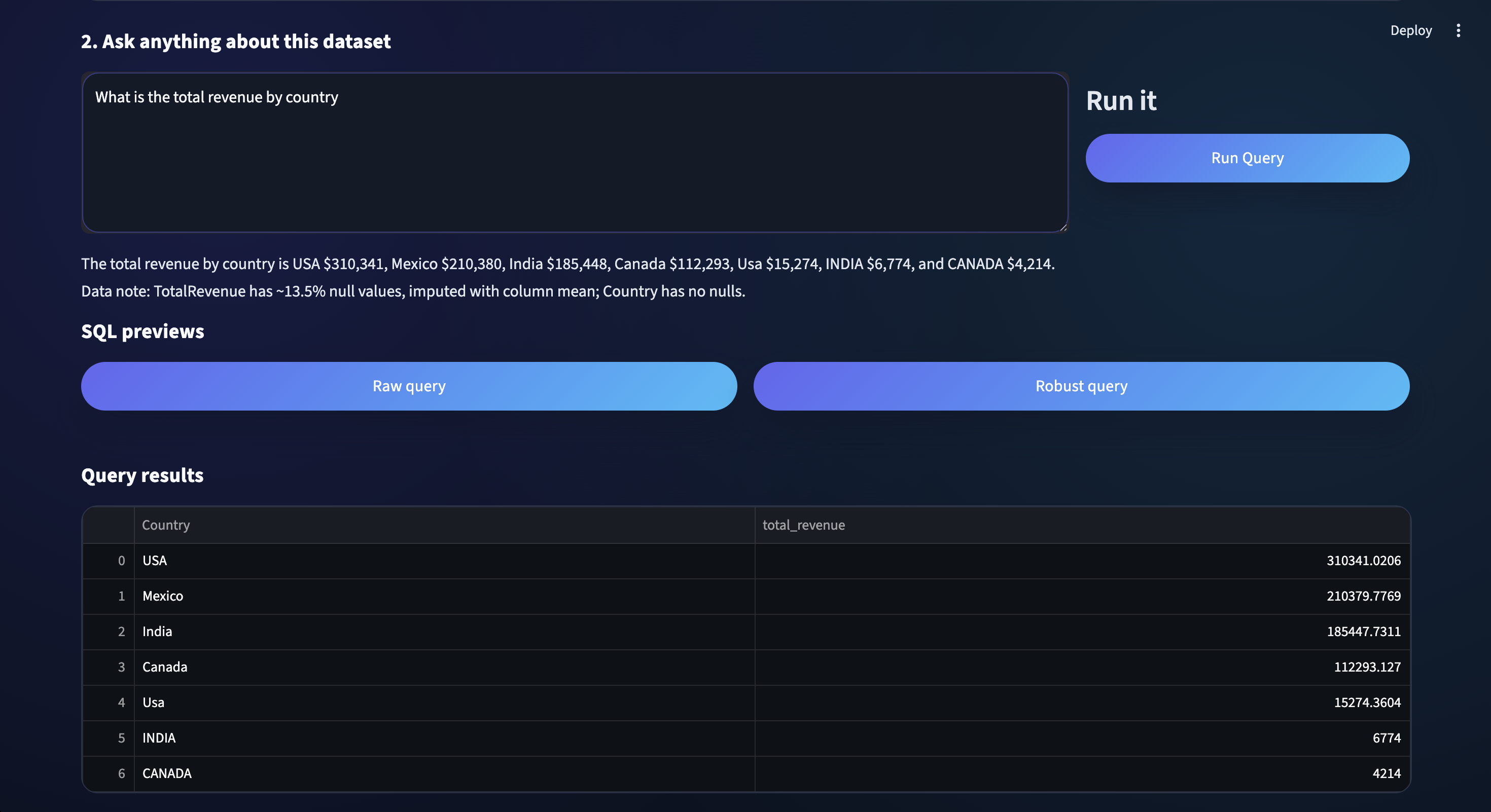
KleanSQL transforms messy CSV files into intelligent, queryable datasets through a beautiful web interface. Upload any CSV or Excel file, and instantly start asking questions in natural language:
- "What's the average salary by department?"
- "Show me students with grades above 15"
- "Which cities have the highest population?"
Behind the scenes, KleanSQL:
- Profiles your data using DuckDB for lightning-fast analysis
- Generates clean SQL automatically via Claude Sonnet 4
- Handles missing data with intelligent imputation strategies
- Provides robust queries that work even with messy datasets
- Offers follow-up suggestions to deepen your analysis
The platform delivers both raw SQL (for transparency) and robust SQL (with data cleaning) so you can trust your results and learn from the generated queries.
How we built it
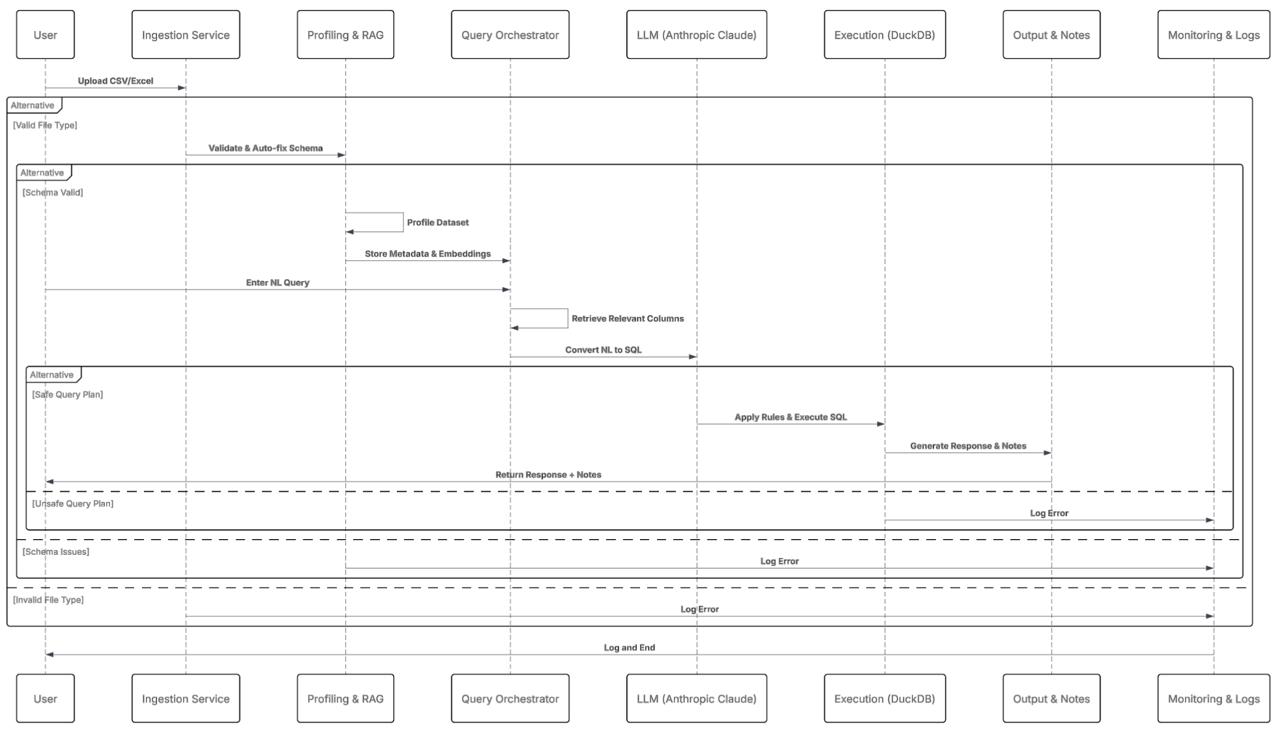
Architecture Overview: Our system follows a sophisticated pipeline that mirrors the sequence diagram:
Data Ingestion & Profiling (
profiler.py)- DuckDB-powered CSV analysis with automatic type detection
- Comprehensive statistical profiling (null ratios, outliers, distributions)
- Semantic type classification (numeric, categorical, datetime, boolean)
- Optional Weaviate integration for vector-based column search
LLM Integration (
llm_integration.py)- Anthropic Claude Sonnet 4 for natural language understanding
- Dual SQL generation: raw queries + robust queries with data cleaning
- Intelligent prompt engineering for consistent, safe SQL output
- JSON-structured responses with metadata and follow-up questions
Query Execution (
DataAssistantclass)- DuckDB in-memory database for sub-second query performance
- SQL sanitization and safety checks (read-only mode)
- Automatic result formatting and truncation
- Comprehensive error handling with user-friendly messages
Web Interface (
app.py)- Streamlit-based modern UI with custom CSS styling
- Real-time query processing with progress indicators
- Interactive SQL preview modals
- Responsive design with dark theme
CLI Support (
data_assistant/cli.py)- Command-line interface for power users
- Automated data cleaning and imputation
- Interactive Q&A sessions
- Batch processing capabilities
Key Technologies:
- DuckDB: High-performance analytical database
- Anthropic Claude: Advanced language model for SQL generation
- Streamlit: Rapid web app development
- Weaviate: Vector database for semantic search (optional)
- Pandas: Data manipulation and analysis
- Docker: Containerized deployment with Weaviate services
Challenges we ran into
1. SQL Safety & Validation
- Challenge: Preventing malicious SQL injection while allowing complex analytical queries
- Solution: Implemented comprehensive SQL sanitization, keyword filtering, and read-only mode enforcement. Added column existence validation and query complexity checks.
2. Data Quality & Missing Values
- Challenge: Real-world datasets are messy with missing values, inconsistent types, and outliers
- Solution: Built intelligent imputation pipeline with policies based on data types and null ratios. Created both "raw" and "robust" query modes—raw for transparency, robust for production use.
3. LLM Response Consistency
- Challenge: Getting reliable, parseable SQL from language models
- Solution: Developed sophisticated prompt engineering with JSON-structured responses, fallback mechanisms, and extensive response normalization. Added regex-based SQL extraction for edge cases.
4. Performance at Scale
- Challenge: Fast query execution on large datasets
- Solution: Leveraged DuckDB's columnar storage and vectorized execution. Implemented result truncation and efficient memory management.
5. User Experience
- Challenge: Making complex data analysis feel intuitive
- Solution: Created progressive disclosure with SQL previews, follow-up question suggestions, and comprehensive error messages. Built both web and CLI interfaces for different user preferences.
Accomplishments that we're proud of
Technical Innovations:
- Dual Query Generation: Raw SQL for learning + robust SQL for production
- Intelligent Data Profiling: Comprehensive statistical analysis with semantic type detection
- Vector-Based Column Search: Optional Weaviate integration for semantic column discovery
- Automated Data Cleaning: Smart imputation strategies based on data characteristics
User Experience:
- Natural Language Interface: Ask questions in plain English, get SQL + results
- Beautiful Web UI: Modern dark theme with responsive design
- Progressive Disclosure: Show SQL queries for transparency and learning
- Follow-up Suggestions: AI-powered question recommendations
Performance:
- Sub-second Query Execution: DuckDB's vectorized engine
- Memory Efficient: Streaming data processing with result truncation
- Scalable Architecture: Handles datasets from hundreds to millions of rows
Developer Experience:
- Multiple Interfaces: Web app, CLI, and programmatic API
- Docker Deployment: One-command setup with Weaviate services
- Comprehensive Testing: Unit tests and integration validation
- Extensible Design: Modular architecture for easy feature additions
What we learned
AI Integration Insights:
- Prompt Engineering is Critical: Small changes in prompts dramatically affect output quality
- Fallback Strategies Matter: Always have backup plans when LLMs fail
- Structured Outputs Work: JSON responses are more reliable than free-form text
Data Engineering Lessons:
- Profile First, Query Later: Understanding your data structure is crucial for good SQL generation
- Handle Edge Cases: Real-world data is messier than you think
- Performance Matters: Users expect instant results, even on large datasets
User Experience Discoveries:
- Transparency Builds Trust: Showing generated SQL helps users understand and learn
- Progressive Disclosure: Don't overwhelm users with all features at once
- Error Messages Matter: Clear, actionable error messages improve user experience significantly
Technical Architecture:
- DuckDB is Incredible: Fast, SQL-compliant, and perfect for analytical workloads
- Modular Design Pays Off: Separate concerns (profiling, LLM, execution) makes testing and debugging easier
- Containerization Simplifies Deployment: Docker Compose makes complex setups trivial
What's next for KleanSQL
Short-term Enhancements:
- Multi-table Joins: Support for relational queries across multiple CSV files
- Advanced Visualizations: Charts and graphs for query results
- Query History: Save and replay previous analyses
- Export Capabilities: Download results as CSV, PDF reports
Medium-term Features:
- Real-time Data Sources: Connect to databases, APIs, and streaming data
- Collaborative Analysis: Share datasets and queries with team members
- Custom Imputation Rules: User-defined data cleaning strategies
- Query Optimization: Automatic query performance tuning
Long-term Vision:
- Enterprise Features: Role-based access, audit logs, and compliance tools
- AI-Powered Insights: Automatic anomaly detection and trend analysis
- Natural Language Reports: Generate executive summaries from data
- Integration Ecosystem: Connect with popular BI tools and data platforms
Open Source Goals:
- Community Contributions: Open-source the core engine for community development
- Plugin Architecture: Allow third-party extensions and custom functions
- Educational Resources: Tutorials and examples for learning SQL through natural language
KleanSQL represents the future of data analysis—where powerful insights are just a question away. We're excited to continue building tools that make data accessible to everyone, not just SQL experts.
Built with ❤️ at CalHacks 12.0
Built With
- anthropic
- claude
- duckdb
- python
- rag





Log in or sign up for Devpost to join the conversation.