-
-
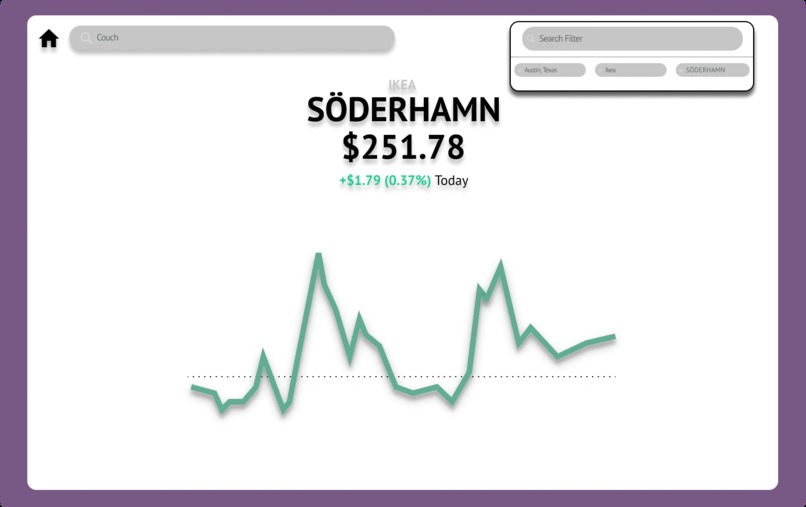
Web Demo
-
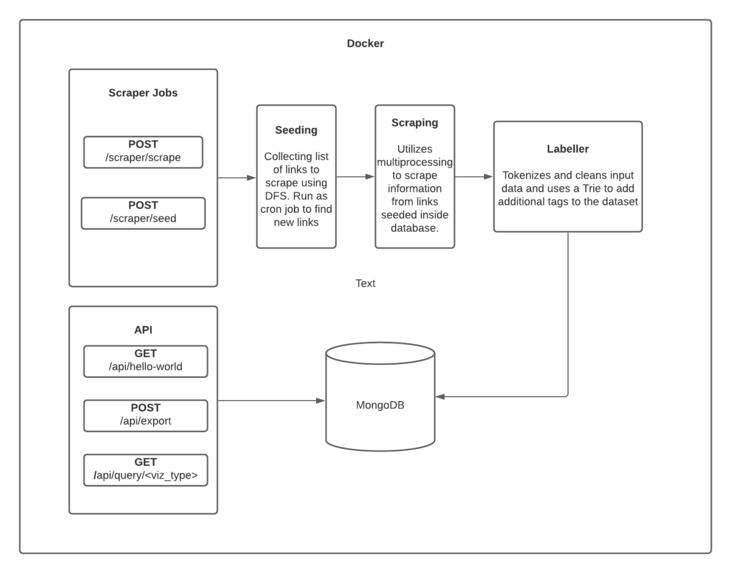
Web App Architecture
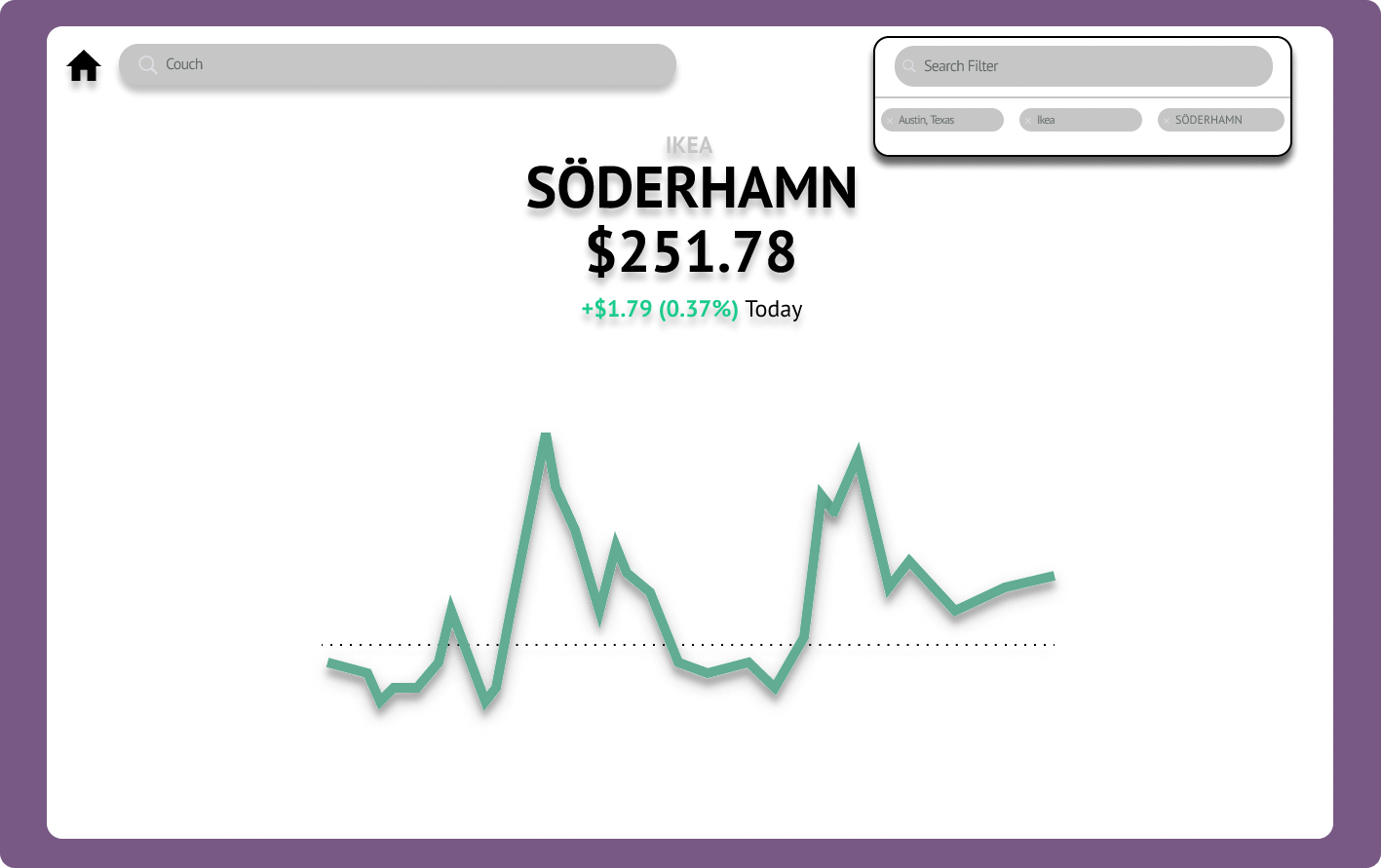

KLARITY
Dataset Link
https://github.com/philipk19238/klarity/tree/master/data
Inspiration
Many members of our team enjoy thrifting & buying used products but we've oftentimes had to bargain & haggle to acquire an item. This process oftentimes results in one party paying too much/too little and is overall an unpleasant experience. We thought it would be cool to build a solution that allows buyers to know if they're paying too much for a used good and inform sellers of the going market rate so they can correctly price their items.
What really solidified our decision is that we discovered that the used goods market is growing at a rapid pace and we believe our solution can encourage more people to "renew, rather than by new."
What it does
Klarity is an advanced search engine that tracks the price of used goods over time. Feel free to enter any query and Klarity will visualize the price trend results to you instantly!
The reason we are able to provide such data is because it is powered by a powerful web scraper that uses multiprocessing to scrape thousands of websites in mere minutes. Furthermore, we built an advanced labeller & tagger that goes through our scraped results and adds additional tags to the data to provide our users with additional context.
How we built it
Architecture

The Klarity backend is comprised into three main sections - scraper, labeller, and API.
Scraper
https://github.com/philipk19238/klarity/tree/master/api/app/scraper
Our scraper uses a two step process to parse websites. First, it seeds our Mongo database with tens of thousands of "scrape-able" links using a DFS algorithm. This process is designed to be a background job that scrapes new links for our scraper to process and will stop once it detects a link it already scraped. Afterwards, we paginate over those results and utlize multiprocessing & caching to quickly scrape, label, and save the data into our database. We originally designed this scraper to be asynchronous but could not implement due to time constraints
Labeller
https://github.com/philipk19238/klarity/tree/master/api/app/labeller
Our labeller also uses a two step process that cleans & adds additional tags to our dataset. The cleaning process consists of four steps:
- Tokenize the input sentences into individual words
- Convert everything to lower case
- Filter punctuation
- Filter out stop words (ex: the, is, how, etc)
Afterwards, it uses a Trie to search for unique labels. We initialize our Trie with precoded constants with tags that represent the majority of the data that we scrape. We would then iterate the title & the description of the used goods post over the Trie to label the data.
API
https://github.com/philipk19238/klarity/tree/master/api/app/api
Our API consists of two main endpoints:
- /api/export
- /api/query
Export
Our export endpoint converts the data inside our database into a CSV file and streams the bytes to the user for download
Query
Our query endpoint accepts a parameter of type mean, median, min, and max as a metric to visualize the price trend and accepts the following query parameters:
- type
- condition (new, like new, good, etc)
- material
- home_location (dining, living, patio, etc)
- color
- mattress_size (king, queen, full, twin, etc)
It will then filter our database and group results by date. We planned on adding more visualizations such as item comparisons and location clustering but ran out of time. This information is visualized on our React.js frontend.
Technologies Used
Database
- MongoDB
Backend API
- Flask + Swagger
Frontend Framework
- React.js
Labeller
- nltk + custom Trie
Devops
- Docker, Makefile
Scraping
- requests + BeautifulSoup + multiprocessing
Challenges we ran into
We ran into a lot of difficulties with scraping data. Our scraper processed links too quickly and would oftentimes trigger anti-scraper measures. We did our best to adapt by switching user agents constantly and randomizing time between requests. We were able to scrape ~10,000 rows of data but can definitely scrape a lot more if we didn't have such limitations.
Accomplishments that we're proud of
We're proud of finishing such a holistic project in a short amount of time. Furthermore, our team mainly consisted of business majors with little technical experience so it was a great eye opener to the world of software. Finally, we're proud of being able to fight through many roadblocks, hurdles, and weird bugs without getting discouraged and managing to submit a project.
What we learned
We learned a ton about web scraping, database technologies, and visualization methods. We also improved our teamwork, collaboration, and commmunication skills.
What's next for KLARITY
We plan on building out more of the visualizations and eventually hosting the website online so everyone can use it. Furthermore, if we schedule nightly scraping jobs, we can build up a large collection of used goods data. The North Star would be to create a free chrome extension so everyone can compare used good prices for free!











Log in or sign up for Devpost to join the conversation.