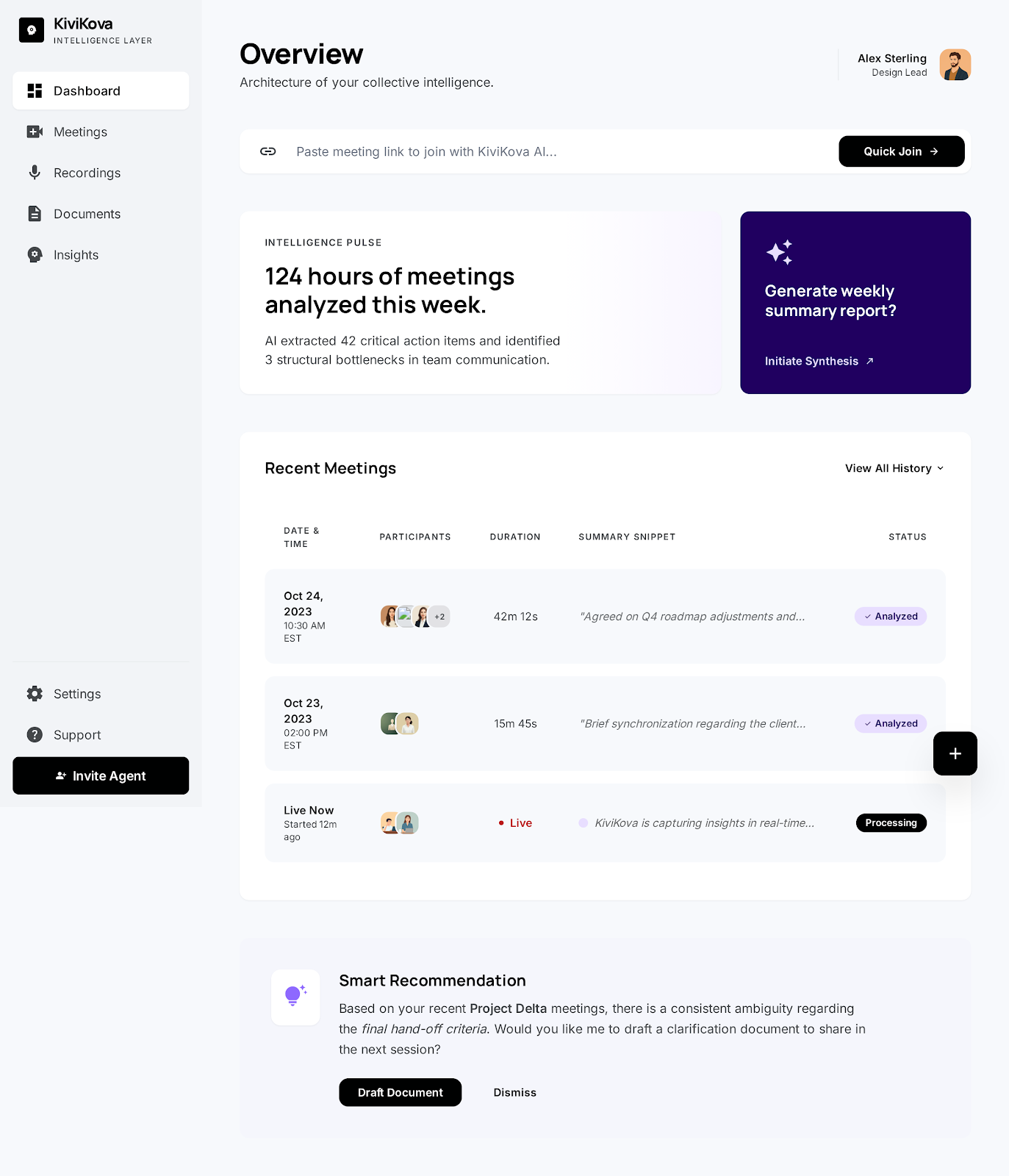
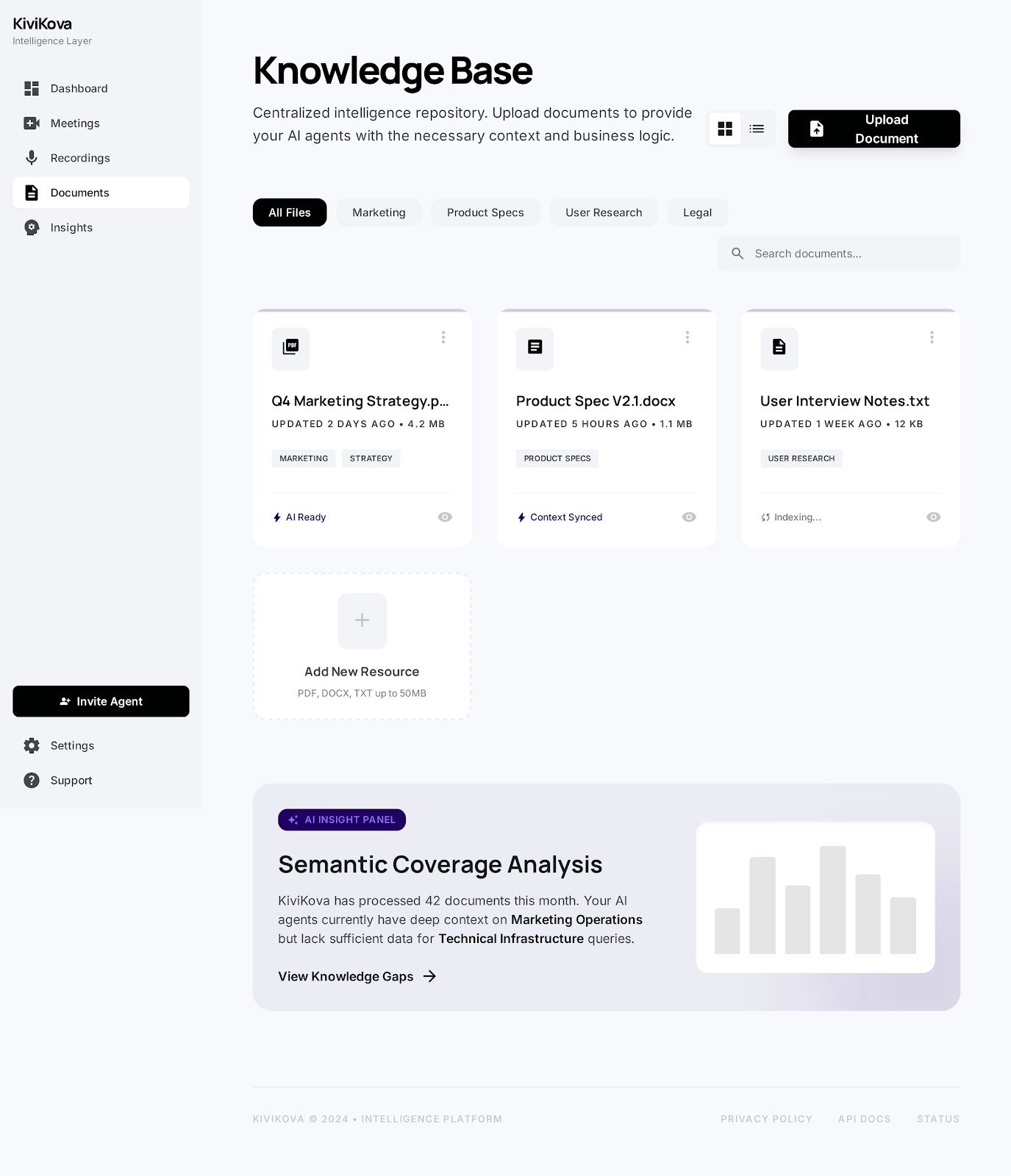
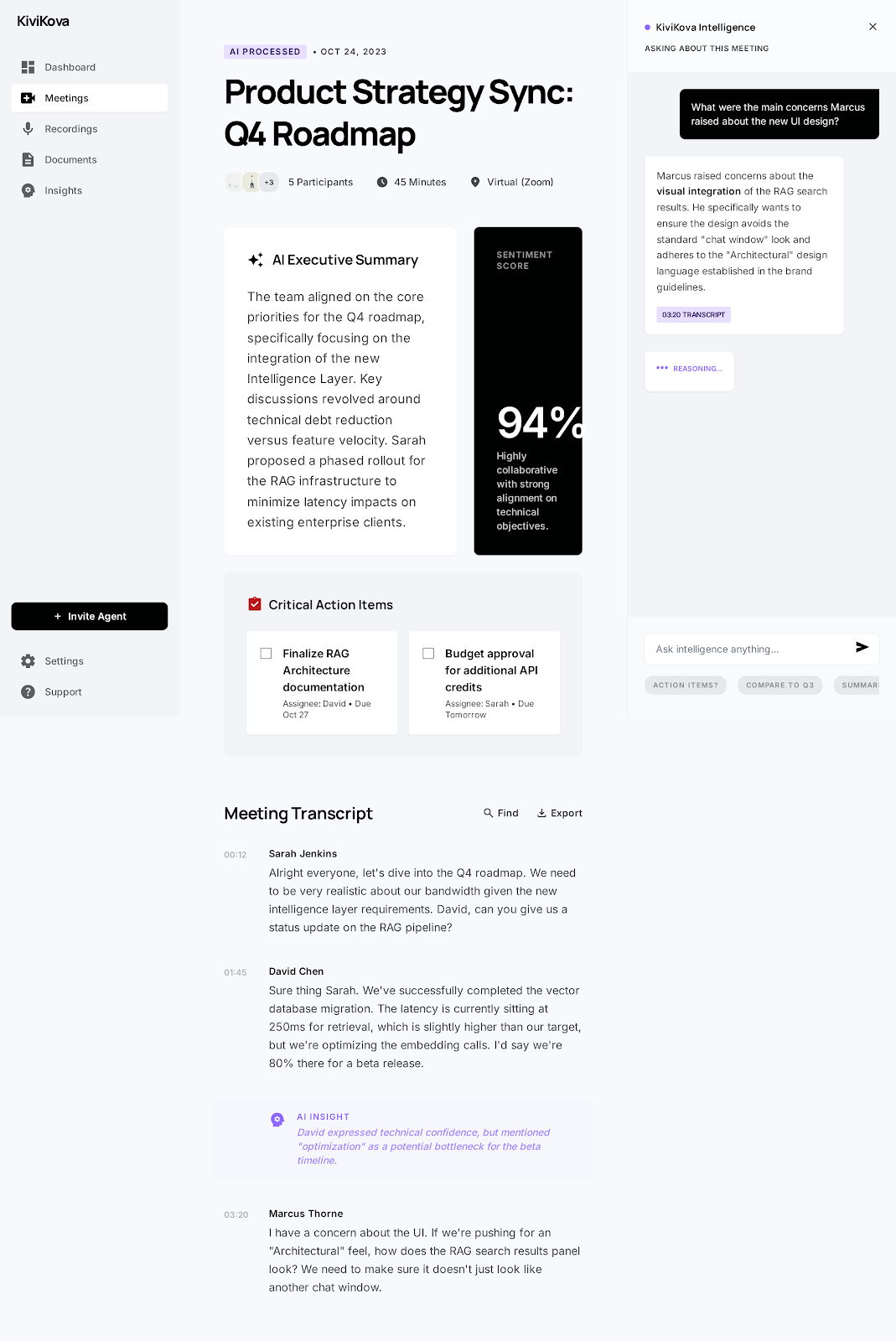
Inspiration
We wanted to bring AI agents to meetings in an interactive way. Meetings are where decisions happen, but the knowledge generated in them is trapped — in people's heads, in forgotten recordings, in notes nobody reads. We asked: what if an AI agent could sit in the meeting, build a memory of everything said, and answer questions on the spot?
What it does
KiviKova is an autonomous AI agent that joins Google Meet calls and participates intelligently. It runs a real-time pipeline of specialized components:
- Joins the meeting — Paste a link and the bot enters the call within seconds via Recall.ai
- Transcribes live speech — Every utterance is captured with speaker attribution in real time
- Builds semantic memory — Each transcript chunk is embedded into a per-meeting vector store (Qdrant) with cosine similarity search
- Reasons about context — Uses GPT-4o with function calling to search the meeting's history (and all past meetings) before responding
- Speaks back into the meeting — Generates voice responses via OpenAI Realtime API, injecting audio directly into the call
The result: an agent that actually participates in your meetings, not just records them.
How we built it
- Next.js 16 App Router as the full-stack framework — API routes, server components, and the dashboard UI
- Recall.ai for bot deployment — handles joining Meet/Zoom/Teams and streaming real-time transcripts via webhooks
- OpenAI text-embedding-3-small (1536 dimensions) for converting transcript chunks into vectors
- Qdrant as the vector database — each meeting gets its own collection for isolated, fast search
- OpenAI Realtime API (WebSocket) for the voice agent — bidirectional audio with function calling for RAG tool use
- GPT-4o for text-based RAG responses via the
/api/agent/respondendpoint - PostgreSQL + Drizzle ORM for meeting metadata, status tracking, and the full meeting lifecycle
- Vitest for testing — 94 unit tests covering all API routes, the RAG pipeline, and the voice session
- GitHub Actions CI pipeline running tests, ESLint, and Prettier on every push
Challenges we ran into
- Real-time transcript processing — Recall.ai sends partial and final transcript chunks via webhooks. We had to handle non-final chunks (skip them), empty word arrays, and malformed JSON from external sources without crashing the pipeline.
- Cross-meeting search at scale — Searching across many Qdrant collections in parallel required concurrency limiting (batches of 5) and partial failure tolerance — if one collection is down, the rest should still return results.
- Voice agent connection lifecycle — The OpenAI Realtime API is async and WebSocket-based. We had to handle race conditions: what if
close()is called while a RAG search is in flight? What ifconnect()is called twice? We solved this with connection identity tracking and null guards. - Testing WebSocket-based code — Mocking the OpenAI Realtime API's event emitter pattern required building a custom mock with a
_trigger()helper to simulate server events in tests.
Accomplishments that we're proud of
- End-to-end pipeline working — From pasting a meeting link to getting voice answers grounded in meeting history, the entire chain works
- 94 tests, zero lint warnings — Every API route, the RAG pipeline, the webhook handler, and the voice session are thoroughly tested
- Cross-meeting RAG — The voice agent searches across all your meetings, not just the current one. Ask about something from last week's call and get an answer in the current meeting
- Graceful degradation everywhere — If OpenAI is down, the voice agent doesn't crash. If some Qdrant collections fail, you get partial results. If all fail, you get a clear error.
- Clean architecture — Provider pattern for meeting bots, typed error classes for the RAG pipeline, shared modules between the text and voice agents
What we learned
- The OpenAI Realtime API is powerful but requires careful lifecycle management — WebSocket connections, async event handlers, and function calling all introduce subtle concurrency bugs
- Per-meeting vector collections in Qdrant are a great isolation pattern — each meeting's context is independent, but cross-meeting search is still possible via fan-out
- Hackathon code quality matters — the bugs we caught in review (silent error swallowing, stale connection handlers, breaking API changes) would have been demo-killers
What's next for KiviKova
- Speaker diarization — Better speaker identification and tracking across meetings
- Auto meeting summaries — Generate executive digests when a meeting ends
- Action item extraction — Pull tasks, assignees, and deadlines from the conversation automatically
- Slack and Notion export — Push summaries and action items where your team already works
- Multi-tenant organizations — Workspaces with SSO, RBAC, and shared meeting intelligence
- Proactive knowledge surfacing — The agent suggests relevant context before you ask
Built With
- drizzle
- openai
- postgresql
- qdrant
- recall.ai
- typescript

Log in or sign up for Devpost to join the conversation.