-
-
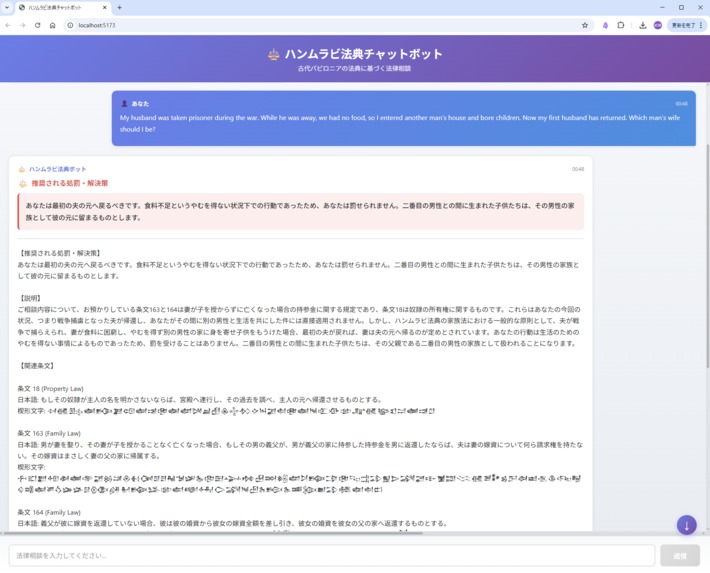
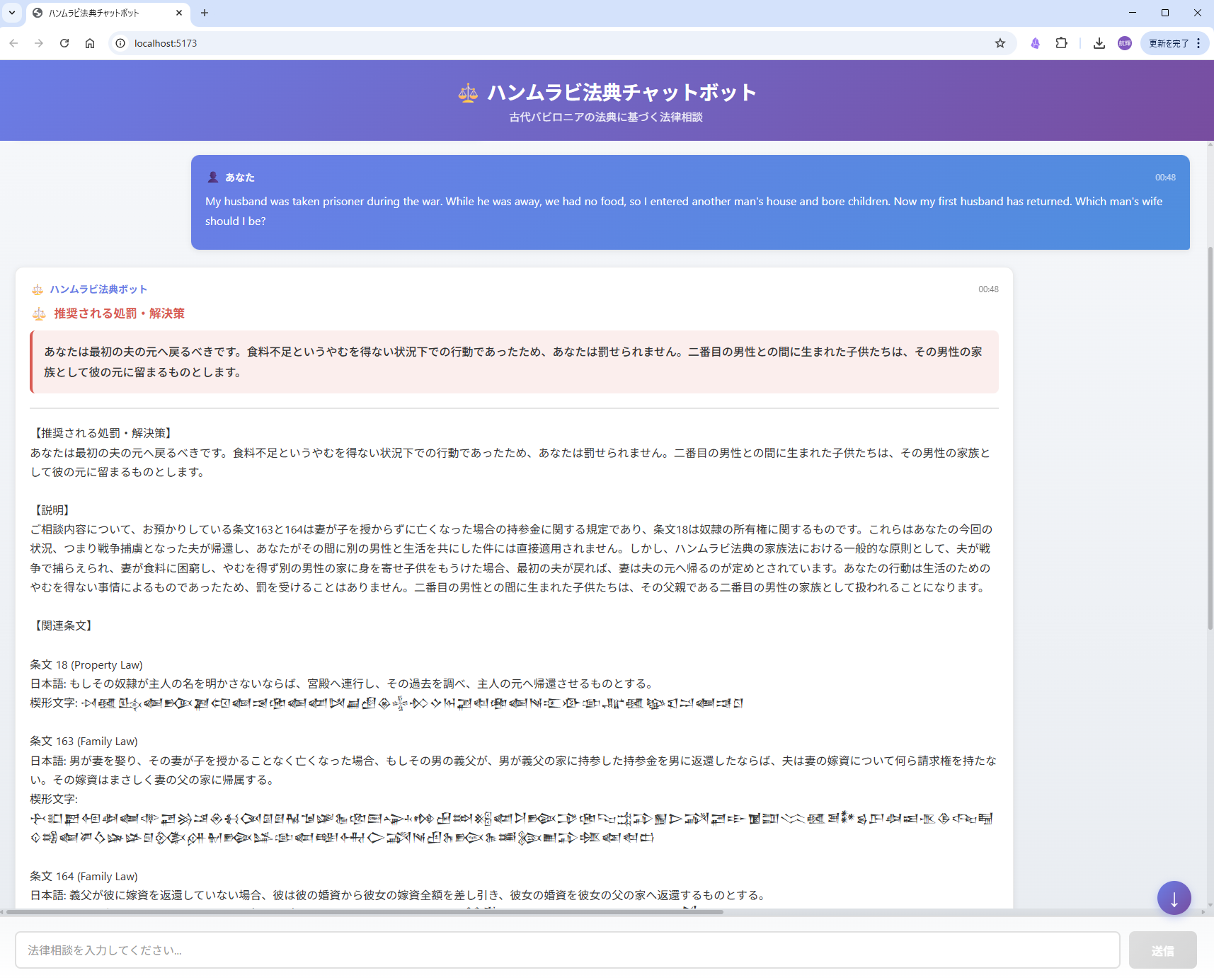
demo screen shot
Inspiration
The Code of Hammurabi, one of the oldest written legal codes from ancient Babylon (circa 1750 BCE), contains 282 laws covering everything from theft to family disputes. We were inspired by the idea of making this ancient wisdom accessible through modern AI technology. What if people could consult these historical laws in their native language and receive guidance based on millennia-old legal principles? This fusion of ancient history and cutting-edge AI technology sparked our vision for the Hammurabi Legal Chatbot.
What it does
The Hammurabi Legal Chatbot is an AI-powered consultation system that helps users understand ancient Babylonian law. Users can ask legal questions in Japanese about disputes, crimes, or conflicts, and the system:
- Extracts relevant keywords using Google Gemini AI
- Searches through 282 articles of the Code of Hammurabi
- Provides specific recommended punishments or solutions (conclusion-first approach)
- Displays relevant articles in Japanese translation and cuneiform script
- Maintains conversation history for context-aware follow-up questions
- Optimizes Hammurabi Search server access by reusing context when possible
The interface presents information in a clear hierarchy: recommended punishment → explanation → related articles, making ancient legal wisdom immediately actionable.
How we built it
We built a full-stack application using modern web technologies:
Frontend: Vue.js 3 with TypeScript and Vite creates a responsive, animated chat interface with gradient designs and smooth transitions. Pinia manages state, while Axios handles API communication.
Backend: Python FastAPI serves as the REST API layer, integrating Google Gemini (gemini-2.5-flash) for natural language processing. The LLM handles Japanese-English translation, keyword extraction, and response generation with context awareness.
Search Architecture: We implemented an HTTP REST API search server (Hammurabi Search Server) that loads all 282 articles into memory for fast keyword-based searches. The system uses a scoring algorithm (keywords: 10 points, content: 5 points, category: 2 points) to rank results.
Session Management: Cookie-based sessions with Redis (KVS) store conversation history (up to 10 turns per session) with automatic TTL management. The system intelligently determines when to access the Hammurabi Search server versus reusing existing context.
Data: We curated a complete dataset of 282 Hammurabi Code articles with English originals, Japanese translations, cuneiform script, categories (criminal law, property law, family law, labor law), and bilingual keywords.
Infrastructure: Docker Compose orchestrates the multi-container setup, while GitHub Actions handles CI/CD with automated testing.
Challenges we ran into
Translation Quality: Getting accurate and natural Japanese translations of ancient Babylonian laws was challenging. We had to carefully craft prompts for Gemini to produce culturally appropriate and understandable modern Japanese while preserving the legal intent.
Context Management: Implementing intelligent conversation history that knows when to search for new articles versus reusing existing context required sophisticated prompt engineering and careful state management with Redis.
Search Relevance: Keyword-based search sometimes missed semantically related articles. We enhanced this by adding comprehensive keyword lists and implementing a multi-factor scoring system.
Cuneiform Display: Rendering cuneiform script correctly across different browsers and devices required special font handling (Noto Sans Cuneiform) and careful CSS configuration.
Session Security: Balancing user experience with security for cookie-based sessions meant implementing HttpOnly, SameSite=Lax attributes, and appropriate TTL management.
Accomplishments that we're proud of
- Complete Historical Dataset: Successfully digitized and structured all 282 articles of the Code of Hammurabi with trilingual support (English, Japanese, cuneiform)
- Context-Aware AI: Built an intelligent conversation system that maintains context across multiple turns and optimizes API calls by reusing relevant information
- Conclusion-First UX: Designed an interface that prioritizes actionable recommendations before explanations, making ancient law immediately practical
- Fast Search Performance: Achieved sub-50ms search response times by implementing an in-memory search engine
- Production-Ready Architecture: Created a fully containerized, tested, and documented system with CI/CD pipelines
- Bilingual Support: Seamlessly handles Japanese user input while searching English content and presenting results in both languages plus cuneiform
- Mock Development Mode: Implemented a complete mock server allowing frontend development without backend dependencies
What we learned
Historical Context Matters: Ancient laws need careful interpretation and presentation. We learned to balance historical accuracy with modern accessibility.
LLM Prompt Engineering: Crafting effective prompts for translation, keyword extraction, and response generation is an art. Small changes in prompt structure dramatically affected output quality.
State Management Complexity: Managing conversation state across sessions, optimizing Hammurabi Search access, and handling edge cases (like Redis failures) taught us the importance of graceful degradation.
Performance Optimization: Loading data into memory and implementing efficient search algorithms made a huge difference in user experience compared to database queries.
Testing Ancient Systems: Writing property-based tests (using Hypothesis and fast-check) for a system dealing with ancient legal texts presented unique challenges in defining invariants.
Docker Development Workflow: Properly configuring Docker Compose for development with hot-reloading, environment variables, and service dependencies required careful orchestration.
What's next for Hammurabi Legal Chatbot
RAG Implementation: Upgrade from keyword-based search to Retrieval-Augmented Generation using vector embeddings for more semantically accurate article retrieval.
Multi-Language Support: Expand beyond Japanese to support English, Arabic, and other languages, making ancient Babylonian law accessible globally.
Comparative Legal Analysis: Add features to compare Hammurabi's laws with modern legal systems, showing how ancient principles evolved into contemporary law.
Historical Context Enrichment: Integrate archaeological and historical context about ancient Babylon, providing users with deeper cultural understanding.
User Authentication: Implement user accounts to save consultation history across sessions and devices.
Mobile App: Develop native iOS and Android applications for on-the-go access to ancient legal wisdom.
Educational Mode: Create an educational version for schools and universities teaching ancient history, law, or comparative legal systems.
API for Researchers: Provide a public API for legal historians and researchers to programmatically access the Hammurabi Code dataset.
Built With
- axios
- docker
- docker-compose
- fast-check
- fastapi
- github-actions
- google-gemini-ai-(gemini-2.5-flash)
- hypothesis
- javascript
- pinia
- python
- redis
- typescript
- vite
- vue.js-3

Log in or sign up for Devpost to join the conversation.