-
-
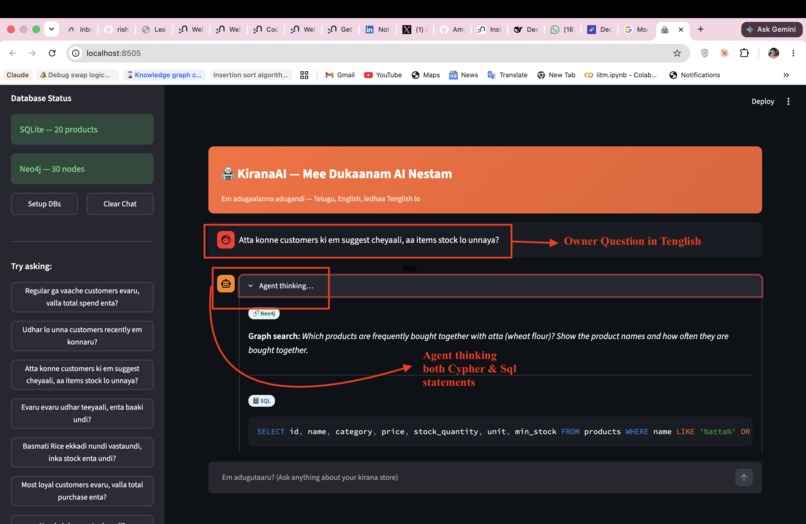
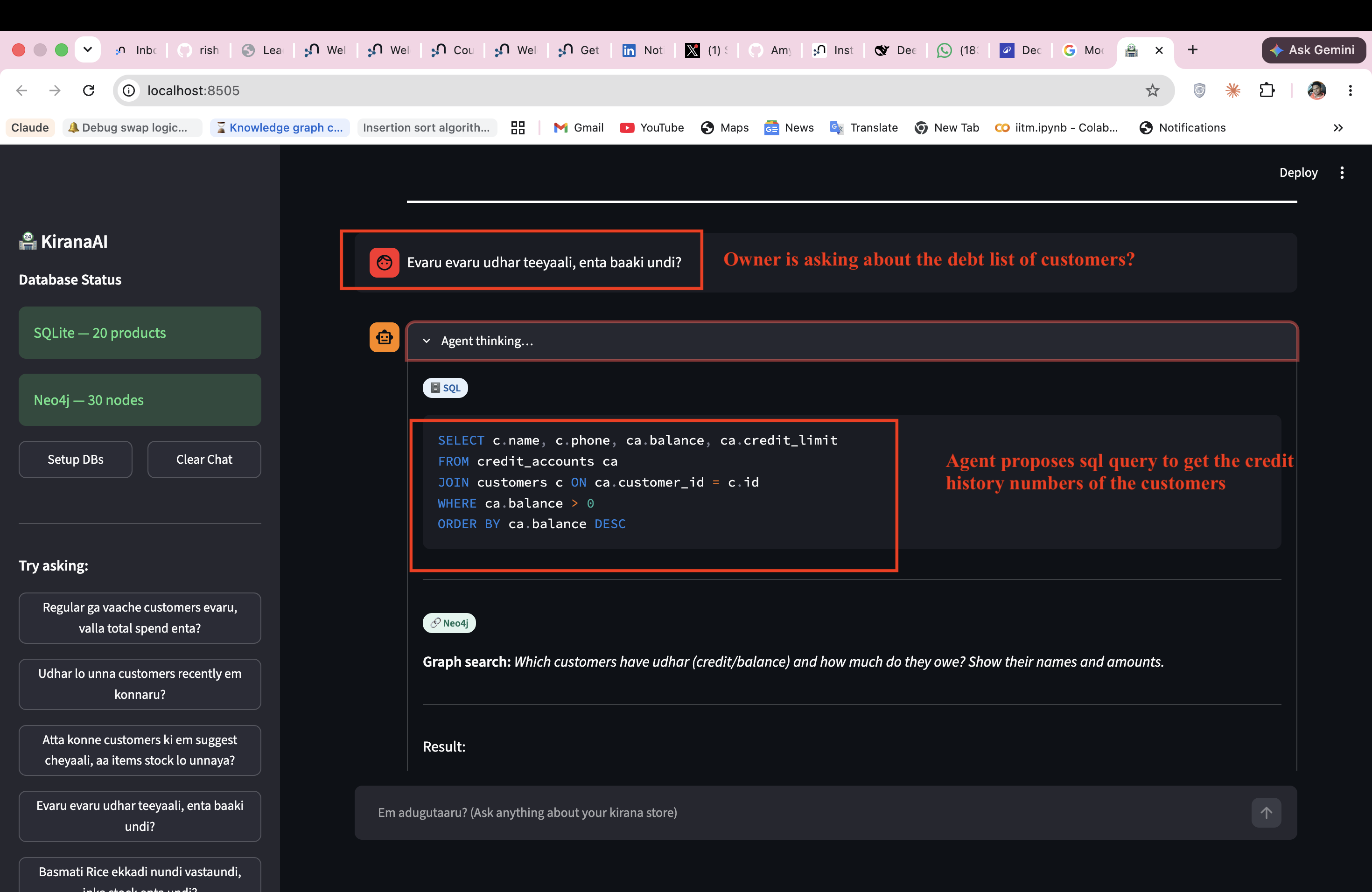
Q1 "Regular ga vaache customers evaru, valla total spend enta?"
-
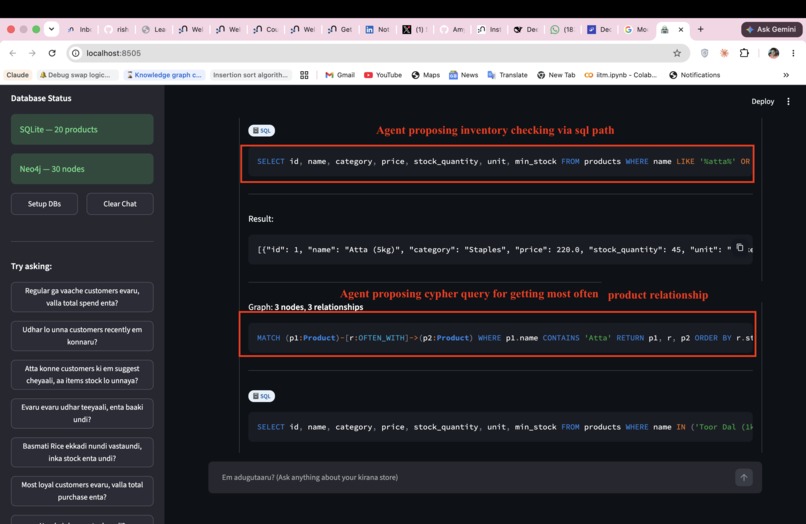
Q1 "Regular ga vaache customers evaru, valla total spend enta?",
-
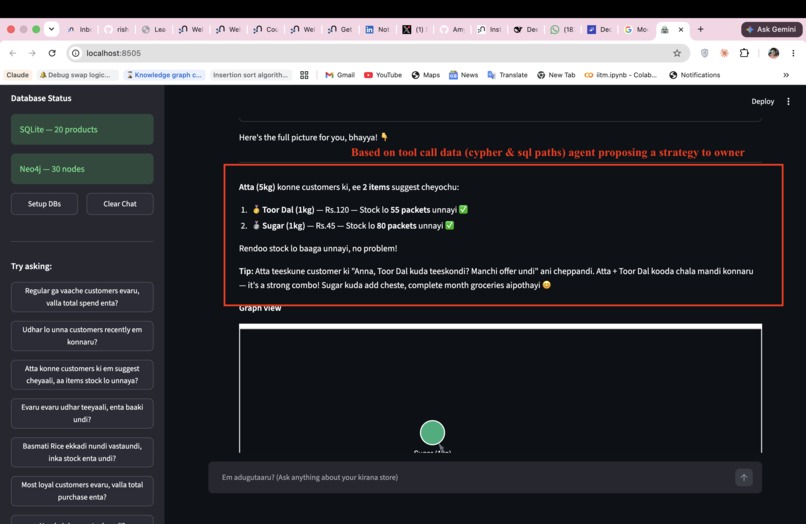
Q1 "Regular ga vaache customers evaru, valla total spend enta?"
-
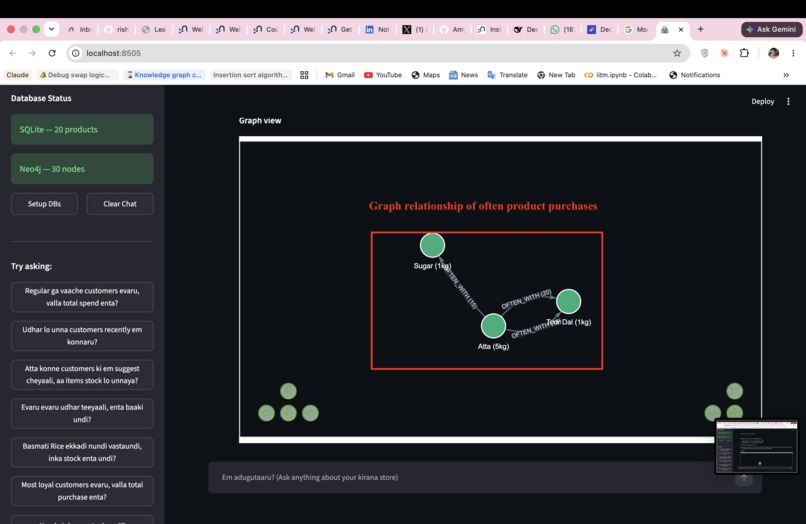
Q1 "Regular ga vaache customers evaru, valla total spend enta?"
-
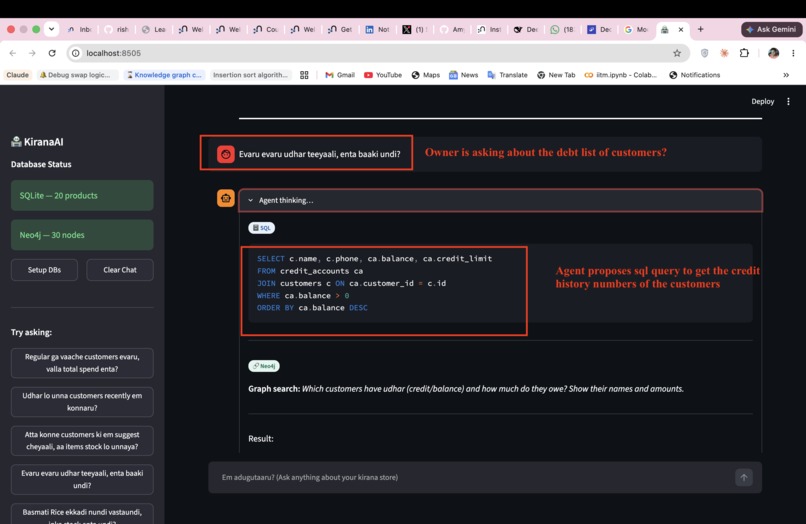
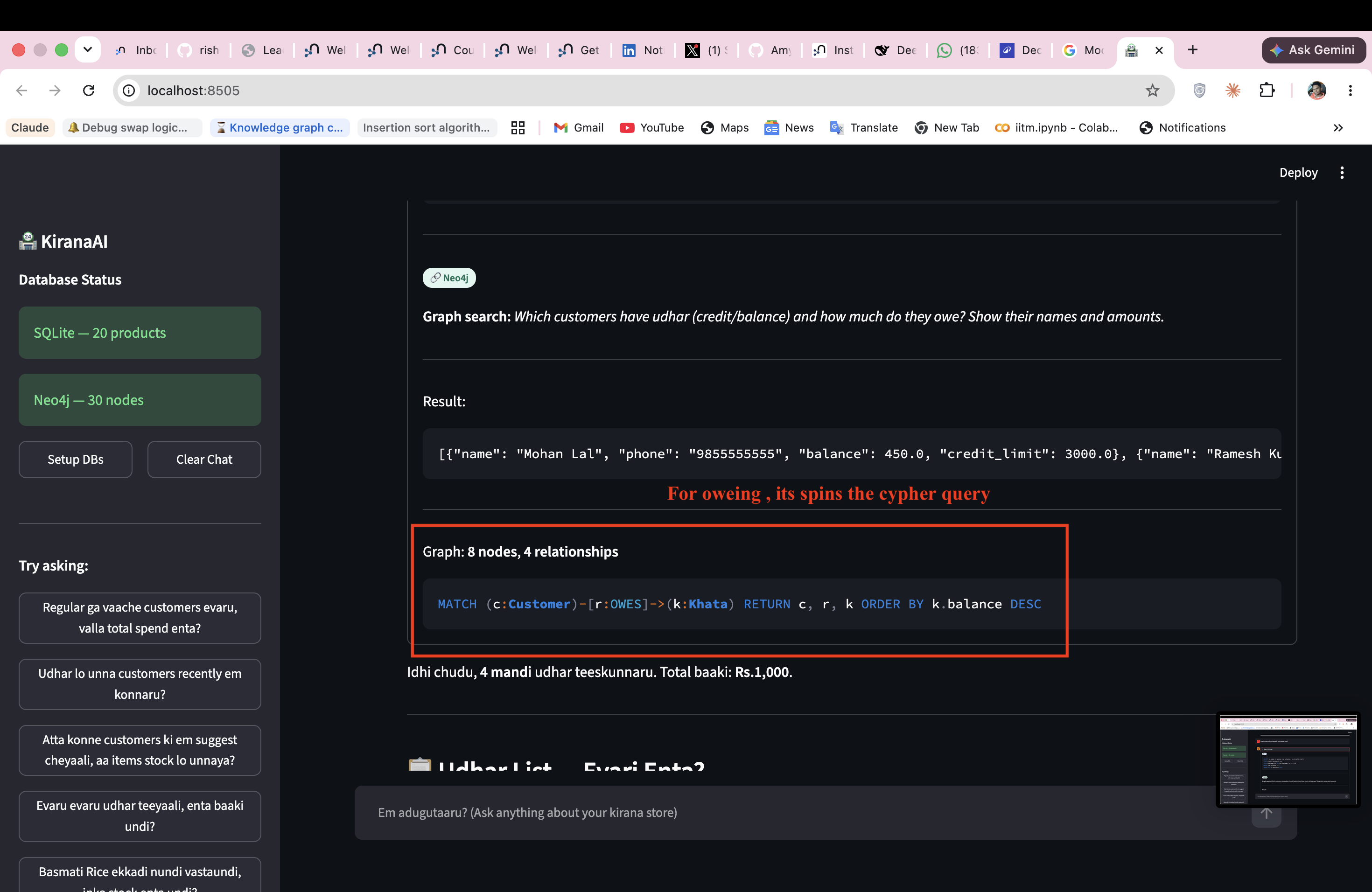
Q2 "Udhar lo unna customers recently em konnaru?"
-
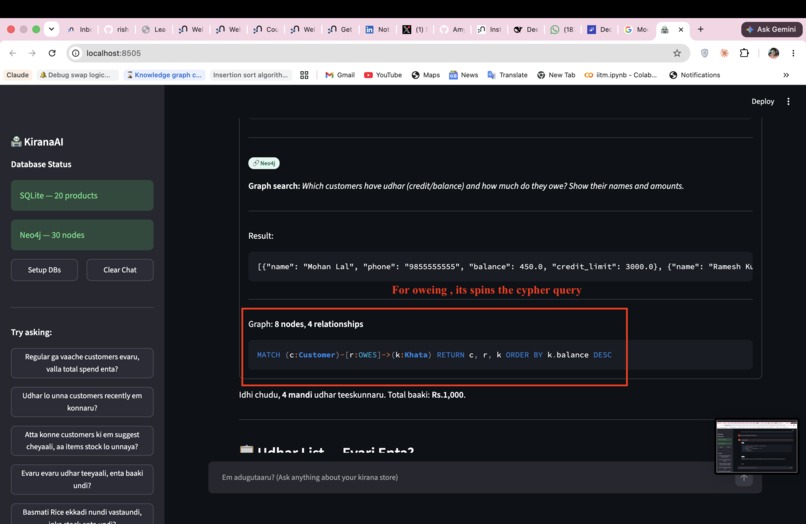
Q2 "Udhar lo unna customers recently em konnaru?"
-
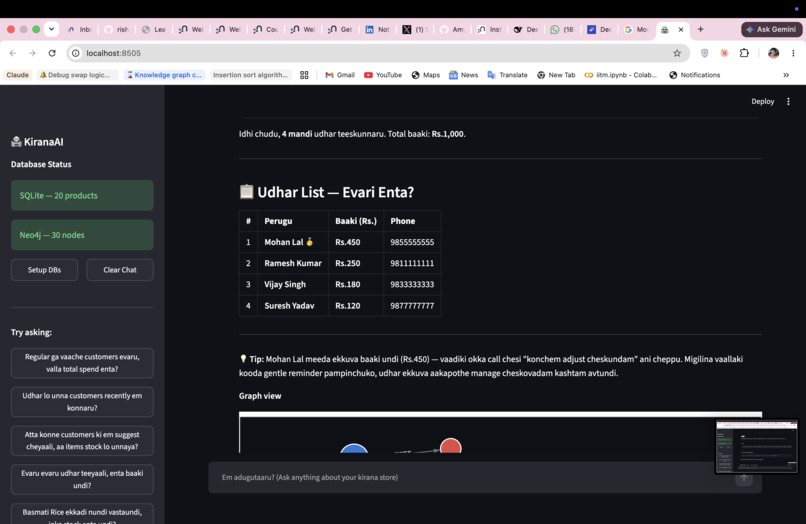
Q2 "Udhar lo unna customers recently em konnaru?"
-
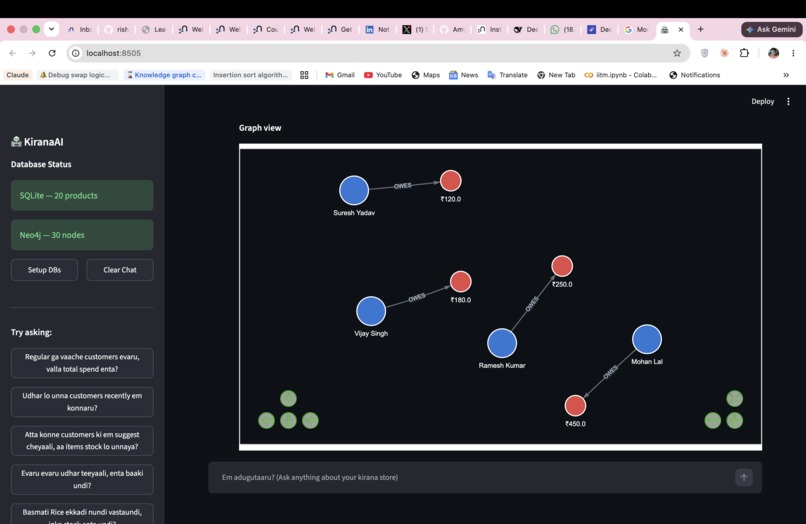
Q2 "Udhar lo unna customers recently em konnaru?"
Inspiration
India's 12 million kirana stores run on intuition. Every owner knows their customers, their credit, their patterns — but that knowledge lives only in their head. The moment they try to access it through technology, they hit a wall: they need a "technical person." And that person only gives them tables and totals — counts of things, not connections between things.
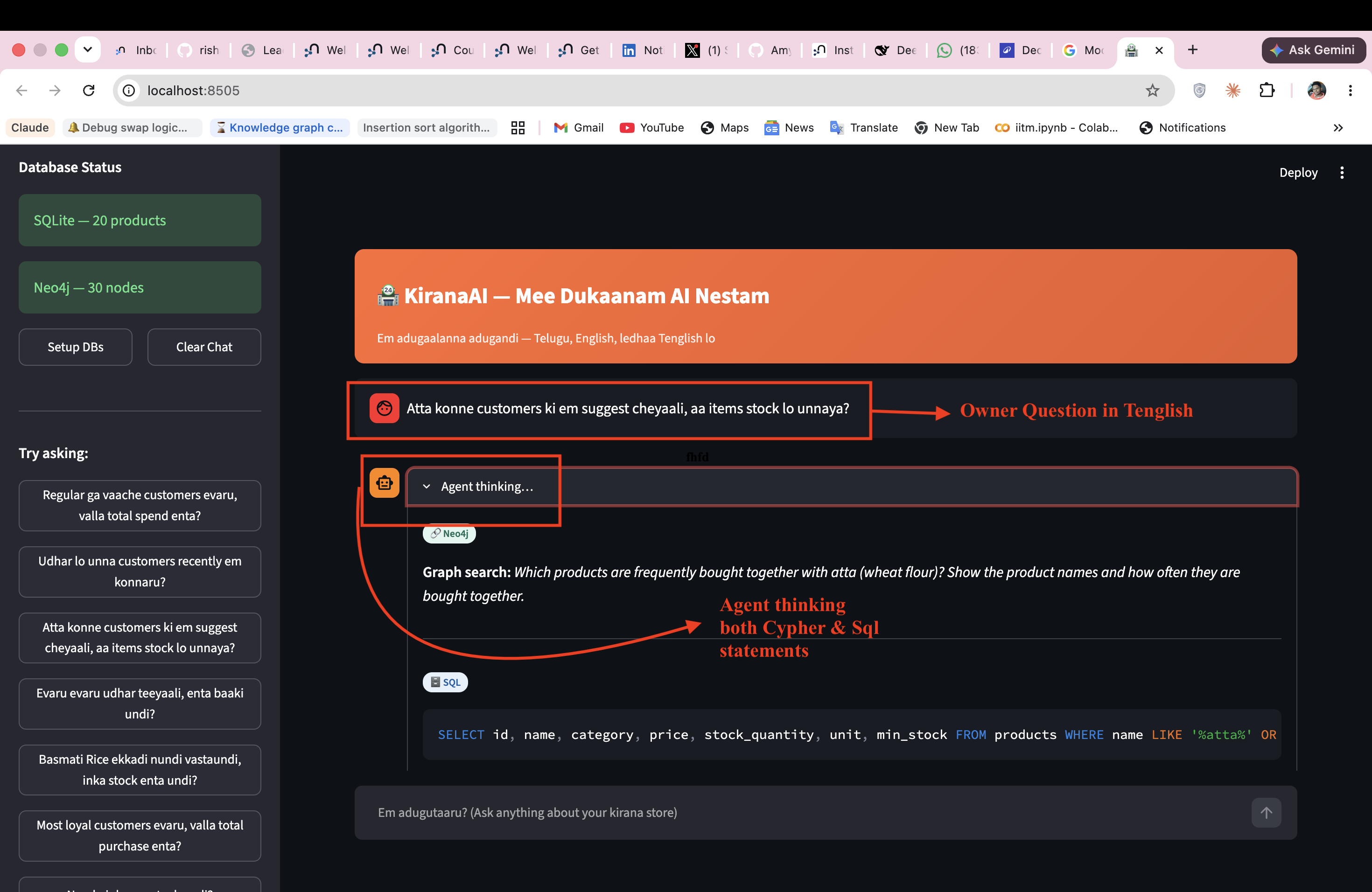
Growing up around kirana stores in Telugu-speaking neighbourhoods, I noticed something: these owners never speak in pure Telugu or pure English. They speak in a natural mix — "Naadu stock takkuvaiga undi, enta baaki undi Ramesh ki?" That is Tenglish. Telugu words, English words, Roman script, no grammar rules — just how the thought comes out. Every AI tool built for them ignores this completely, forcing them into a language that is not theirs.
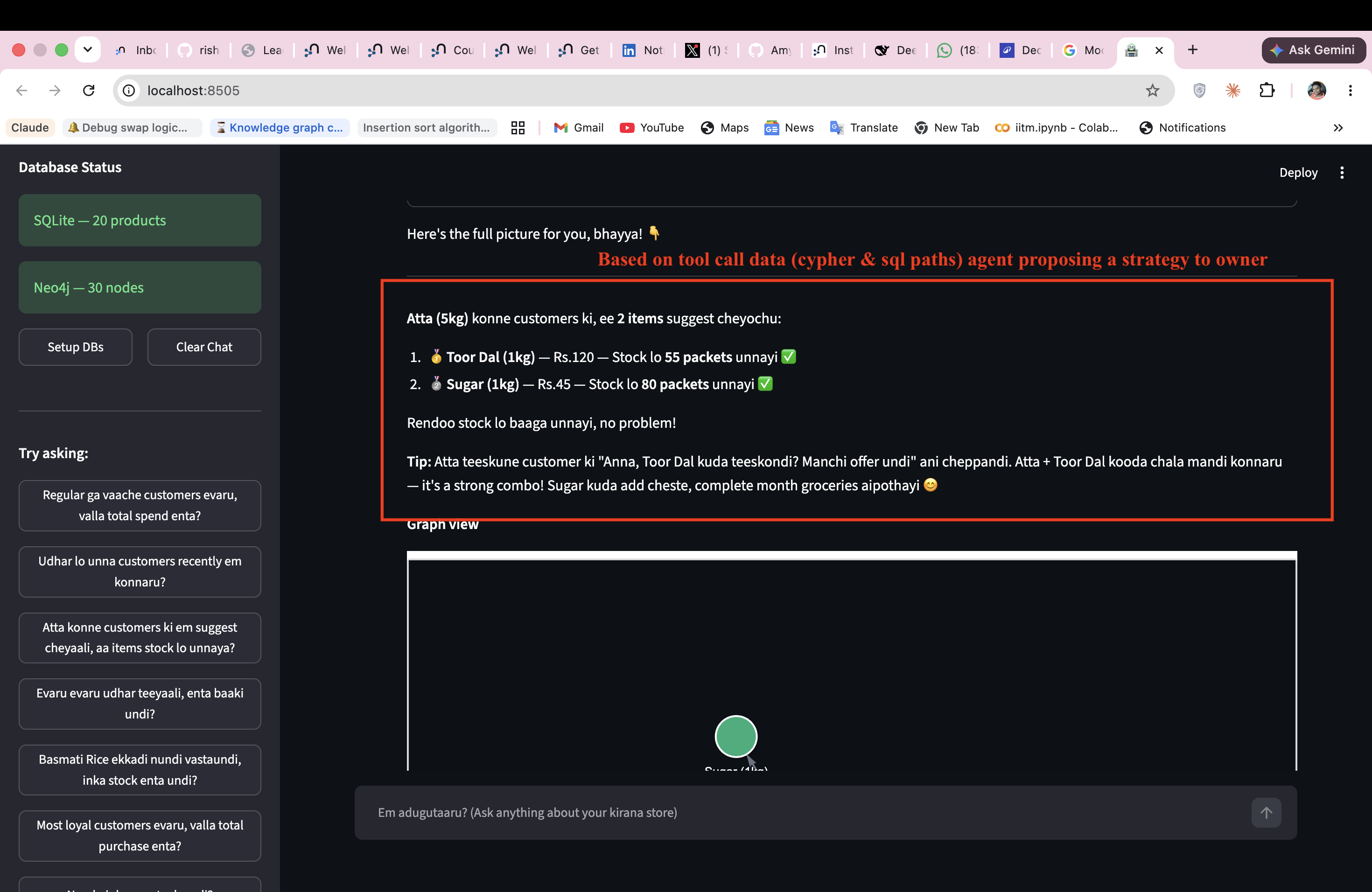
The insight that drove this project: structured databases tell you what exists. Graph databases tell you how things are connected. And for a kirana store, the connections are the business — who owes whom, what gets bought together, which supplier feeds which product, who referred which customer. That intelligence has never been accessible to an owner without a data team.
The Moonshot question: what if you could remove the technical intermediary entirely? Not simplify the interface — eliminate the role. An owner asks in Tenglish, the system reasons about which database holds the answer, and responds in the same language. No SQL. No Cypher. No dashboard. Just a conversation.
That is the zero-to-one shift: from data as something you hire someone to interpret to data as something you simply talk to.
What it does
KiranaAI is a conversational AI agent that accepts questions in Tenglish (Telugu + English, Roman script — how millions of Telugu shopkeepers actually speak and text). It routes each question to the right database automatically:
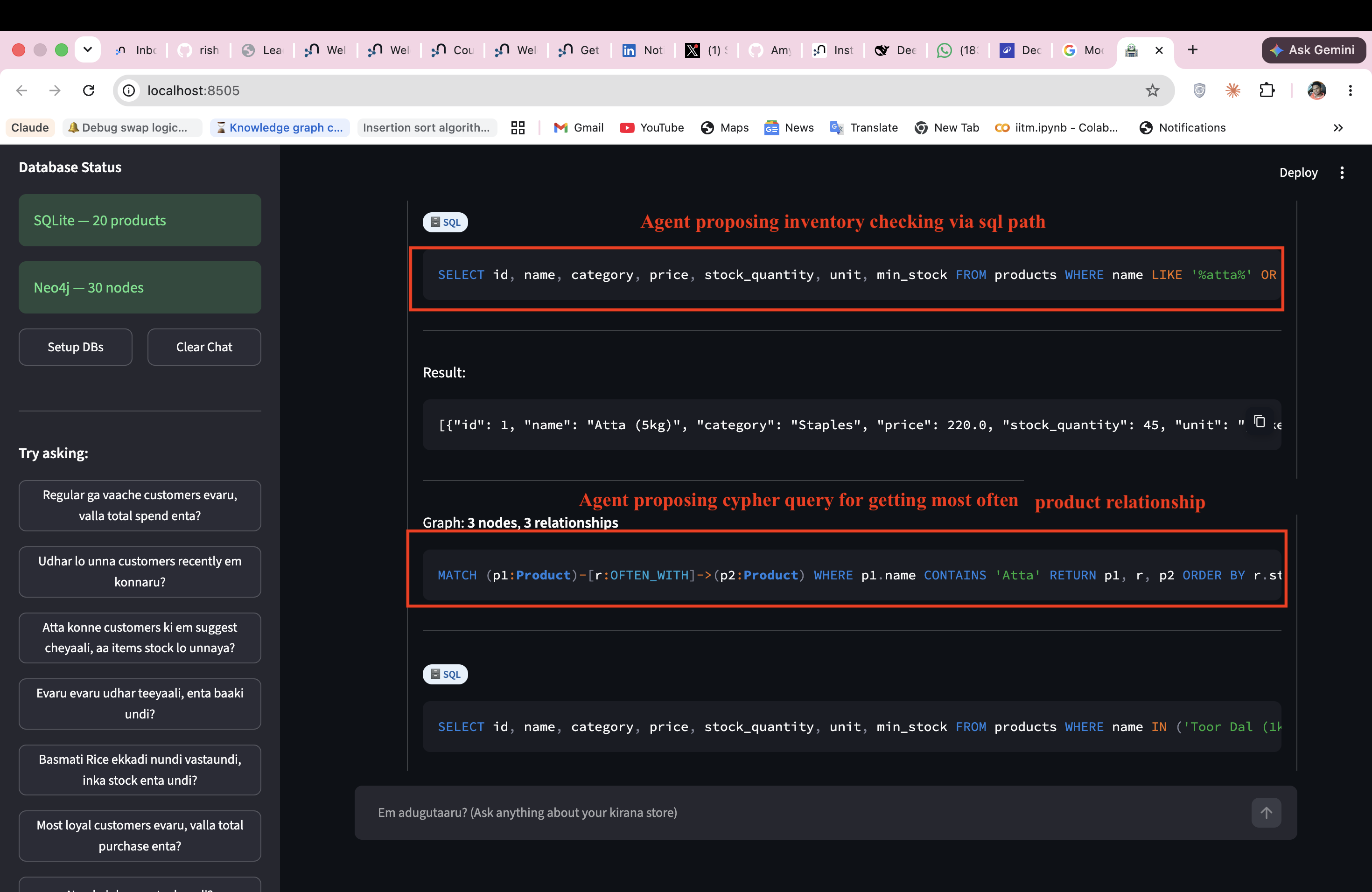
- Neo4j (Text2Cypher) — relationship questions: credit networks, co-purchase patterns, supplier chains, referral graphs
- SQLite (Text2SQL) — structured questions: stock levels, sales totals, billing, payment modes
- Both together — questions that need graph intelligence + real inventory data simultaneously
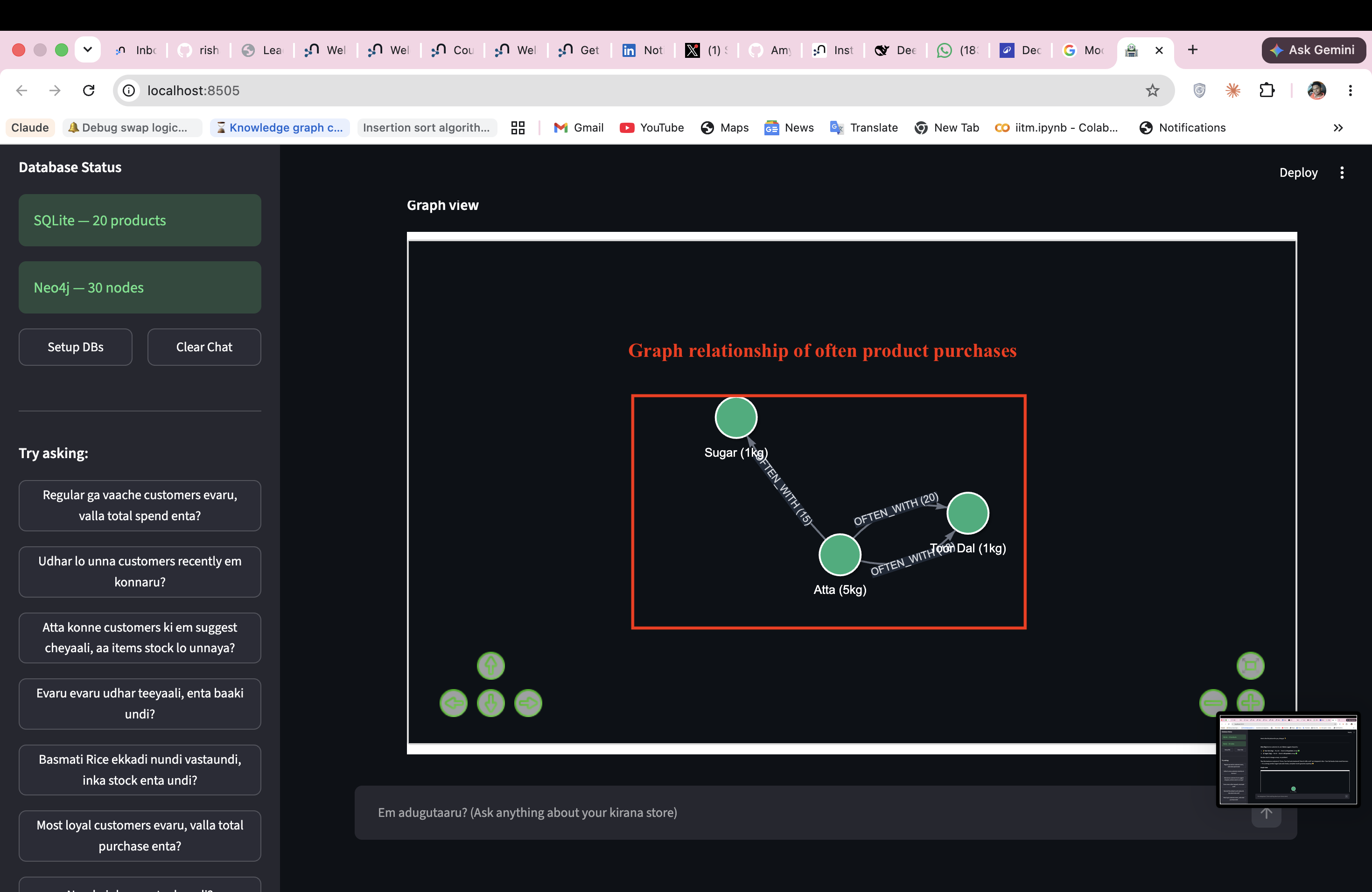
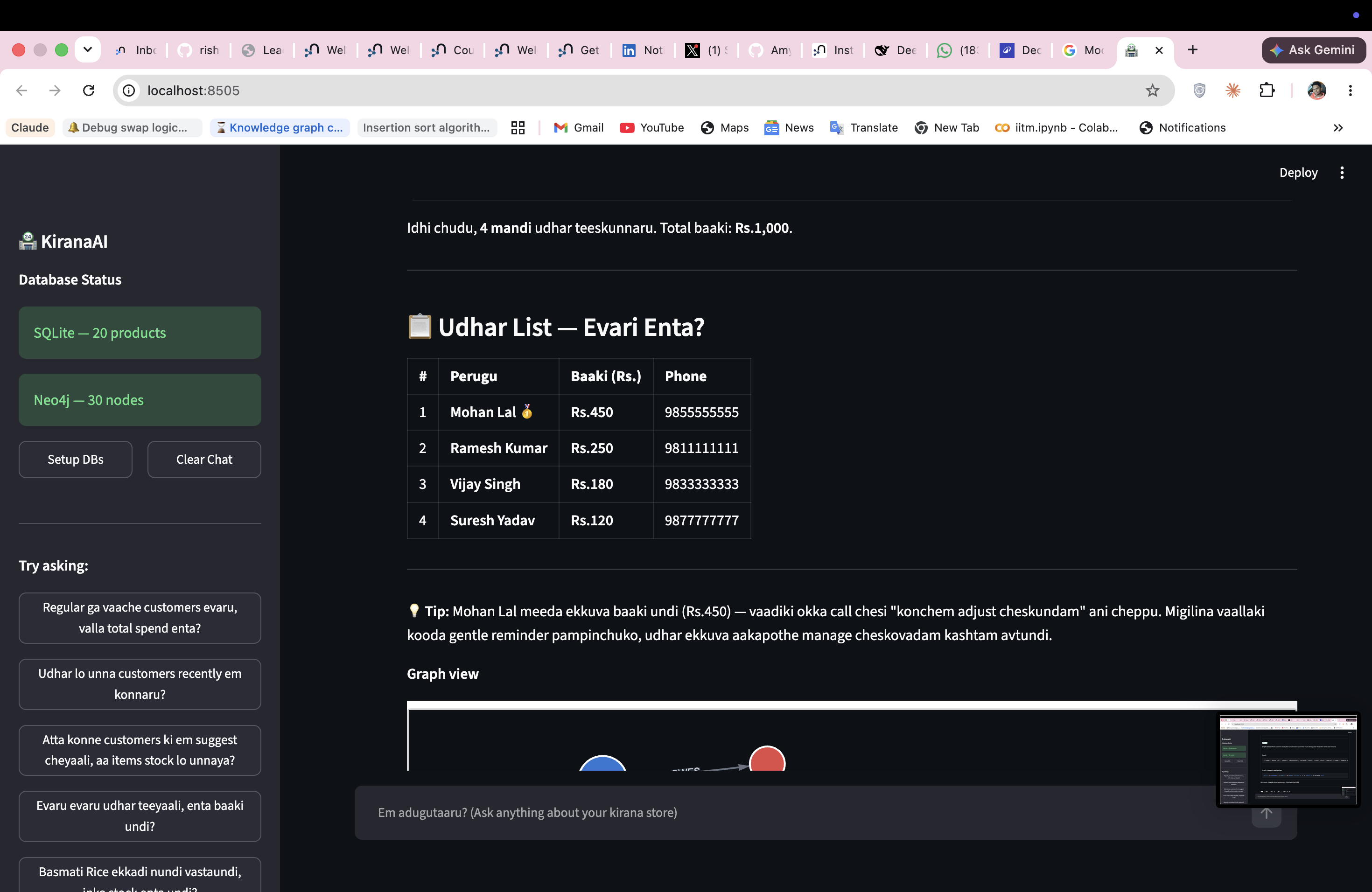
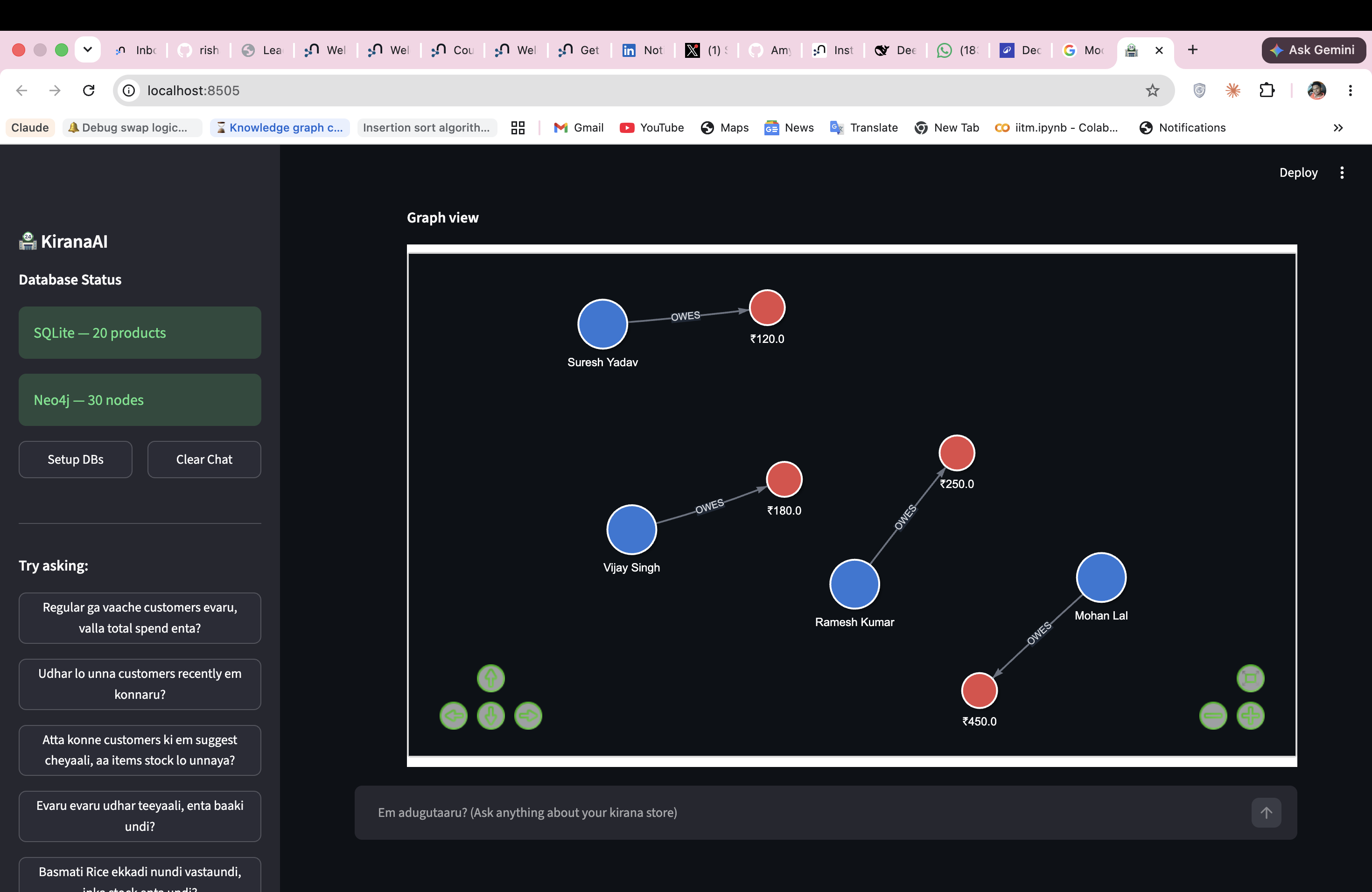
The agent renders interactive force-directed graphs from Neo4j results automatically — no configuration needed.
Zero-to-One Insight
Text2SQL and Text2Cypher are both products of the ReAct agent era (Yao et al. 2022). Before LLM-powered agents, NL-to-database was academic. The shift: an LLM can now reason about which database to query, act on it, observe the result, and synthesise an answer in the user's own language.
The first-principles insight: structured data gives analytics. Graph data gives intelligence. A kirana store's richest information lives in its relationships — not its tables. No existing solution combines both in natural language for a regional language speaker.
Graph schema:
(Customer)-[:PURCHASED {times}]->(Product)
(Customer)-[:OWES]->(Khata {balance})
(Product)-[:OFTEN_WITH {strength}]->(Product)
(Product)-[:SUPPLIED_BY]->(Supplier)
(Customer)-[:REFERRED_BY]->(Customer)
How we built it
- LangGraph
create_react_agent— orchestrates the ReAct reasoning loop - GraphCypherQAChain from
langchain-neo4j— Text2Cypher engine with 14 verified few-shot examples to prevent LLM hallucination - Neo4j Aura — cloud graph database
- DeepSeek LLM — reasoning backbone
- SQLite — structured/transactional store data
- Streamlit — streaming chat UI with live agent-thinking visibility
- pyvis — interactive graph rendering
The prototype is fully working — running on Neo4j Aura with seeded kirana store data. Source code at GitHub.
Long-Term Vision
If this model succeeds at scale: 12 million stores gain access to relationship intelligence that currently only large enterprises with data teams can access. The same architecture works for any informal economy — farmers querying crop relationships, small manufacturers querying supply chains — in any regional language. The technical intermediary disappears.
Challenges
Getting Text2Cypher to generate reliable Cypher without hallucinating complex aggregations required 14 verified few-shot examples anchored to the real schema. Capturing Node and Relationship objects for graph visualization required a second raw-driver execution after the chain ran. Balancing two databases in one agent required clear boundaries: Neo4j for relationships, SQL for aggregations.

Log in or sign up for Devpost to join the conversation.