-
-

-

Thanks to
-
Vibe with the Flow & Rhythmic Algorithm
-
Behind the Scenes
-
Music
-

Female and Male Character
-

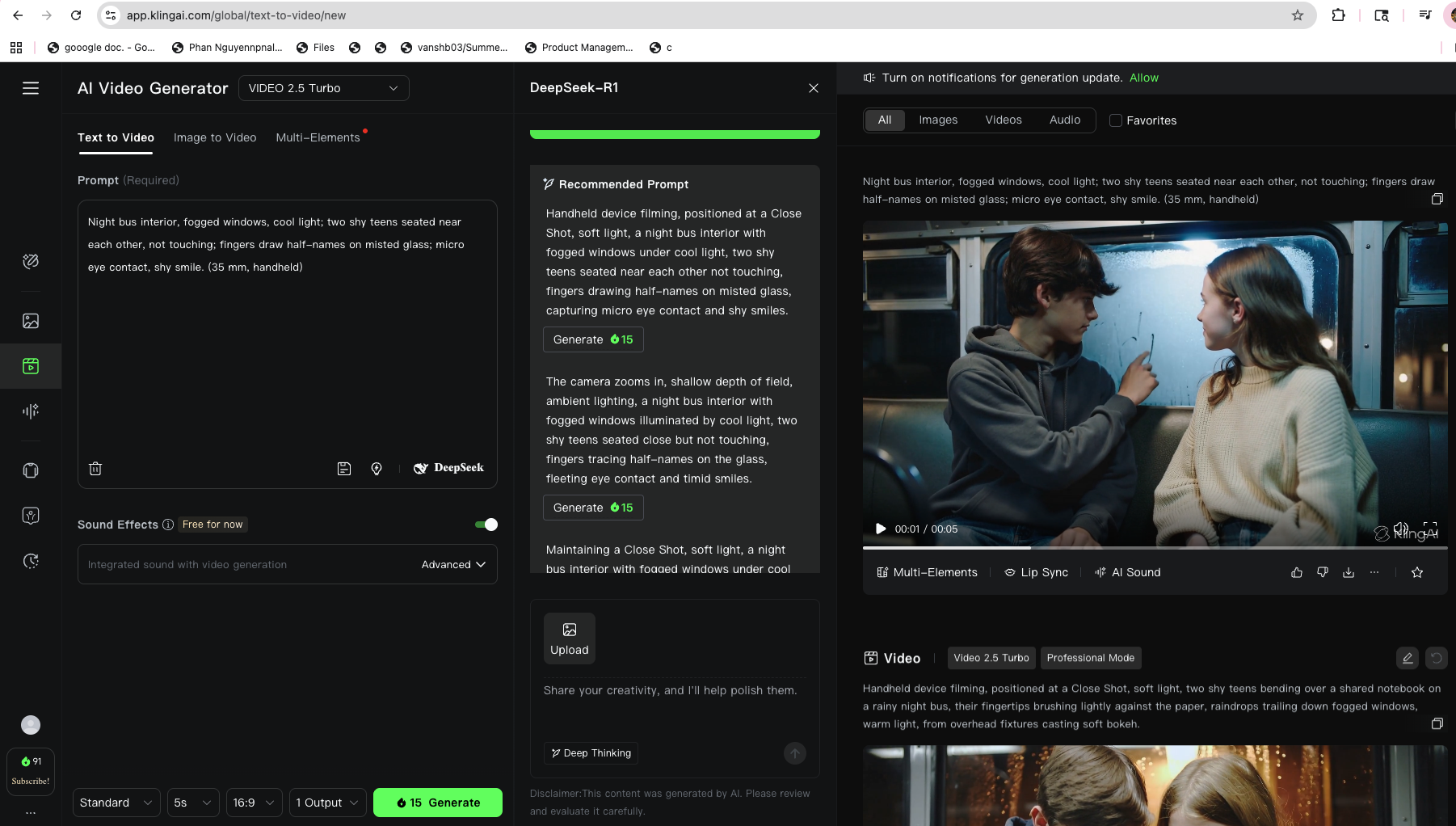
Text to Image to Video
-
Styles Experiment
-

Images and Videos
-
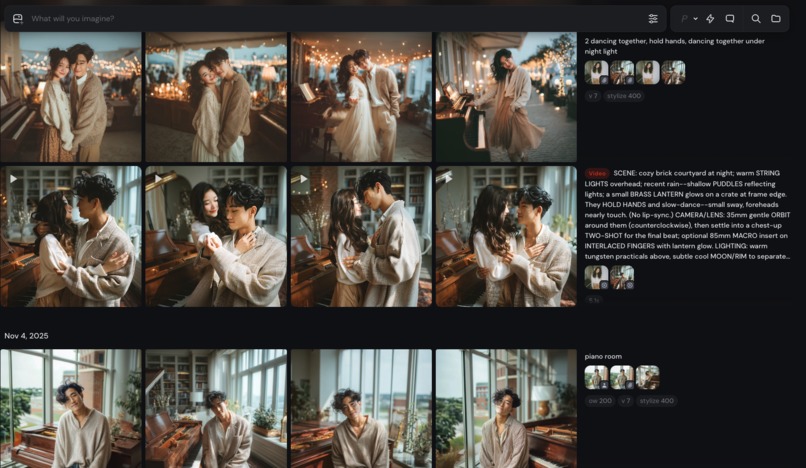
Images and Videos
-
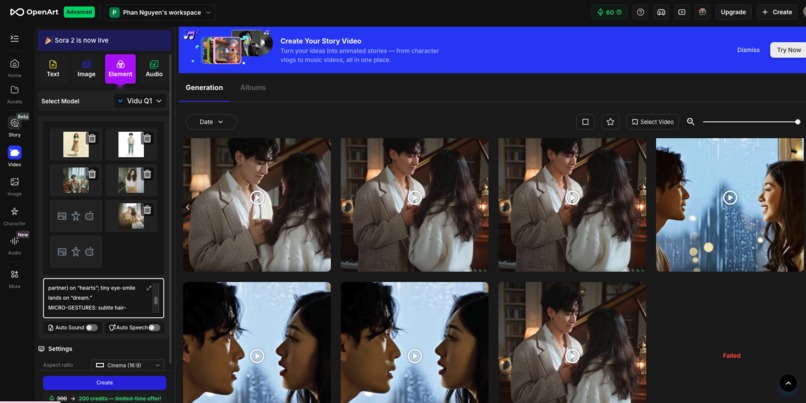
Elements to Videos
-
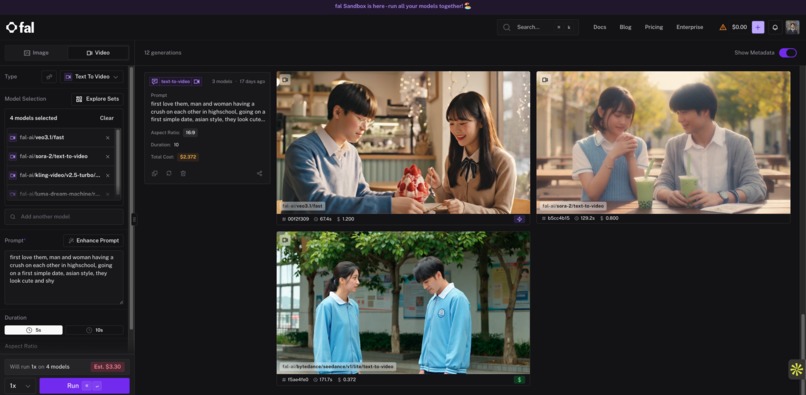
Texts to Videos
-
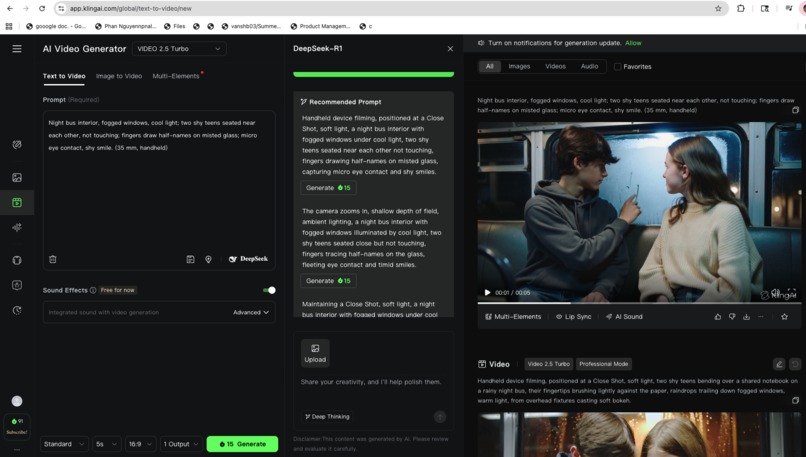
-

-
Figma


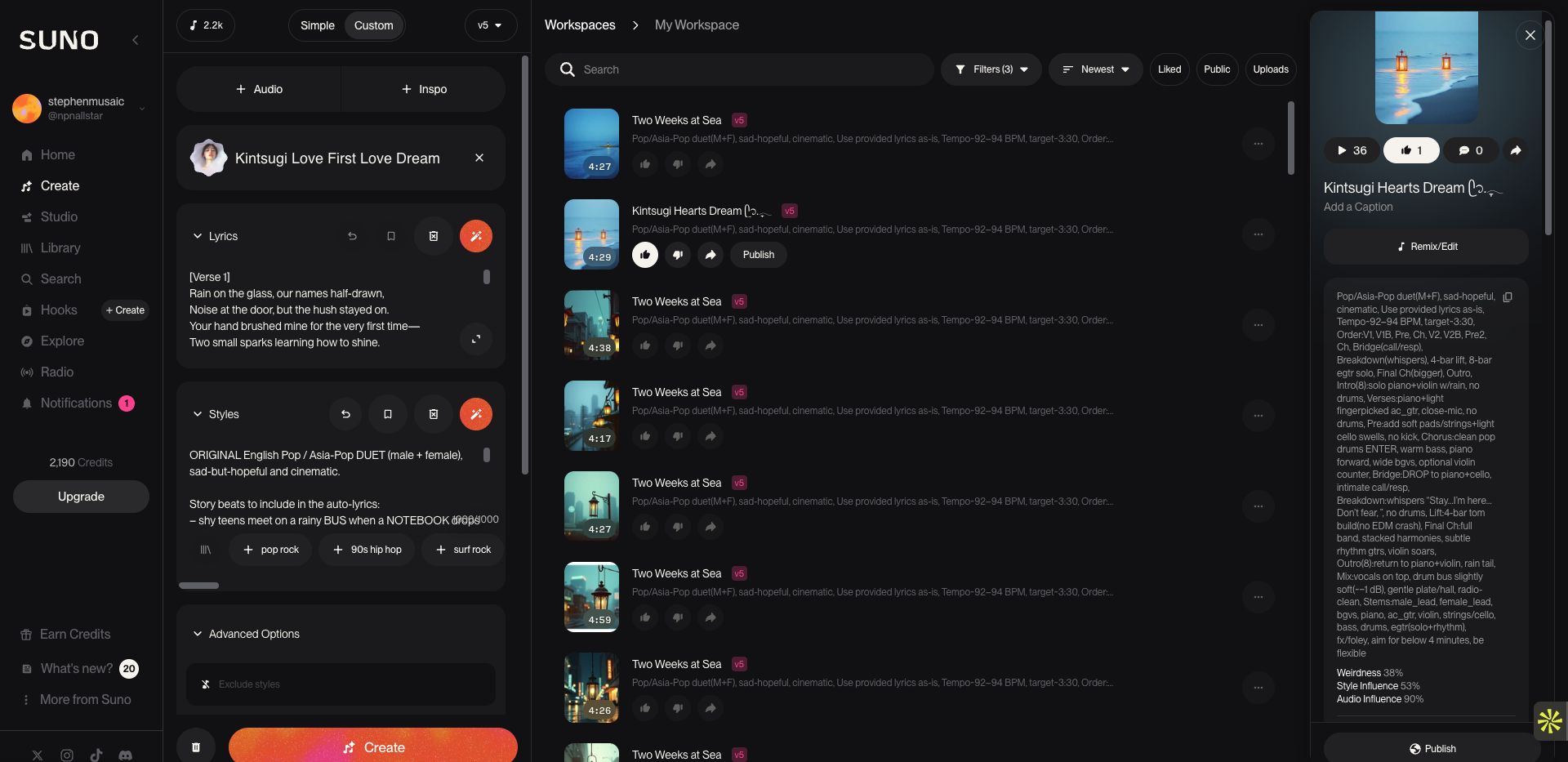




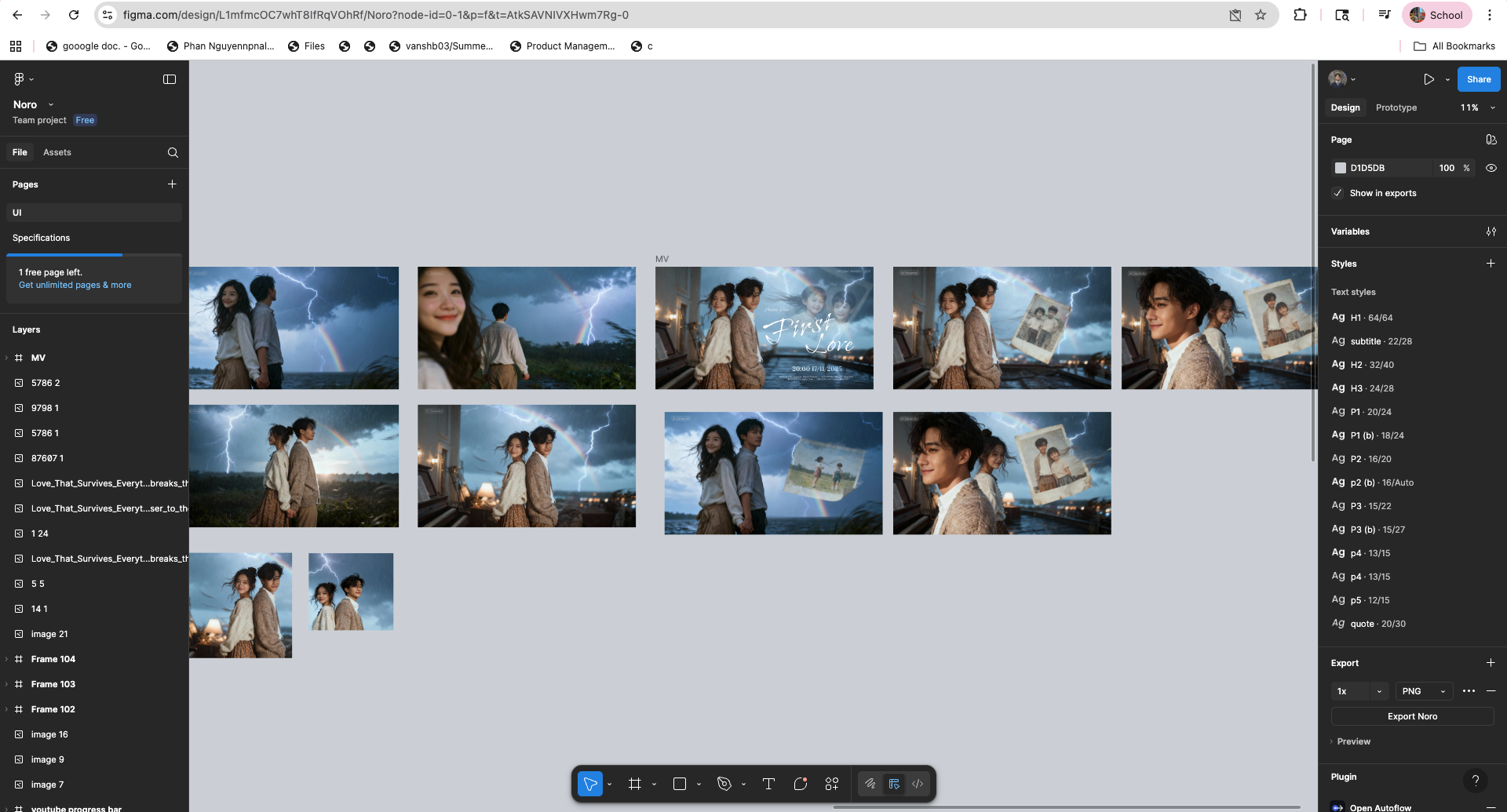
Kintsugi Hearts Dream
Thank you everyone for watching!
Story
A real first-love story in rain, violin, and lantern light.
In the MV, two shy teens who meet on a rainy bus learn to gold the seams of their lives—through small fights, hospital nights, and quiet promises—until they keep choosing each other at dawn.
Kintsugi metaphor: from Japan’s art of mending pottery with gold — a broken heart can be healed and return stronger, more beautiful, and more resilient.
Audience & Message
- Audience: people who are having first love; have had first love; have never had first love — basically, everyone.
- Core message: Love lasts when we keep choosing each other—even first love. If love can last, let first love try.
Research Questions
- Can AI convey emotions through memory?
- How good is AI's ability to create a MV?
- How does Love/First Love feel like?
- How much money we save for creative work?
BLACKPINK’s music videos are widely reported online to have multi-million-dollar production budgets.
Kill This Love — often reported around $1.4M (fan/media estimates). See YG’s “most expensive MV yet” coverage: NME, Korea JoongAng Daily.
DDU-DU DDU-DU — often reported around $1.3M (fan/media estimates). Example of circulating claim: Instagram roundup.
At a Glance
- A Pop/Asia-Pop duet with a 4:41 cinematic music video.
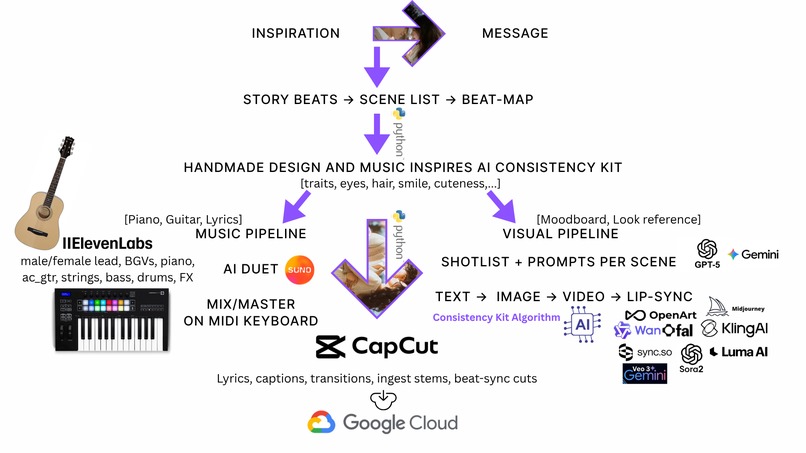
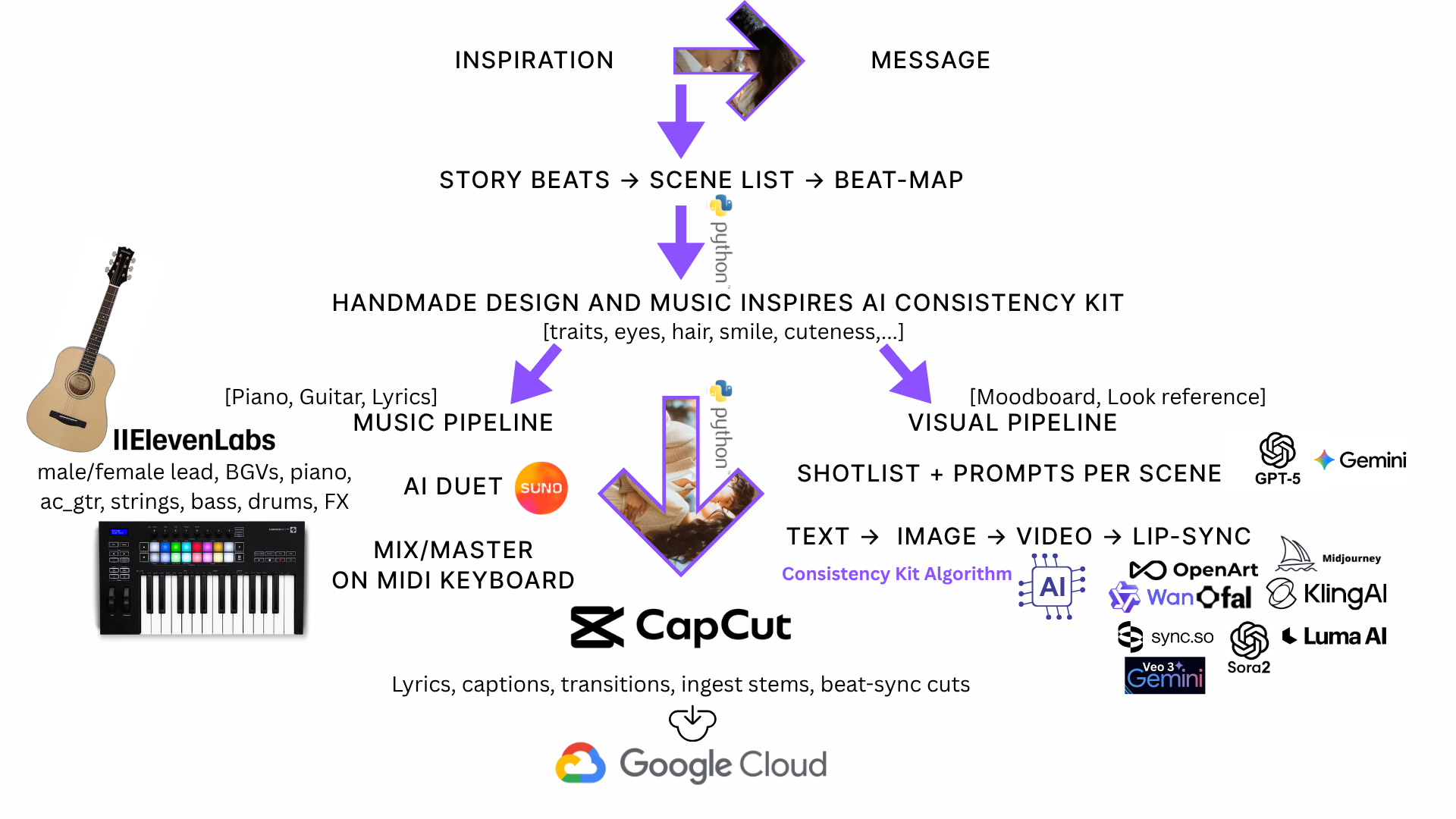
- Multimodal pipeline: real-life story → inspiration → lyrics → music stems → storyboards → images → video shots → lip-sync → edit → mix/master.
Tools
| Category | Tools |
|---|---|
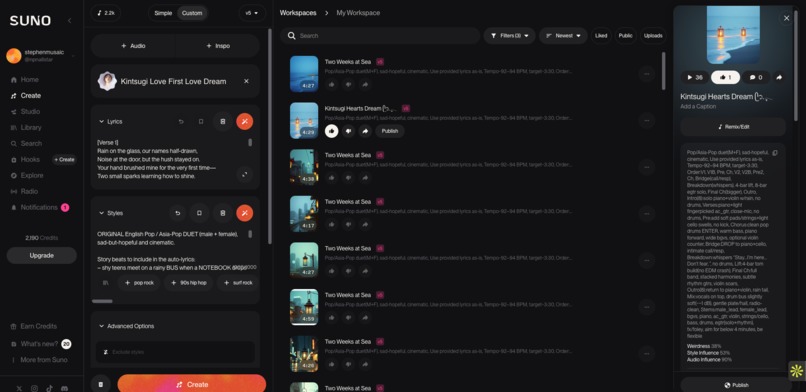
| Music generation | Suno v5, ElevenLabs Music |
| Mixing/MIDI | Ableton Live, Novation Launchkey MK3 (MIDI), GarageBand |
| Multimodal LLMs | GPT-5 Thinking, Gemini 2.5 Pro |
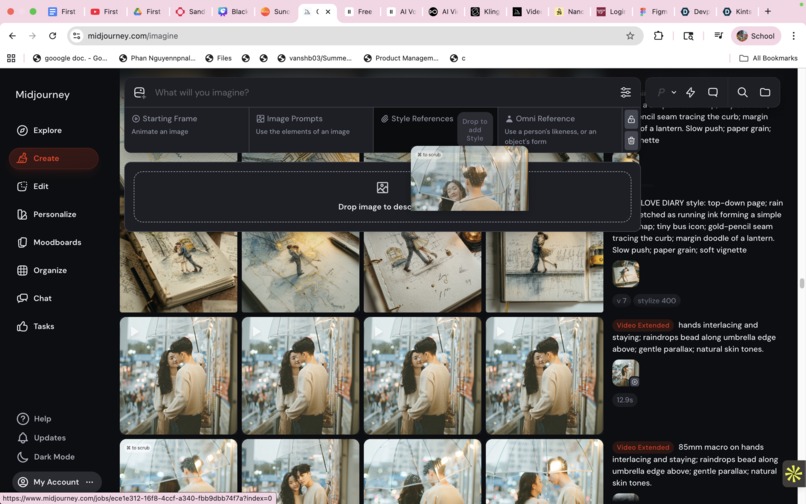
| Images/Style | Midjourney, Gemini 2.5 Flash |
| Text→Video | Kling 2.5, Veo3, Luma AI, Vidu Q2, Sora2, WAN-2.5 |
| Video (general) | Midjourney, Veo3, Sora2, Kling 2.5, FAL (fal.ai), WAN-2.5, Vidu Q2 |
| Elements→Video | Veo3, Midjourney, Vidu Q2 |
| Lip-Sync | OpenArt Lipsync, CapCut, Kling, Sync.so, Nanobanana |
| Edit/Grade | CapCut Pro |
| Model Hub/A-B tests | FAL (fal.ai) |
Model catalog
- Video models used: Veo3, Sora2, Kling 2.5, WAN-2.5, Vidu Q2, Midjourney, Luma AI.
- Lip-sync models: CapCut Lipsync, Kling lipsync, OpenArt Lipsync, Sync.so, Nanobanana.
- Image models: Midjourney, Gemini 2.5 Flash.
- Orchestration/A/B: FAL (fal.ai) hosts multiple image/video back-ends we evaluated.
How we built it
- Inspiration & story — Inspired a real story arc, play a lot of love muscial notes, switched 50+ spots and 6+ cities to work, watched MV lessons, think about the lyrics, video in the shower, on the bus, during lunch time,...
- Lyrics & music — Let our piano and acoustic guitar inspire Suno v5 and ElevenLabs, 500+ words prompt changes 100+ times, used LLM as a conductor and reviewer.
- Characters & Consistency Kit Algorithm — Hand-drawn sheets for female & male (hair, eyes, gestures,...) then our artist add keywords for them, so the actual artist sense could be used to train our AI.
- Storyboards & prompts — Beat-mapped bars→seconds, then wrote Consistency-Kit Algorithm + Scene-Add-On prompts for every shot. To keep AI patterns output consistent, we experimented the prompt changing 80+ times.
- Imagery — Midjourney/Gemini produced style frames and pencil-diary plates; we iterated until faces/props stayed consistent and matched with our story motifs.
- Motion — Veo3/Sora2/Kling/WAN/Vidu turned frames into moving scenes; FAL helped test & lock a single look per sequence.
- Lip-sync — OpenArt/CapCut/Kling/Nanobanana/Sync.so applied natural mouth and micro-expressions on solo and duet lines.
- Edit & finish — CapCut Pro for beat-sync, captions, rain foley; Ableton Live for mix/master; final export 16:9.
Workflow: Real-Life vs AI Music Video
| Stage | Real-Life Music Video | AI Music Video |
|---|---|---|
| 1. Concept & Creative Direction | Brainstorm story/theme/message; define emotion, audience, tone; create moodboard, visual refs, shot list. | Translate human feelings into prompts with GPT-5/Gemini; ideate storyboards/lyric tone; generate concept art & moodboards with Midjourney/FAL; lock visual style (cinematic/diary/pencil). |
| 2. Songwriting & Composition | Write lyrics, melody, chords; record instruments & vocals in studio. | Use Suno/ElevenLabs to draft duet; iterate genre/tempo; export stems (vocals, piano, gtr, strings, bass, drums, FX). |
| 3. Casting & Pre-Production | Hire actors, makeup, costume, crew; scout locations; plan lighting & schedule. | Design virtual characters from hand sketches in Midjourney (Consistency Kit); block scenes with text-to-video (Kling/WAN/Veo/Vidu/Sora); choose lenses/light via prompts. |
| 4. Filming / Production | Shoot with cameras/lighting/greenscreen; record B-roll; multiple takes & angles. | Generate shots with Kling/WAN/Veo/Vidu/Sora; apply expressive face/lip-sync via Nanobanana/OpenArt/CapCut/Sync.so; keep a single look per sequence. |
| 5. Post-Production (Editing) | Edit in Final Cut/Premiere; beat-sync; captions; stylized transitions; unify grade; add logo/credits. | Edit in CapCut Pro; beat-map to stems; captions; warm–cool grade; rain SFX; logo/credits; export 16:9 master. |
| 6. Sound Mixing & Mastering | Balance vocals/instruments; reverb/EQ/compression; deliver master. | Mix Suno stems in Ableton/CapCut; gentle plate/hall; target ~−14 LUFS/−1 dBTP; radio-clean. |
Song Description for AI models
Style: Pop/Asia-Pop duet (male+female); sad-hopeful; cinematic
Tempo/Length: 92–94 BPM; target ≈4:00
Lyrics: Use provided lyrics as-is
Form: Intro(8) → V1 → V1B → Pre → Chorus → V2 → V2B → Pre2 → Chorus → Bridge (call/response) → Breakdown (whispers) → 4-bar Lift → 8-bar e-gtr Solo → Final Chorus (bigger) → Outro
Arrangement
- Intro: solo piano+violin with rain; no drums
- Verses: piano + light fingerpicked acoustic gtr; close-mic; no drums
- Pre: add soft pads/strings; light cello swells; no kick
- Chorus: clean pop drums enter; warm bass; piano forward; wide BGVs; optional violin counterline
- Bridge: DROP to piano+cello; intimate call/response
- Breakdown: whispers “Stay… I’m here… Don’t fear”; no drums
- Lift: 4-bar tom build (no EDM crash)
- Final Chorus: full band; stacked harmonies; subtle rhythm gtrs; violin soars
- Outro(8): return to piano+violin; rain tail
Mix: vocals on top; drum bus slightly soft (~−1 dB); gentle plate/hall; radio-clean
Stems to export: male_lead, female_lead, bgvs, piano, ac_gtr, violin, strings/cello, bass, drums, egtr(solo+rhythm), fx/foley
Built With
Suno v5, Ableton Live, Novation MK3, ElevenLabs Music, GarageBand, Midjourney, Gemini 2.5 Flash, Veo3, Sora2, Kling 2.5, Python, WAN-2.5, Vidu Q2, Fal Sandbox (fal.ai), Sync.co, Luma AI, Nanobanana, OpenArt Lipsync, CapCut Pro, GPT-5 Thinking, Gemini 2.5 Pro.
Consistency Kit Algorithm
to keep AI patterns output consistent - AI Experiment with Python & Math
Automate Consistency Kit, Less Manual Steps, Save Time – Code Snippet:
# 1) Consistency Kit
CONSISTENCY = {
"style": "cinematic diary,pencil/graphite lines,soft film grain,warm tungsten + cool rain rim",
"palette": ["warm_amber", "slate_blue", "soft_ivory", "desaturated_teal"],
"motifs": ["brass lantern","kintsugi gold seams","rain on glass","kraft notebook"],
"female": {
"name": "Sophia",
"hair": "long dark-brown wavy",
"look": "sweet-girl style, shirt+skirt, 5'3, average build",
"persona": "independent,energetic,understanding",
"props": ["kraft notebook","piano"]
},
"male": {
"name": "Bryan",
"hair": "short black, a bit messy",
"look": "T-shirt, baggy jeans, gentle eyes, lean-muscular",
"persona": "soft,protective,thoughtful",
"props": ["brass lantern","mosaic frame"]
}
}
# 2) Prompt template
PROMPT_TMPL = (
"STYLE:{style} | PALETTE:{palette} | MOTIFS:{motifs} | "
"CHARACTERS: {female_look}; {male_look} | "
"SCENE:{scene_desc} | CAMERA:{camera} | LIGHT:{light} | MOOD:{mood} | "
"KEEP: faces consistent, wardrobe consistent, props present (lantern,kintsugi,notebook)"
)
def render_prompt(scene_desc:str, camera:str, light:str, mood:str) -> str:
return PROMPT_TMPL.format(
style=CONSISTENCY["style"],
palette=",".join(CONSISTENCY["palette"]),
motifs=",".join(CONSISTENCY["motifs"]),
female_look=CONSISTENCY["female"]["look"],
male_look=CONSISTENCY["male"]["look"],
scene_desc=scene_desc, camera=camera, light=light, mood=mood
)
# 3) Scene spec
@dataclass
class Scene:
id: str
kind: str # "image" | "video" | "lipsync" | "music" | "llm"
provider: str # e.g. "fal", "wan", "kling", "openart_lipsync", "elevenlabs", "suno"
scene_desc: str
camera: str = "35–50mm, shallow DOF, slow push-in"
light: str = "warm tungsten key, cool rain rim"
mood: str = "sad-hopeful, intimate"
ref_images: List[str] = None # optional URLs or local paths (pencil+real refs)
# 4) Provider adapters
def call_llm_rewrite(prompt:str) -> str:
"""Optional: have an LLM polish the prompt for the target model style."""
# Example w/ OpenAI-compatible endpoint
url = os.getenv("LLM_URL") # e.g. https://api.openai.com/v1/chat/completions
key = os.getenv("LLM_API_KEY")
if not url or not key:
return prompt
headers = {"Authorization": f"Bearer {key}"}
payload = {
"model": os.getenv("LLM_MODEL","gpt-4o-mini"),
"messages": [
{"role":"system","content":"Rewrite for text-to-(image|video) model; keep constraints; no extra fluff."},
{"role":"user","content":prompt}
]
}
try:
r = requests.post(url, headers=headers, json=payload, timeout=60)
r.raise_for_status()
return r.json()["choices"][0]["message"]["content"].strip()
except Exception:
return prompt
def submit_image_fal(prompt:str, refs:List[str]|None)->Dict[str,Any]:
# Placeholder: swap with fal.ai image endpoint + ref images
return {"status":"queued","provider":"fal","prompt":prompt,"refs":refs}
def submit_video_wan(prompt:str, refs:List[str]|None)->Dict[str,Any]:
# Placeholder: WAN.video/Kling/Vidu/Q2 adapter
return {"status":"queued","provider":"wan","prompt":prompt}
def submit_lipsync_openart(audio_url:str, frame_img:str)->Dict[str,Any]:
# Placeholder: OpenArt Lipsync (image→talking video)
return {"status":"queued","provider":"openart_lipsync","frame":frame_img,"audio":audio_url}
def submit_music_suno(song_desc:str)->Dict[str,Any]:
# Placeholder: Suno/ElevenLabs Music request
return {"status":"queued","provider":"suno","desc":song_desc}
# Router
def dispatch(scene:Scene, prompt:str)->Dict[str,Any]:
match scene.kind, scene.provider:
case ("image","fal"):
return submit_image_fal(prompt, scene.ref_images)
case ("video","wan"):
return submit_video_wan(prompt, scene.ref_images)
case ("lipsync","openart_lipsync"):
# example requires you to have pre-rendered vocal line
return submit_lipsync_openart(audio_url=os.getenv("LYRIC_LINE_URL",""), frame_img=scene.ref_images[0])
case ("music","suno"):
return submit_music_suno(prompt)
case _:
return {"status":"skipped","why":"no adapter"}
# 5) Batch runner
def run_batch(scenes:List[Scene], use_llm=True) -> List[Dict[str,Any]]:
jobs=[]
for sc in scenes:
base_prompt = render_prompt(sc.scene_desc, sc.camera, sc.light, sc.mood)
final_prompt = call_llm_rewrite(base_prompt) if use_llm else base_prompt
job = dispatch(sc, final_prompt)
job["id"]=sc.id; job["prompt"]=final_prompt
jobs.append(job)
time.sleep(0.2) # be polite to APIs
return jobs
# 6) Example
if __name__ == "__main__":
scenes = [
Scene(id="C01", kind="image", provider="fal",
scene_desc="Rainy window; reflection of brass lantern; kintsugi frame on sill; pencil-diary texture",
ref_images=["/refs/sophia_pencil.png","/refs/bryan_pencil.png"]),
Scene(id="C02", kind="video", provider="wan",
scene_desc="City bus arrives in rain; sodium lights; wet asphalt reflections; handheld gentle"),
Scene(id="CH1_A", kind="lipsync", provider="openart_lipsync",
scene_desc="Sophia close-up by window, warm tungsten/cool rim; sing 'We don’t have much, but we have a light'",
ref_images=["/frames/sophia_close.png"]),
Scene(id="MUS1", kind="music", provider="suno",
scene_desc="Pop/Asia-Pop duet ~93 BPM, intro piano+violin, sad-hopeful; use provided lyrics verbatim")
]
out = run_batch(scenes, use_llm=True)
print(json.dumps(out, indent=2))
Consistency Kit Algorithm – Code Snippet:
from dataclasses import dataclass
import numpy as np
@dataclass
class Kit:
face_emb: np.ndarray # ArcFace mean emb
clip_txt: np.ndarray # CLIP text/style emb
palette_lab: np.ndarray # LAB palette (N x 3)
thresholds: dict # {"face":0.60,"color":3.0,"flow":1.5}
controls: dict # default ip/pose/cfg/denoise
seeds: dict # {"image":1234,"video":5678}
@dataclass
class Scene:
text: str
pose: np.ndarray | None
add_on: dict # lens, light, props, etc.
def acs(scene, kit, driver, trials=16):
w = {"face":.4,"clip":.2,"color":.2,"prop":.1,"temp":.1}
best = None
for h in sample_hparams(kit.controls, kit.seeds, trials):
prompt = render_prompt(scene, kit, h) # Consistency Kit + Scene Add-On
shot = driver.generate(prompt, h) # image or short clip
m = measure(shot, kit, scene) # dict of raw metrics
f = {
"face": face_score(m["face_dist"], kit.thresholds["face"]),
"clip": m["clip_sim"],
"color": np.exp(-m["deltaE_mean"]/max(kit.thresholds["color"],1e-6)),
"prop": prop_score(m["props"]),
"temp": temp_score(m) # uses flow/face drift if video
}
S = sum(w[k]*f[k] for k in w)
rec = {"S":S,"m":m,"f":f,"h":h,"prompt":prompt,"shot":shot}
if best is None or S>best["S"]: best = rec
if pass_hard(m, kit.thresholds): return rec # early accept
# emphasize violated terms
for k in w:
if violated(m, k, kit.thresholds): w[k] *= 1.5
Z = sum(w.values()); w = {k:v/Z for k,v in w.items()}
return best
# scoring helpers (stubs you replace with your libs)
def face_score(d, tau): return np.clip((tau-d)/max(tau,1e-6), 0, 1)
def prop_score(props): # props={"lantern":p,"kintsugi":q}
sig = lambda z: 1/(1+np.exp(-z))
return sig(props.get("lantern",0)-.5)*sig(props.get("kintsugi",0)-.5)
def temp_score(m):
if "flow_epe" not in m: return 1.0
l1,l2,l3 = .8,.1,.1
return float(np.exp(-(l1*m["flow_epe"]+l2*m.get("deltaE_t",0)+l3*m.get("face_dist_t",0))))
def pass_hard(m, th):
ok = (m["face_dist"]<=th["face"] and m["deltaE_mean"]<=th["color"] and m["props_ok"])
if "flow_epe" in m: ok &= (m["flow_epe"]<=th.get("flow",10.0))
return ok
def violated(m, key, th):
checks = {
"face": m["face_dist"]>th["face"],
"color": m["deltaE_mean"]>th["color"],
"prop": not m["props_ok"],
"clip": m["clip_sim"]<0.30,
"temp": m.get("flow_epe",0)>th.get("flow",10.0)
}
return checks[key]
# you implement: sample_hparams, render_prompt, driver.generate, measure
What’s next
- Publish a prompt & pipeline template so others can make emotionally coherent AI MVs.
- Explore multi-lingual versions with localized lyric captions.
- Release instrumental & stems for community remixes.
- Partner with local bands and artists to support them with AI.
- Perform with our AI MV and karaoke version.
- Improve MV structure and song quality.
Lyrics — Kintsugi Hearts Dream
[Verse 1]
Rain on the glass, our names half-drawn,
Noise at the door, but the hush stayed on.
Your hand brushed mine for the very first time—
Two small sparks learning how to shine.
[Verse 1B]
Bus seats hum under city gray,
Pages slipped open when your notebook strayed.
A shy “hello,” a glance held long—
Love hummed softly before it learned a song.
[Pre-Chorus]
If the night stands tall, we’ll make it small,
We won’t leave the room when the storm comes to call.
[Chorus]
We don’t have much, but we have a light,
A lantern kept in each other’s sight.
If everything breaks, we’ll gold the seam—
Kintsugi hearts in a first-love dream.
Hold on to me when the colors drain,
I’ll paint them back with your name.
We’re not unscarred, but we’re still bright—
You and I, where we keep the light.
[Verse 2]
Tiny café with the hairline cups,
You take the wind and you hold me up.
First time our fingers decided to stay—
Two quiet bravest on a rainy day.
[Verse 2B]
Blue-shard frame where a vase once broke,
We learned to mend by the words we spoke.
Little brave things that we do each day—
That’s how we stay when the world won’t stay.
[Pre-Chorus 2]
If the rain runs hard, let it write our street,
I’ll count your breaths while you count my beats.
[Chorus]
We don’t have much, but we have a light,
A lantern kept in each other’s sight.
If everything breaks, we’ll gold the seam—
Kintsugi hearts in a first-love dream.
Hold on to me when the colors drain,
I’ll paint them back with your name.
We’re not unscarred, but we’re still bright—
You and I, where we keep the light.
[Bridge – call & response, hush]
(You) If distance grows, I’ll leave the door wide.
(Me) Porch light on—I'm on your side.
(You) If years draw maps across our skin,
(Me) Read them home, then start again.
(Both) When I lose my way, say my name—
I’ll find you waiting in the frame.
[Breakdown – whispers]
Stay… stay… (I’m here.)
Stay… stay… (Don’t fear.)
[Instrumental – 8 bars]
// melodic violin solo quoting the chorus motif
[Final Chorus – bigger, stacked harmonies]
We don’t have much, but we have a light,
A lantern held through the tender night.
If everything breaks, we’ll gold the seam—
Kintsugi hearts in a first-love dream.
Hold on to me when the colors drain,
I’ll sing them back with your name.
We’re not unscarred, but we’re still bright—
First love, forever—where we keep the light.
[Outro]
Breathe with me slow till the stars grow kind,
Two hands, one room, and an endless time.
If the world goes quiet, we’ll be alright—
You in my chest, where I keep the light.
Submission for: www.ChromaAwards.com
Thank you everyone for watching! Thank you for your support and AI credits!
Built With
- abletonlive
- capcut
- fal.ai
- gemini2.5
- gpt5
- humanhands
- klingai
- llm
- lumaai
- midjourney
- nanobanana
- novationmidikeyboard
- openart
- openart-lipsync
- python
- sunov5
- sync.so
- topazvideoenhancer
- wan.video





Log in or sign up for Devpost to join the conversation.