-
-
Brand Page
-

How Kinetiq Works
-

Solution
-

Benefits of Kinetiq
-
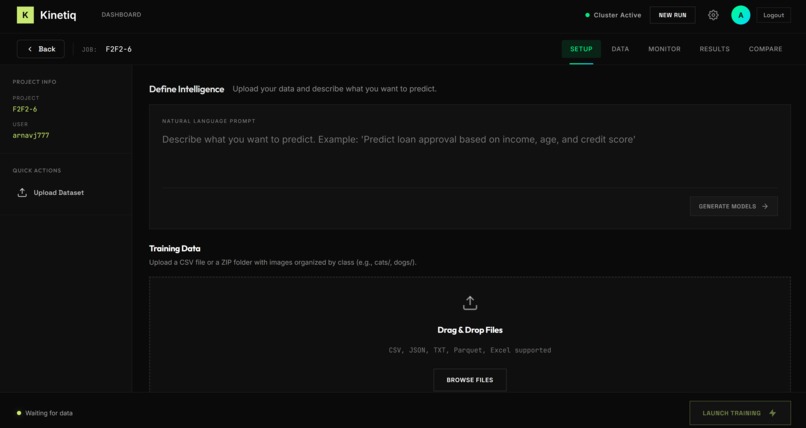
Trainer
-
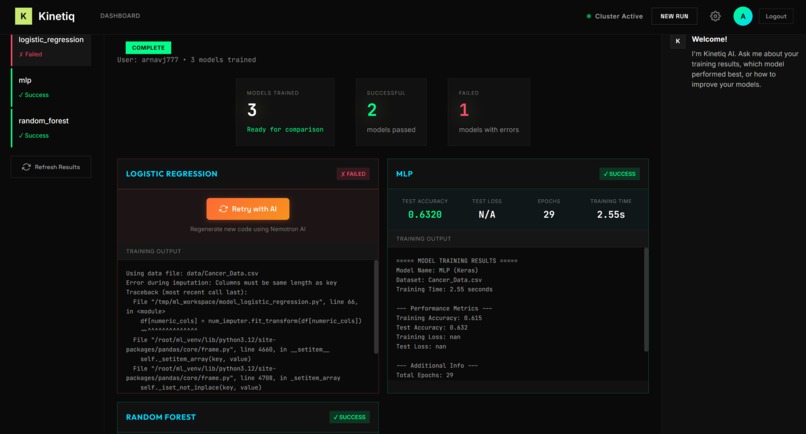
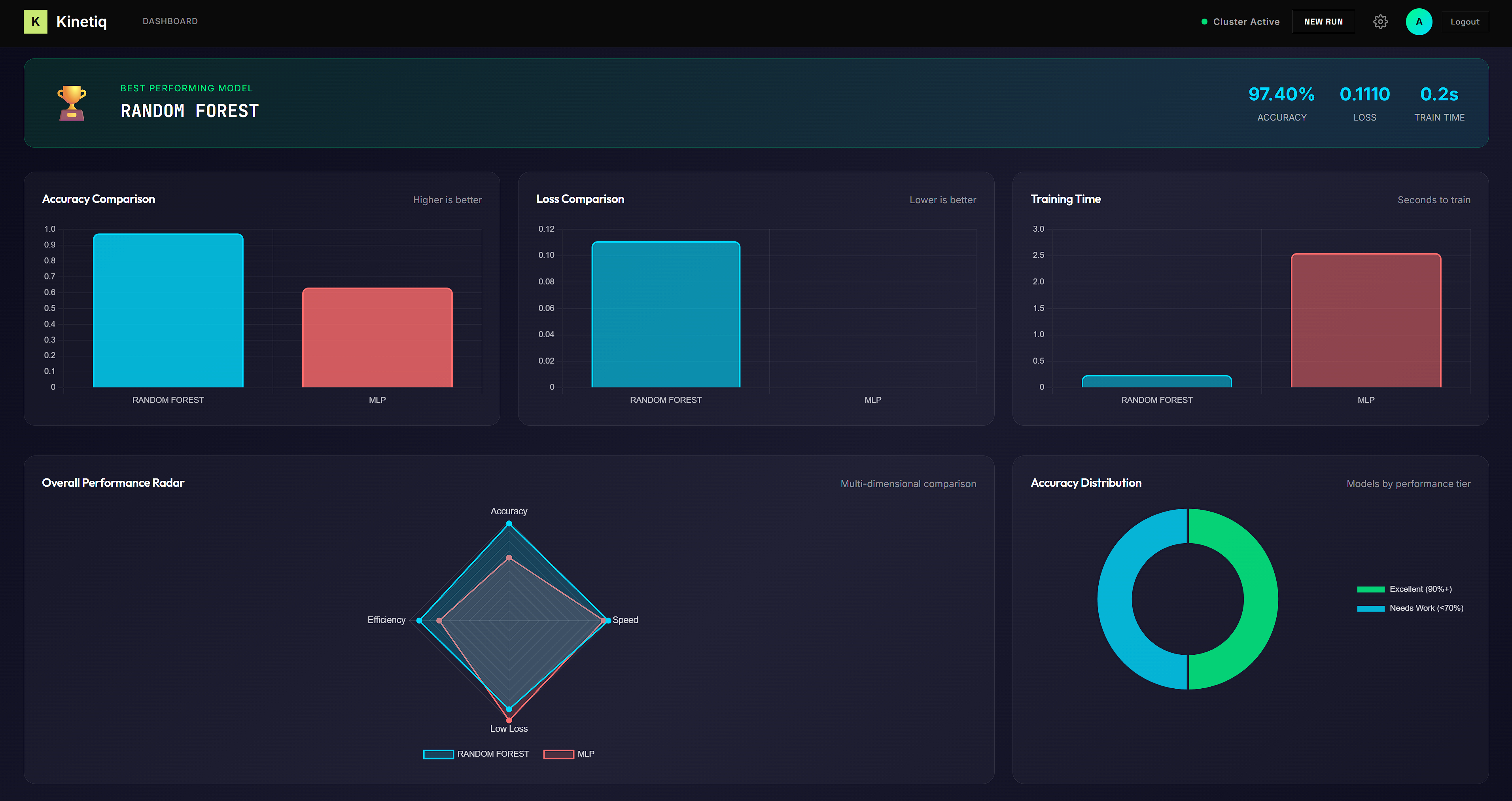
Results
-
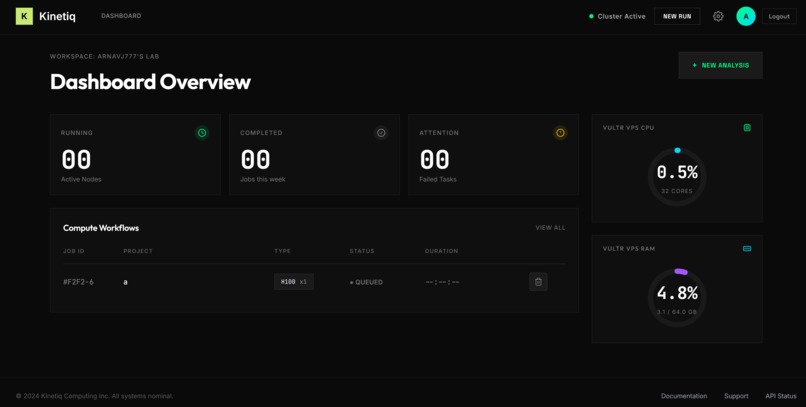
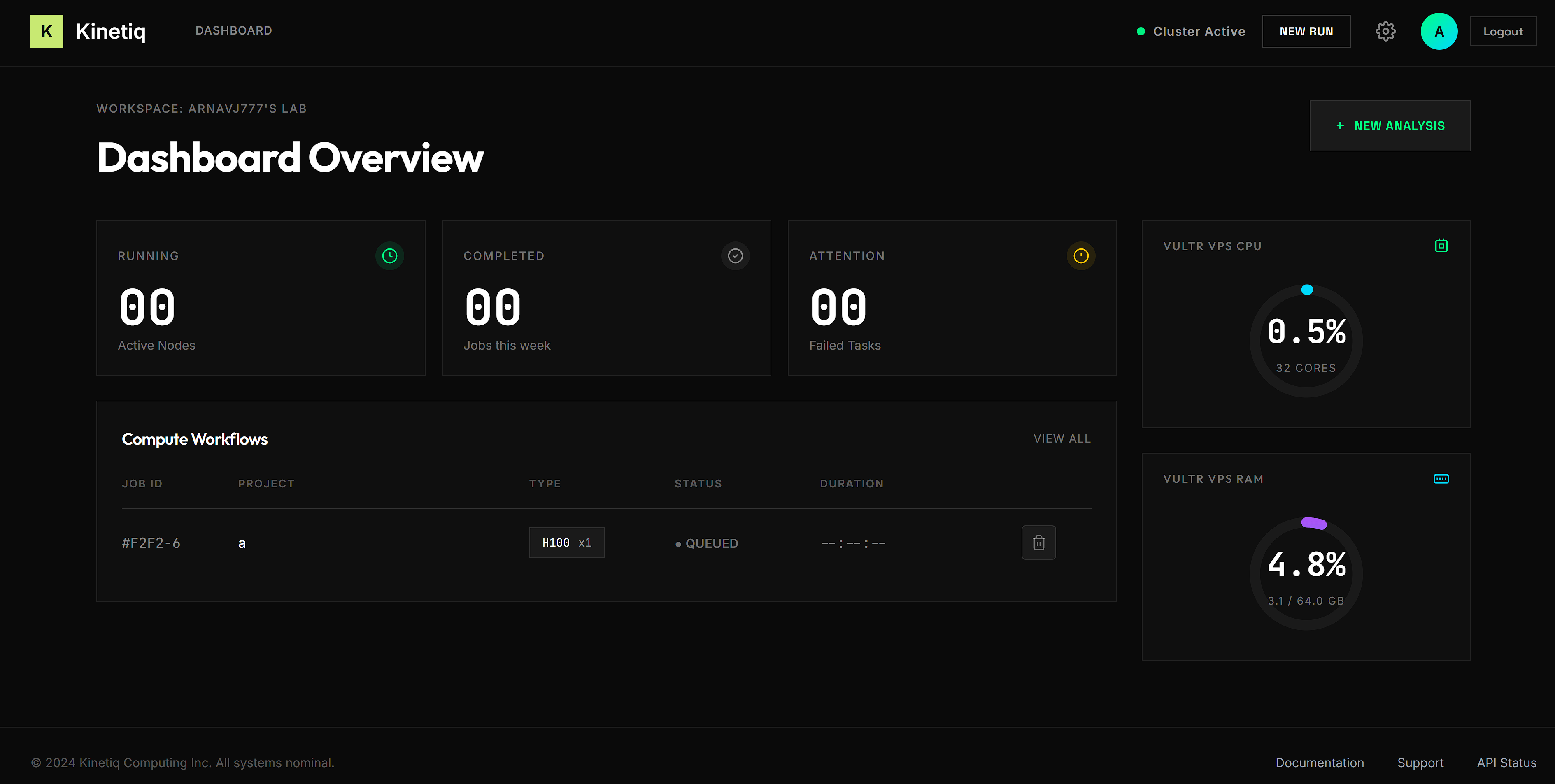
Dashboard
-
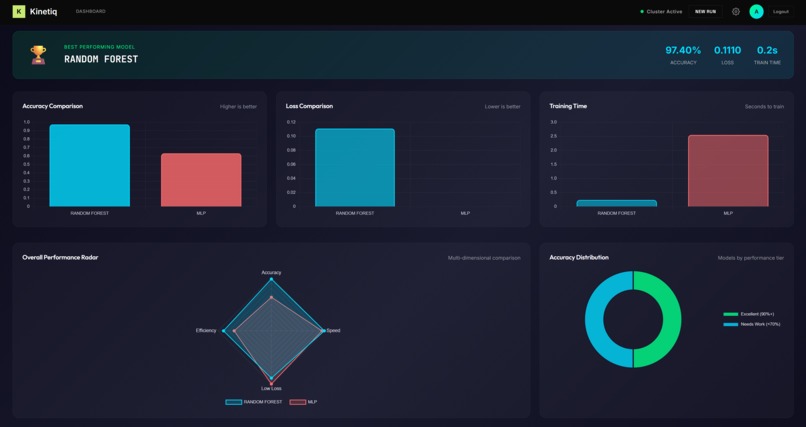
Graphs



Zoom Link: https://tamu.zoom.us/j/98805883312
🌌 Kinetiq: The Superintelligence Cloud
From Raw Data to Trained Models in a Single Prompt
💡 Inspiration
Machine learning is undeniably powerful, but often inaccessible. Setting up environments, choosing the right model, and tuning hyperparameters requires expertise that creates a barrier for students, researchers, and small teams.
The Mission: We wanted to build a platform where anyone could go from raw data to trained model results with just a prompt—no local GPU required, no environment headaches, and no ML PhD needed.
🧠 What it does
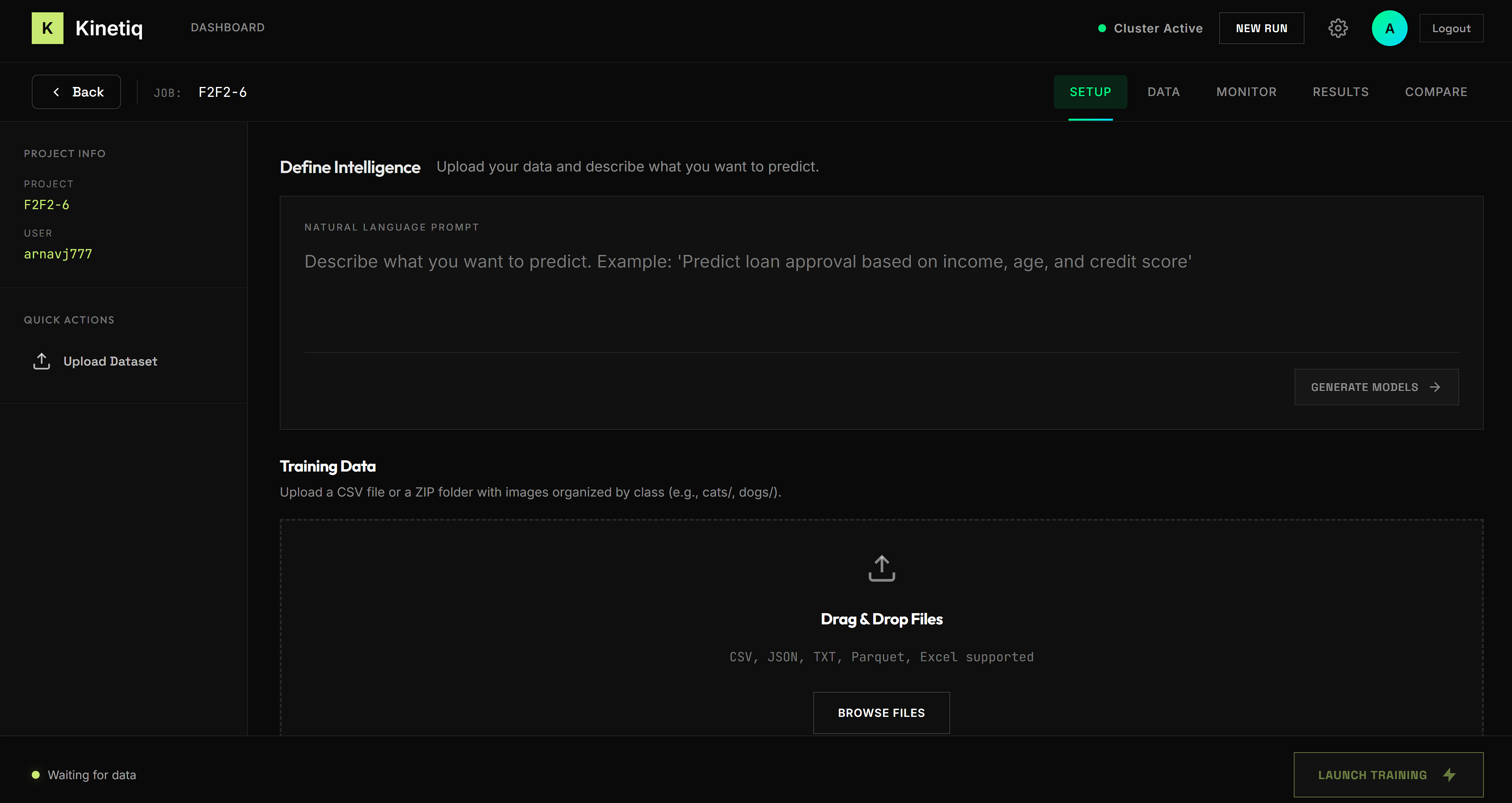
Kinetiq is an AI-powered, cloud-native ML training platform. Users upload their dataset (CSV or image ZIP), describe their goal in plain English, and Kinetiq handles the rest:
- 🤖 AI-Generated Code: NVIDIA Nemotron analyzes the data and writes multiple, production-ready Python training scripts (e.g., Random Forest, MLP, CNN).
- ☁️ Remote Execution: The generated scripts are sent to a high-performance Vultr cloud server, freeing the user's machine.
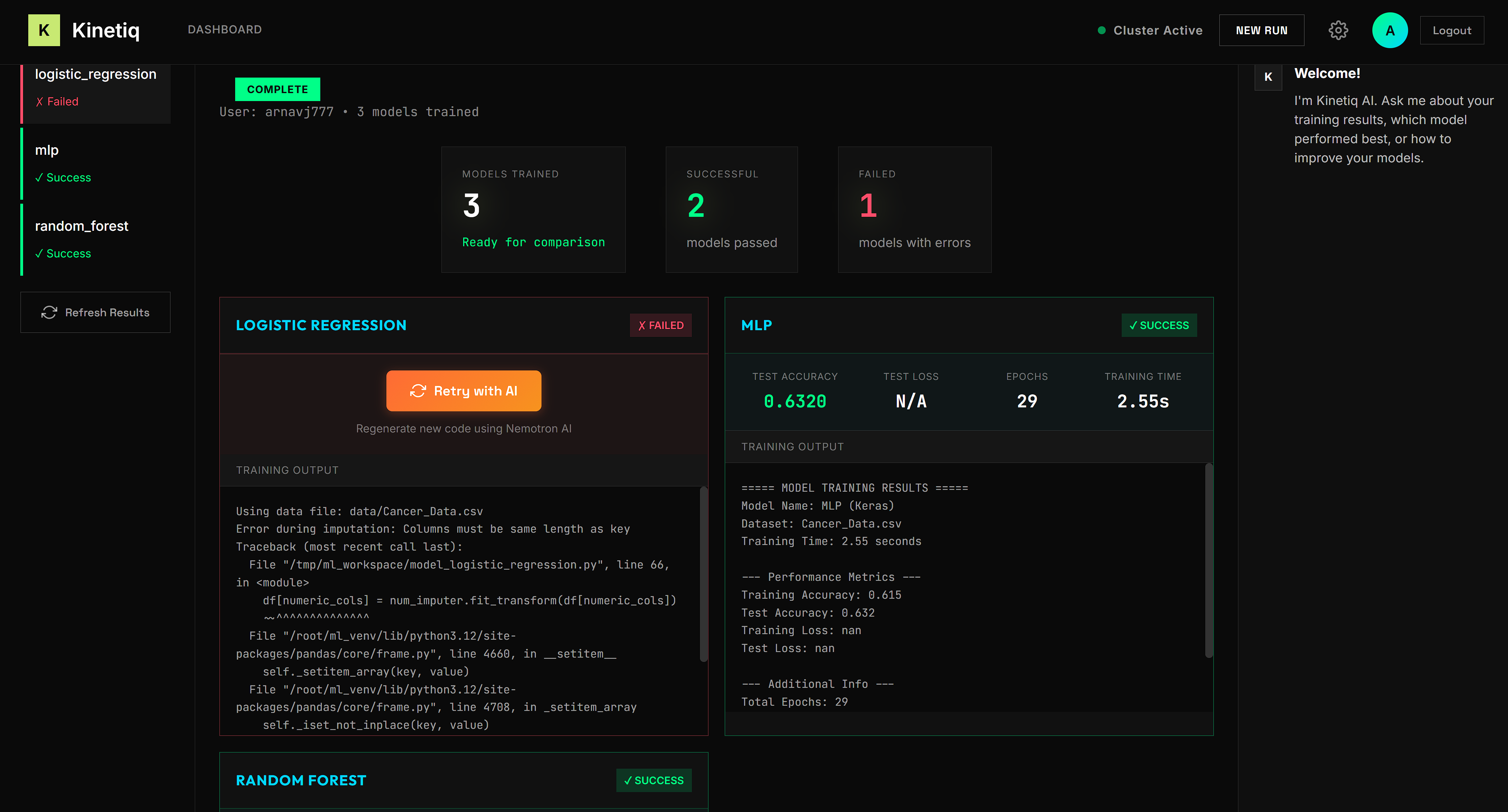
- 📊 Comparative Results: Once training completes, users see a side-by-side comparison of model accuracy, training time, and other metrics—all without writing a single line of code.
To evaluate model performance, Kinetiq computes metrics like accuracy: $$\text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN}$$
🛠️ How we built it
| Layer | Technology |
|---|---|
| Frontend | React + Vite for a fast, responsive dashboard |
| Backend | Django REST Framework for API endpoints, user auth, and job orchestration |
| Cloud Infrastructure | Vultr Object Storage (S3-compatible) and Vultr cloud compute instances |
| AI/LLM | NVIDIA Nemotron for intelligent, data-aware code generation |
| Orchestration | Paramiko for SSH-based remote command execution and asynchronous jobs |
| Containerization | Docker Compose for reproducible environments |
⚔️ Challenges we ran into
- 🔗 Remote Execution Reliability: SSHing into a server, piping dynamically generated Python code, and handling stdout/stderr across network boundaries was tricky. We had to carefully manage timeouts, escaping, and error propagation.
- 📝 LLM Output Consistency: Getting Nemotron to produce valid, runnable Python code with a consistent output format required iterative prompt engineering and robust regex parsing.
- 🚀 Data Synchronization: Uploading and managing large ZIP files across Object Storage required optimizing for speed by extracting on the server rather than handling files individually.
🏆 Accomplishments that we're proud of
- ⏱️ Zero-to-Results in Minutes: A user can go from a raw CSV upload to seeing trained model metrics in under 5 minutes, with no local setup.
- 🧬 Model Diversity: The LLM chooses different algorithms based on the actual data characteristics, considering feature count, data size, and task type.
- 💨 Fully Cloud-Native: The user's laptop never does any heavy lifting; all compute happens on demand in the cloud.
🔮 What's next for Kinetiq
Our current model training happens sequentially: $$\text{Total Time} = \sum_{i=1}^{n} T_i$$
We plan to transition to a Parallel Execution Model: $$\text{Total Time} = \max(T_1, T_2, \dots, T_n) + \epsilon$$
- 🎮 GPU Support: Enable CUDA-accelerated training on Vultr GPU instances for deep learning tasks.
- 🚀 Parallel Model Training: Run all generated models simultaneously to reduce total wait time.
- 🌐 Model Deployment: One-click deployment of the best-performing model to a live API endpoint.
- 👥 Collaboration Features: Share projects with teammates and track experiment history.

Log in or sign up for Devpost to join the conversation.