-
-

kinetic
-
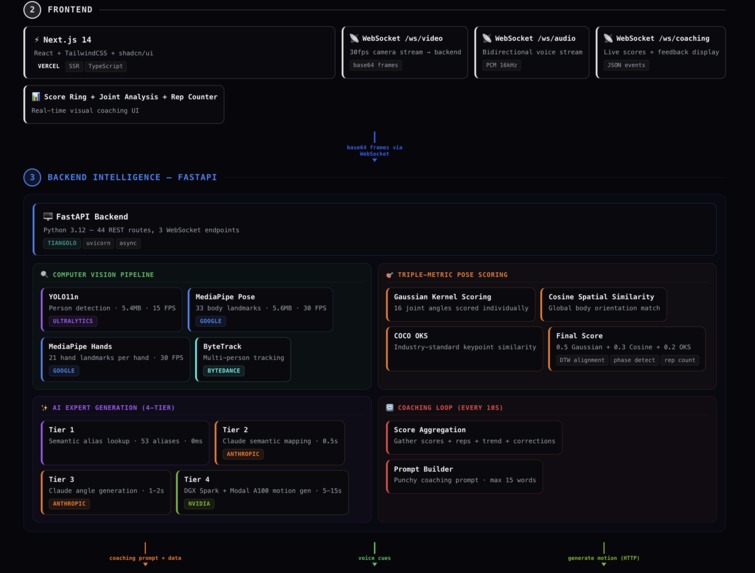
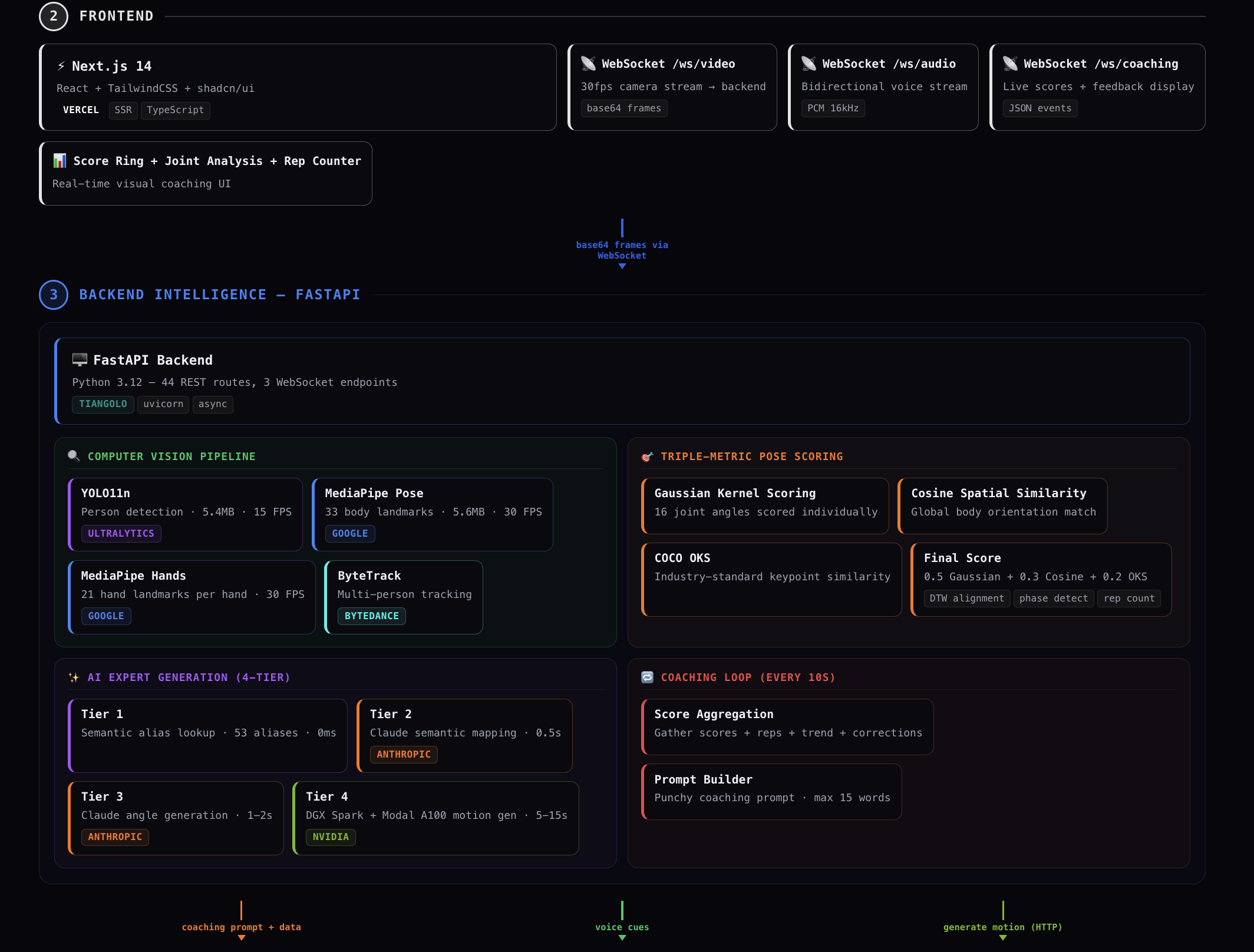
frontend and backend
-
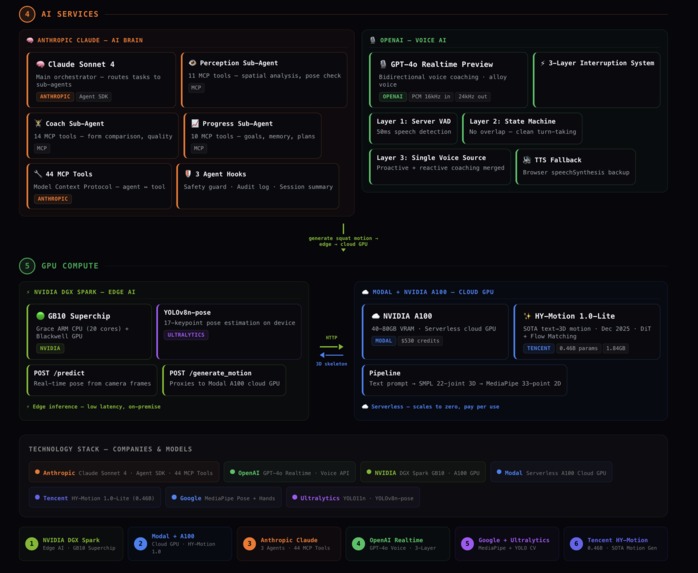
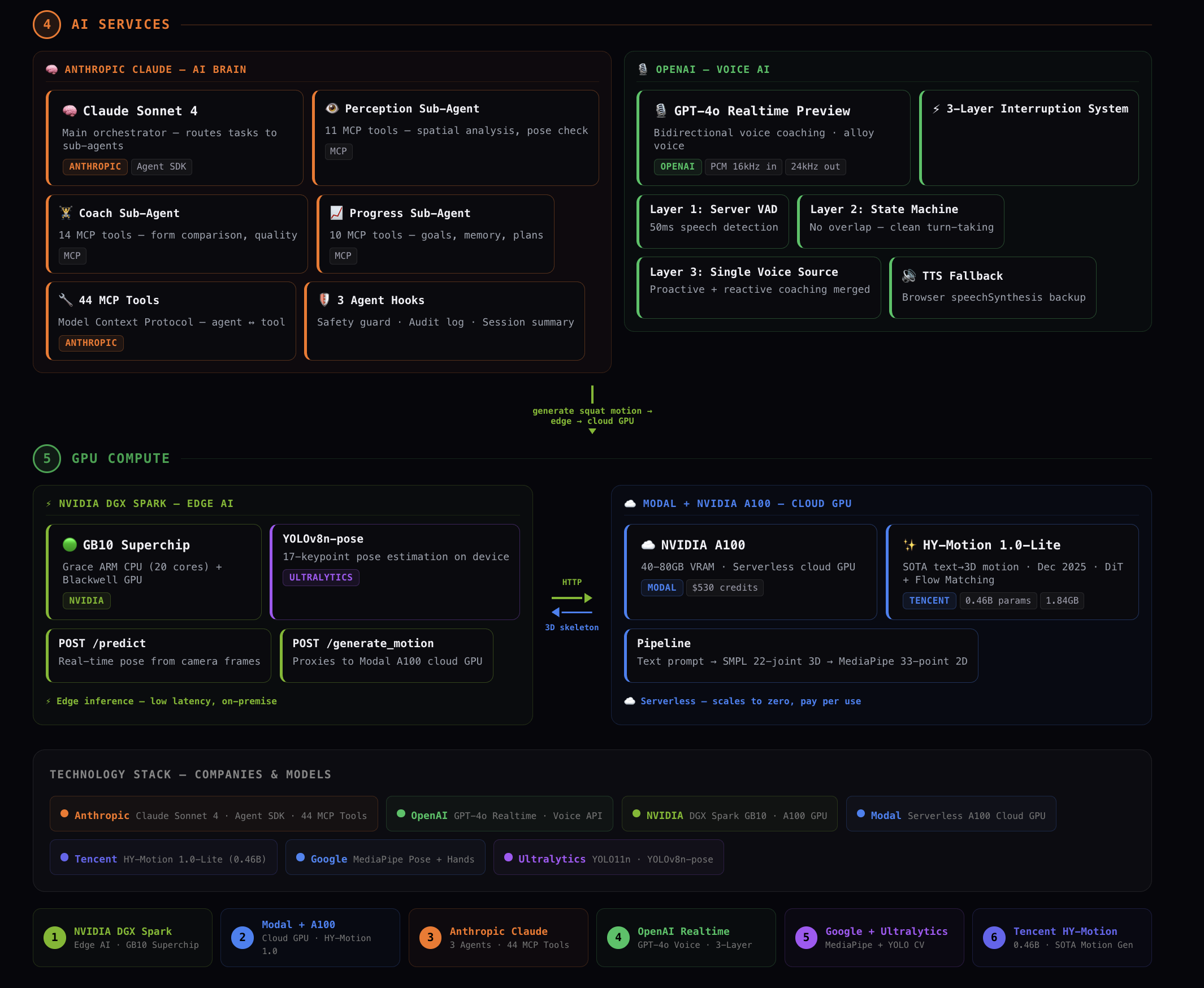
techStack

Inspiration
AI helps us write, code, and reason — but human physical capability remains unaugmented. Quality coaching costs $80–200/hour, PT is $100+/hour, and 55 million elderly Americans need fall monitoring that costs hospitals billions in patient sitter programs annually.
These aren't separate problems. They're all the same gap: no cognitive layer for physical capability. We asked: what if one camera and one AI could coach a squat, detect a grandmother falling, guide PT rehab, and monitor a hospital room overnight?
What It Does
Kinetic is a real-time Physical Movement Intelligence platform with four modes from one stack:
AI Skill Coach — Describe any movement and Kinetic generates the ideal form via a 4-tier pipeline (templates → Claude mapping → Claude angle generation → HY-Motion diffusion on A100 GPU). It tracks your body at 30 FPS, scores form with a triple-metric engine, and coaches via real-time voice.
Physical Therapy — PT-specific categories (knee, shoulder, hip, ankle rehab). Tracks range of motion, enforces safety limits, auto-counts reps via phase detection, and adapts voice coaching to gentle rehab context.
Goal-Based Intelligence — Give Kinetic any goal and step away. Presets include fall detection, desk security, posture watch, driver alertness, and study focus. It runs a continuous perception→reasoning→action loop, sending Telegram alerts with photos autonomously.
Clinical Patient Safety — Hospital-grade monitoring: fall detection, bed exit alerts, immobility/pressure ulcer prevention, IV line safety, post-op distress, and wandering/elopement detection. Alerts nurses via Telegram with snapshot photos instantly.
46 MCP tools are exposed via HTTP so external AI agents (including Poke) can drive the entire stack programmatically.
How We Built It
DGX Spark — YOLOv8n-pose on the GB10 Superchip for sub-50ms edge pose estimation at 15+ FPS. (17 key points)
Modal A100 — Tencent's HY-Motion 1.0-Lite (0.46B param text-to-3D motion diffusion, Dec 2025) generates 30-frame skeleton sequences from text prompts in ~26s. Three model weights (~20GB) cached in Modal Volumes. https://rajashekarvennavelli--aegis-motion-generate-endpoint.modal.run`
Claude Agent SDK — 46 MCP tools across 12 categories, 3 sub-agents (perception, coach, communicator), safety hooks, and audit logging. Claude reasons about movement, coaching, and spatial safety across all modes.
OpenAI Realtime Voice — Bidirectional audio with interruption handling and context injection every 5 seconds. Voice adapts per mode: gym coach, PT encourager, or urgent fall alerter.
Triple-Metric Scoring — Gaussian joint angles (0.4) + cosine spatial similarity (0.3) + COCO OKS (0.3) for scoring that catches errors single metrics miss.
Autonomous Monitoring — Background loop every 3s detects falls, bed exits, immobility, and wandering. Sends Telegram photo alerts, voice alerts, and Claude analysis simultaneously. Controllable via Telegram commands.
Frontend — Next.js + Tailwind + shadcn/ui. Four mode cards, coaching UI with 10 skill categories, monitoring dashboard with live camera + alert timeline + agent tool call visualization.
Challenges We Ran Into
HY-Motion on Modal — 20GB of model weights, relative path issues, dozens of build iterations, and mapping 52-joint output to MediaPipe 33-point format. The hardest single technical challenge. https://rajashekarvennavelli--aegis-motion-generate-endpoint.modal.run
Real-time scoring at 30 FPS — DTW temporal alignment, phase detection, and triple-metric computation all under 5ms per frame via pre-normalization and caching.
Voice + vision sync — Three-way latency (audio 200ms, video 50ms, Claude 1-2s) solved with context injection architecture — voice always references current form, not stale data.
Clinical reliability — Fall detection can't have false negatives. Temporal smoothing, priority boosting for safety-critical activities, and hysteresis prevent state flickering.
Accomplishments That We're Proud Of
- Four modes, one stack — coaching, PT, autonomous monitoring, and clinical safety all share the same CV + agent + voice pipeline
- Working text-to-3D motion — HY-Motion generating real physics-aware skeleton sequences, animated live on the frontend
- Autonomous fall → Telegram pipeline — zero human intervention from detection to nurse alert with photo
- 46 MCP tools as HTTP — the entire physical intelligence stack is callable by any external AI agent
What We Learned
Physical intelligence is AI's next frontier — coaching, rehab, monitoring, and safety are all the same capability: perceiving movement and reasoning about what should change.
Edge AI changes everything — sub-50ms pose estimation makes coaching feel human and fall detection truly real-time.
Voice is the only viable physical interface — you can't touch a screen mid-pushup. Realtime bidirectional voice makes AI coaching natural.
Modularity enables pivoting — separate subsystems let us add PT, monitoring, and clinical modes without breaking existing functionality.
What's Next for Kinetic
- AR glasses — overlay the expert skeleton directly in the user's field of view for truly hands-free coaching
- Multi-camera fusion — stereo depth for accurate 3D joint angles, eliminating single-camera occlusion blind spots
- Clinical integration — FHIR/EHR export of ROM data, rep counts, and progress for clinician dashboards
- Hospital deployment — ceiling-mounted cameras augmenting clinical staff, enabling one nurse to safely monitor multiple rooms simultaneously
- Personalized models — fine-tuned to individual body proportions and injury history for adaptive coaching thresholds
Built With
- claude
- dgx
- jetson-nano
- modal
- nextjs
- python
- typescript

Log in or sign up for Devpost to join the conversation.