-
-
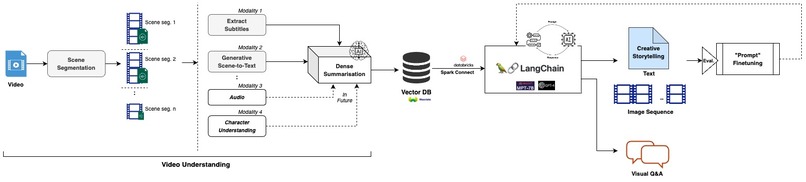
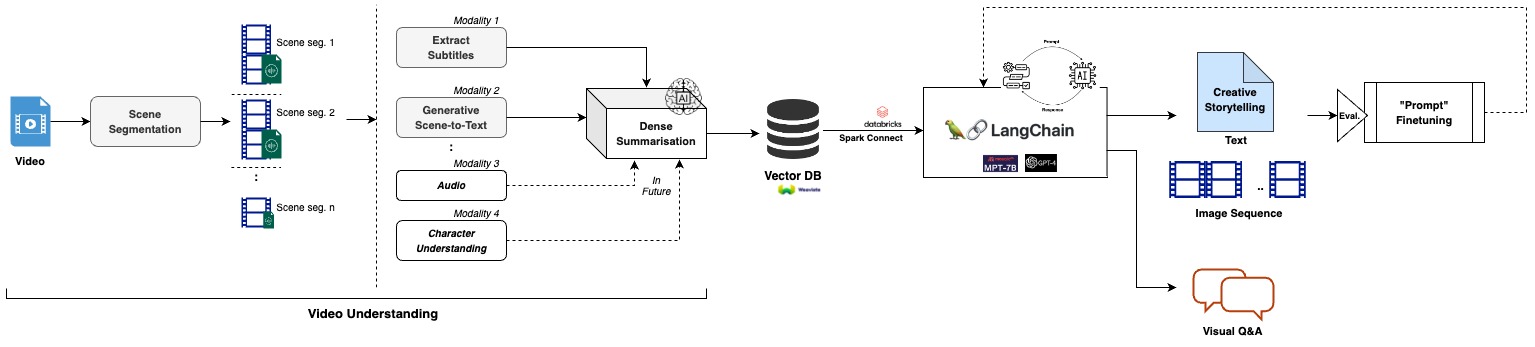
Video understanding - a multimodality framework
Inspiration
Crafting a well-structured and coherent story requires careful planning and organization. Every story has a beginning, a middle and an end with a logical flow of events that engage the audience. Maintaining consistency, and ensuring that all elements fit together seamlessly can be a complex task. In this regard, visual storytelling presents its own unique set of challenges with creating engaging narratives, vivid descriptions, and relatable characters to share an emotion. Systematically generating a coherent and interesting story by a machine (creative writing) requires various capabilities in natural language processing, event comprehension, character understanding, and plot development.
“Every film should have its own world, a logic and feel to it that expands beyond the exact image that the audience is seeing.” — Christopher Nolan
What it does
Objective
(1) Understand a story-based long video (aka long-form video understanding) in a multi-modality setting with the convergence of Vision, Audio, and Subtitle Text.
(2) Generate coherent and interesting stories (original and alternate) from this understanding, in the form of: (a) Script (/text), (b) Image sequence (/visual narrative)
(3) Develop a framework to interact with the media (Visual Q&A).
Value Proposition
(1) Inspire engagement and drive sales conversion across marketing channels, with persona-based immersive creative - every story is unique!
(2) Data-driven dynamic visual content creation and personalisation based on consumer preferences, demography and location.
(3) Multivariate testing and experimenting on-the-fly with multiple creative variants.
(4) Increase product discovery, and brand recall through personalized storytelling. (Interesting statistic: According to Hubspot, nearly nine out of ten people surveyed want to see more videos from brands (advertisements), making video an excellent tool for lead generation and brand awareness).
(5) Boost productivity and efficiency of creative teams.
How we built it
Input: Story-based long video
Step 1: Scene Segmentation (chunk long-form video into scenes)
Step 2: Use Generative Image-to-text Transformer, GIT (Wang et.al.), to unify the vision-language tasks of video (/scene) captioning.
Step 3: Extract Subtitle Text/captions from the video.
Step 4: Combine the two modalities of information to build in-context few-shot learning via prompting. Provide this context to LangChain by leveraging Spark Connect.
Step 5: Generate a story with Prompt Engineering, leveraging open-source LLM like MPT-7B
Step 6: Evaluate the quality of the generated story i.e. evaluate if the prompts performed comparably with our manually written creative and also the one generated with ChatGPT.
Step 7: “Prompt” the model to generate coherent outputs with alternate and diverse storytelling that inspire engagement.
Challenges we ran into
(1) Dense captioning, capturing the characters, and different instances of them in image sequences. This is important for the visual story generation models.
(2) Representation of narrative structures, including the concept of a beginning, middle, and end, as well as the identification of key story elements such as protagonists, conflicts, and resolutions.
(3) Capturing visual elements and composition.
Accomplishments that we're proud of
(1) Create a framework for systematically generating coherent and interesting stories by a machine.
(2) Convergence of language and vision, for multimodal video understanding.
(3) Use of LangChain for multimodal application development.
(4) Explored VectorDB (e.g.: Weaviate) and in-context learning techniques to vectorize and store the multiple modalities - couldn’t be implemented due to time constraints.
What we learned
(1) In-depth understanding of multimodal foundational models like BEiT3 (W Wang et.al.), GIT (J Wang et.al.), mPLUG-2 (Xu et. al.) and VAST (Chen et. al.).
(2) Versatility of LangChain and its usefulness in developing LLM applications.
(3) Capability of LLMs in creative storytelling using prompt input extracted from multiple modalities.
What's next for Kineografii
(1) Multimodal (video-text) fine tuning with 1000+ story-based long videos by curating high-quality datasets.
(2) Efficient use of Prompt Engineering for coherent and diverse storytelling. Explore “Tree-of-Thoughts” (ToT) for creative writing tasks. [Reference: https://github.com/princeton-nlp/tree-of-thought-llm]
(3) Develop a robust pipeline for media (audio+video) understanding, Ai storytelling, and Visual Q&A.
(4) Generate image sequences (/visual narrative) directly.

Log in or sign up for Devpost to join the conversation.