-
-
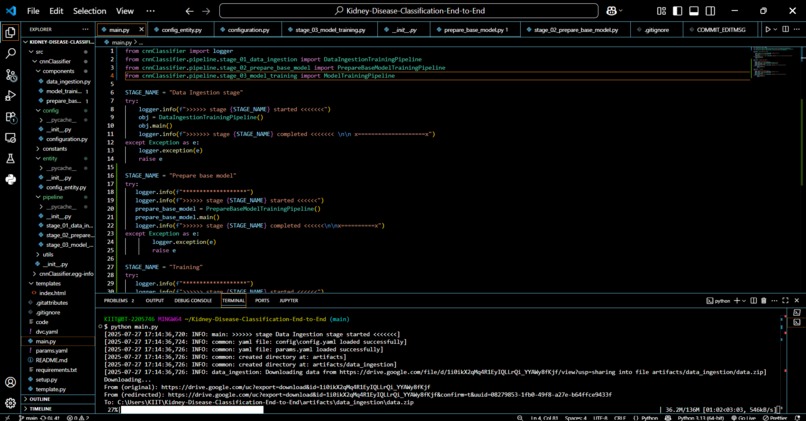
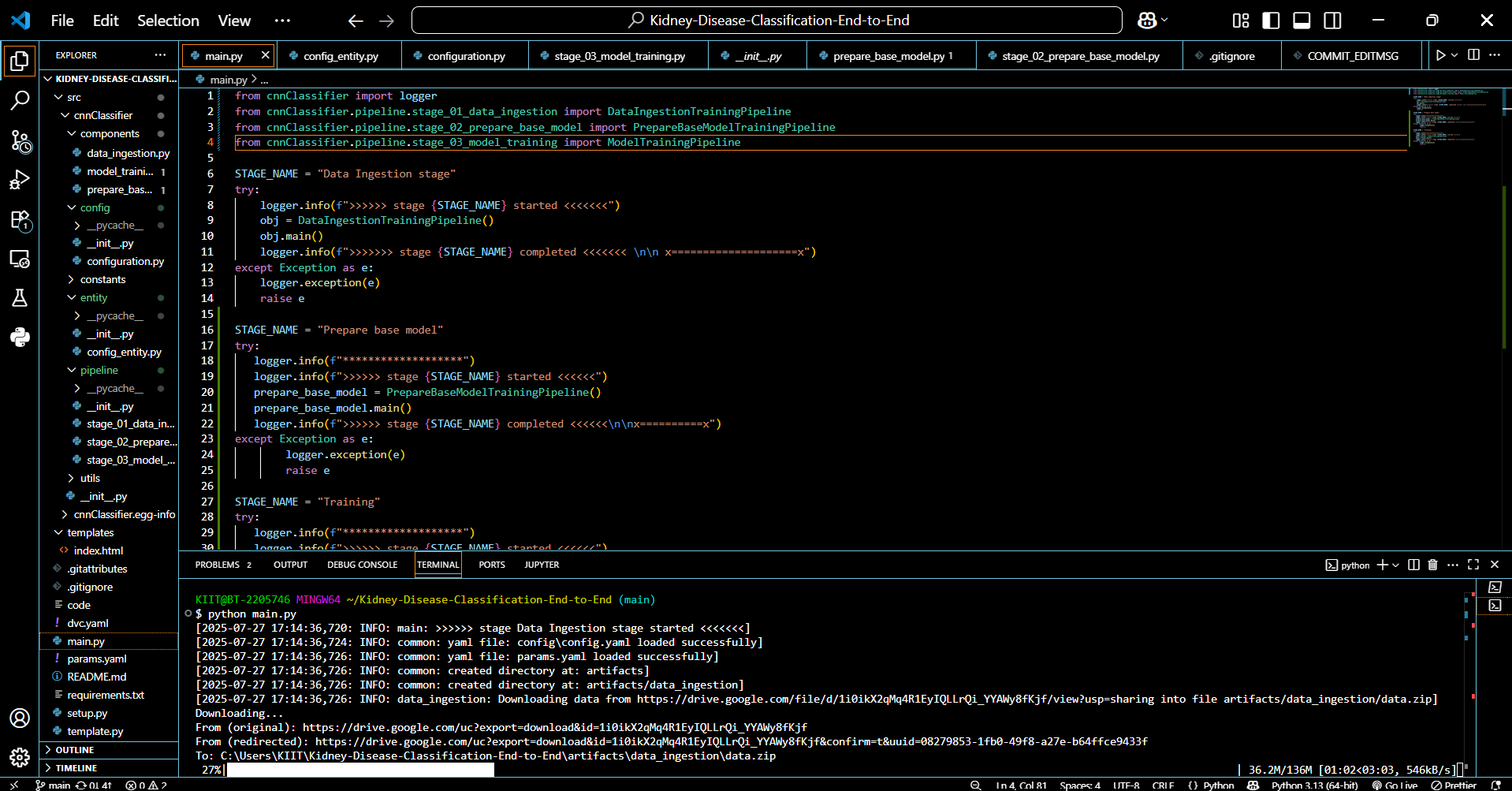
Code_screenshot
Inspiration
I’ve always been curious about how real-world AI products are built—not just the model, but the entire process from data to deployment. Through this hackathon, I wanted to challenge myself to learn end-to-end machine learning deployment. Kidney disease classification felt like a meaningful and impactful application to explore while learning how to make a complete ML project production-ready.
What it does
Our project takes raw kidney disease datasets and processes them through a VGG16-based convolutional neural network to classify whether a patient has chronic kidney disease. The end goal is a full-stack deployable solution that provides quick predictions via a clean UI.
How we built it
We built the project using:
- Python, TensorFlow, and Keras for the deep learning model (VGG16)
- Pandas, NumPy, and Matplotlib for data preprocessing and visualization
- YAML for config-driven modular pipelines
- DVC (planned) for versioning data and models
- Docker/AWS (planned) for final deployment
- GitHub for collaboration and version control
Challenges we ran into
- Encountered versioning issues and large file push errors while using GitHub
- Syntax bugs during early pipeline structuring
- Limited time to implement full Docker/AWS pipeline during the hackathon
- Model training required tuning and cleanup due to dataset imbalance
Accomplishments that we're proud of
- Successfully implemented a modular and scalable ML pipeline
- Clean separation of config, code, and data to allow easy experimentation
- Got the initial VGG16 model working with decent accuracy
- Planned for production-grade deployment using modern tools
What we learned
- How to build modular ML pipelines using OOP, YAML configs, and custom logging
- Basics of DVC and MLOps practices
- Hands-on experience debugging Git large file errors
- Improved our skills in deep learning and project development
What's next for Kidney-Classification-Project
- Integrate DVC for full version tracking of datasets and models
- Build a streamlit/gradio frontend for real-time predictions
- Dockerize the application for smoother deployment
- Deploy the solution using AWS EC2 or S3
- Improve the model using hyperparameter tuning and experimenting with different architectures
Built With
- bash
- dvc
- github
- kaggle
- machine-learning
- mlops
- python
- yaml

Log in or sign up for Devpost to join the conversation.