Inspiration
People today have lots of new ideas for kickstarters, but they can not sure whether the ideas are attractive enough for other organisations to invest them.
What it does
Person 1: Jim, a 27 year old man who is interested in developing his own kickstarter. He currently has an idea for a kickstarter but does not know how well it will go in the current crowdfunding market.
How I built it
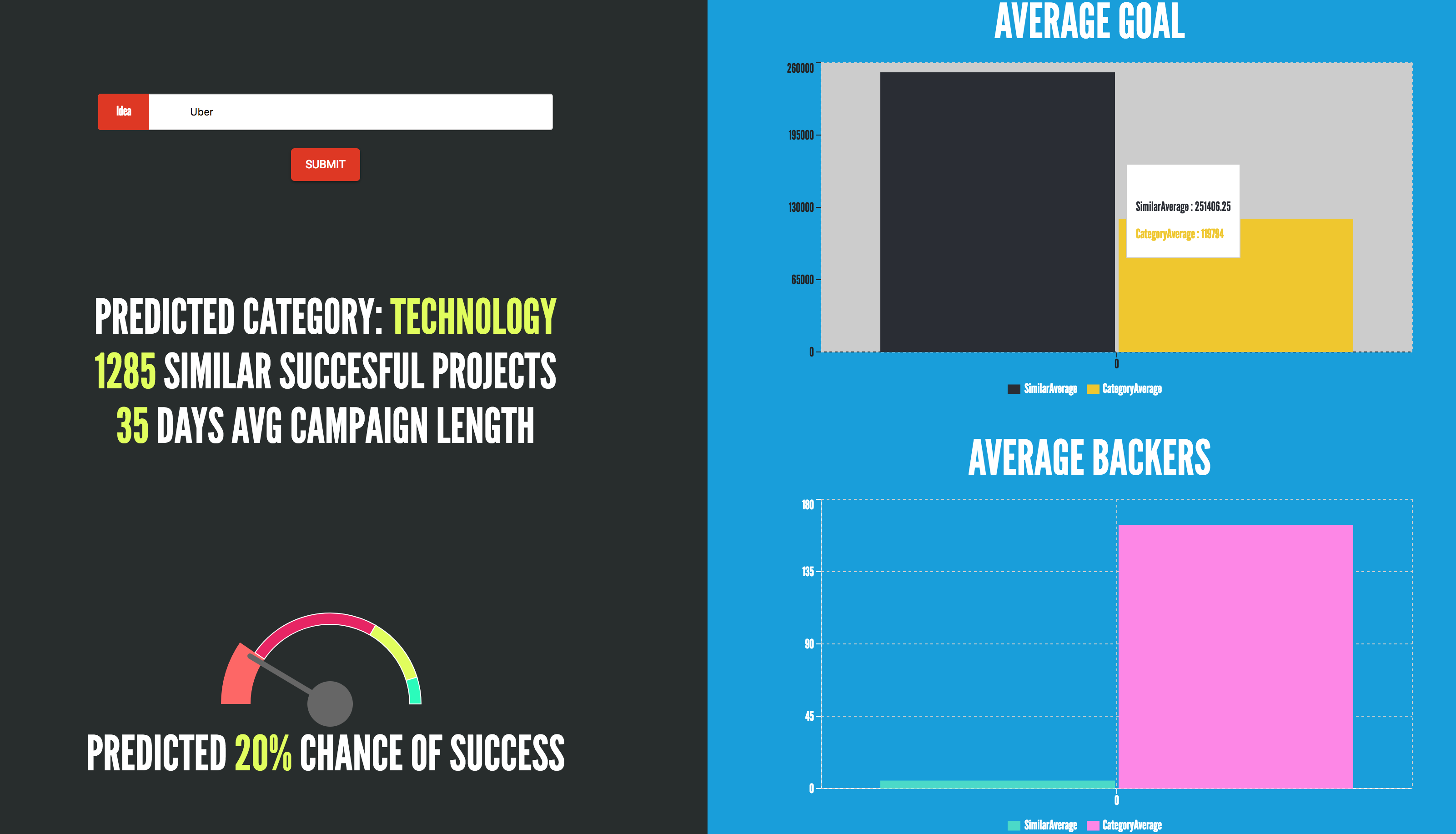
It helps the user to understand the current demand for the crowdfunding market based off previous similar kickstarters with similar name and category. It first analyses the name of the idea provided by the user to find the optimal category. Next it will generate statistics for the user of the optimal category and similar projects. The following information it will provide is the following:
- Optimal category for the idea name
- Number of successful projects
- Average number of campaign length
- Average goal (in Real USD)
- Average number of backers
- Average number of pledges (in Real USD)
How I built it and How it works
Our current stack is React.js at the front-end development and Node.js at the back end development.
From the user's input, we would feed the idea name into a machine learning (Naive Bayes) algorithm that will classifying the optimal category. This category information will be later then be used to generate the industry averages and to be compared to similar projects with similar names in the same category.
Third-party API use
API-Npm use:
- Wink-naive-bayes-text-classifier: back-end machine learning Naive Bayes
- Wink-nlp-utils: back-end machine learning Naive Bayes
- Fs: read csv file in back-end and use the data in the csv file to train the Naive Bayes
- Fast-csv: read csv file in back-end and use the data in the csv file to train the Naive Bayes
- Hashmap: text analysing
- Express: server connection
- Path: server connection
- Body-parser: handle http request once connected to server
- Axios: the library for Ajax
Challenges I ran into
The challenge we ran into was the implementation of the algorithms and machine learning model for calculating the final result since it is very difficult to think of a good algorithm to determine the final state results.
The challenges we had faced was determining a suitable algorithm for the back-end for the web application. Since we had some possibilities of using Multilayer perceptron (MLP) and Naive Bayes based on numerical data. However it did not provide the end results we wanted. We later then converted it into a two step process where the first is to determine the category and the second step is to calculate the averages. Another challenge for our group was how to filter based on text analysis, since it prevented the team from going any further. After thinking about the problem, we settled on tokenization and stemming to find similar elements.
Accomplishments that I'm proud of
As a team we are proud that we have a MVP within the 24 hour time frame of the Hackathon. Since this was our first Hackathon we went in as a team.
What I learned
How to use an API from node.js for web application front-end design and back-end algorithm design.
What's next for KickStarter Idea Predictor
Adding in more features into the machine learning algorithm to make the predictor more refined and accurate to the current market.
Built With
- node.js
- react-js


Log in or sign up for Devpost to join the conversation.