
Inspiration
We were inspired to make this program after seeing many college students having difficulty reading through dense texts because of potentially difficult/important words.
What it does
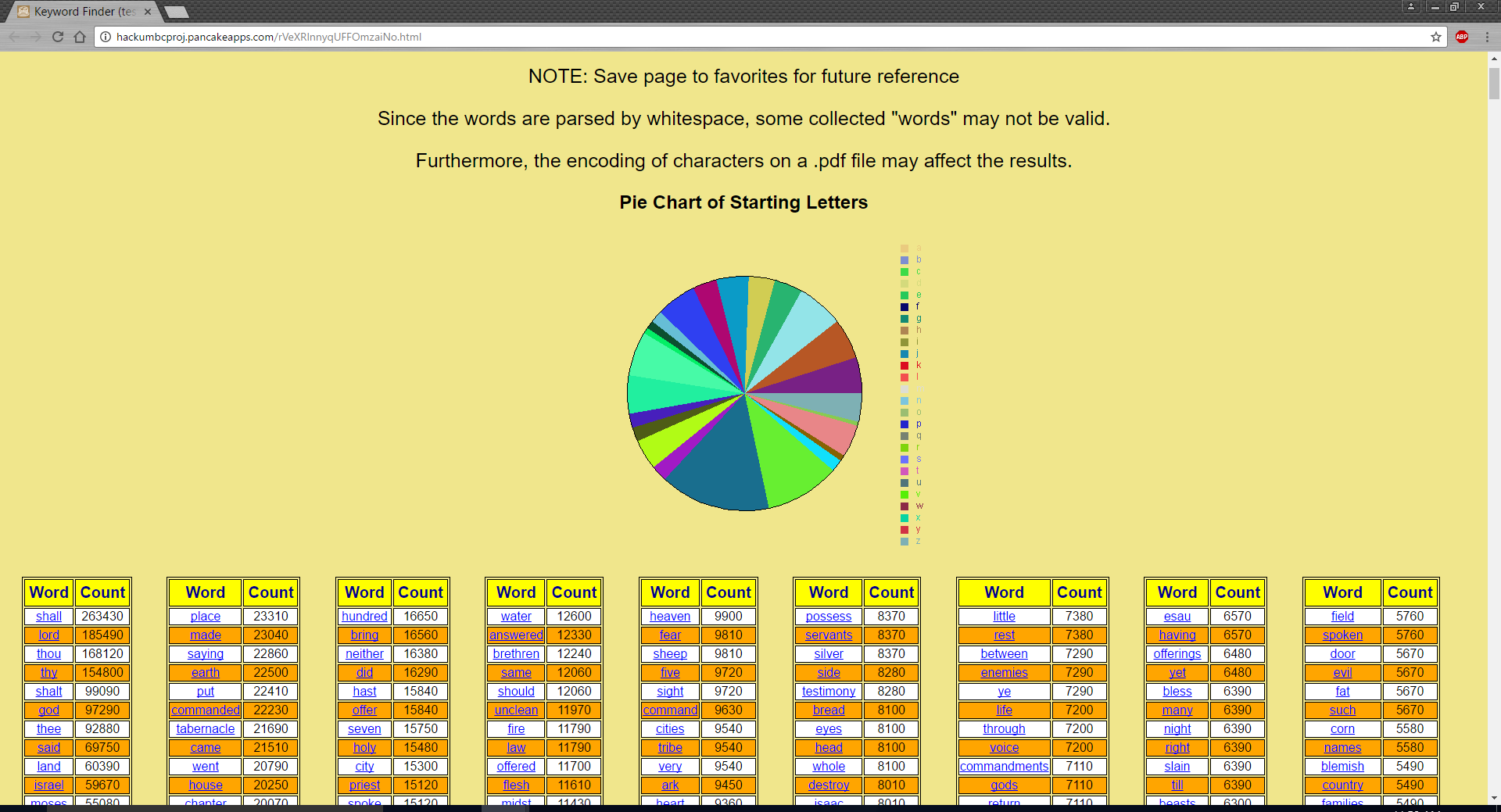
This program take a text document or pdf and sorts all of the different words into a binary search tree. It then displays the words in order of most reoccurring in a table. The purpose of this is to highlight key words in a document that the user might need to pay attention to as it is most likely an important topic in that section of text. However, a large amount of very common, insignificant words such as "and, was, too, etc." have not been included as those are not very helpful in distinguishing important concepts.
How we built it
We used Java to build the GUI to enter the file. We then used the Dropbox API to upload our results to the cloud, where it is then formed as a static website by pancake.io.
Challenges we ran into
We had some difficulty with formatting the tables on the results page. We also had to spend some time with allowing the program to input pdfs.
Accomplishments that we're proud of
We are proud that our program can take the data parsed through the file and produce a pie chart of the relative frequency of starting letters. We are also proud that our program works with pdfs, as originally, it only accepted txt file.
What we learned
We learned how to practically use a binary search tree to sort through large amounts of text. We also learned how to use basic features of the Dropbox API.
What's next for Keyword Finder
We hope to implement this algorithm to potentially make a program that can summarize the input text by locating key words.



Log in or sign up for Devpost to join the conversation.