What inspired it
Every team I've worked on has had that one file. Everything depends on it, and exactly one person actually understands it. While that person is around, nobody notices. The day they go on leave or switch teams, that part of the codebase suddenly has no owner. Changes stall, reviews have no qualified approver, and a small incident turns into a long one.
What always bothered me is that this risk is completely invisible until it hits you. There is no dashboard for it. I looked through the GitLab AI Catalog and it is full of blast radius tools that trace what a code change might break, but they all look at the code. None of them answer the human question: who is the bottleneck, and which critical files does only one person understand? That blind spot is what I built Keystone to fix.
What it does
Keystone scores every file on two things and combines them.
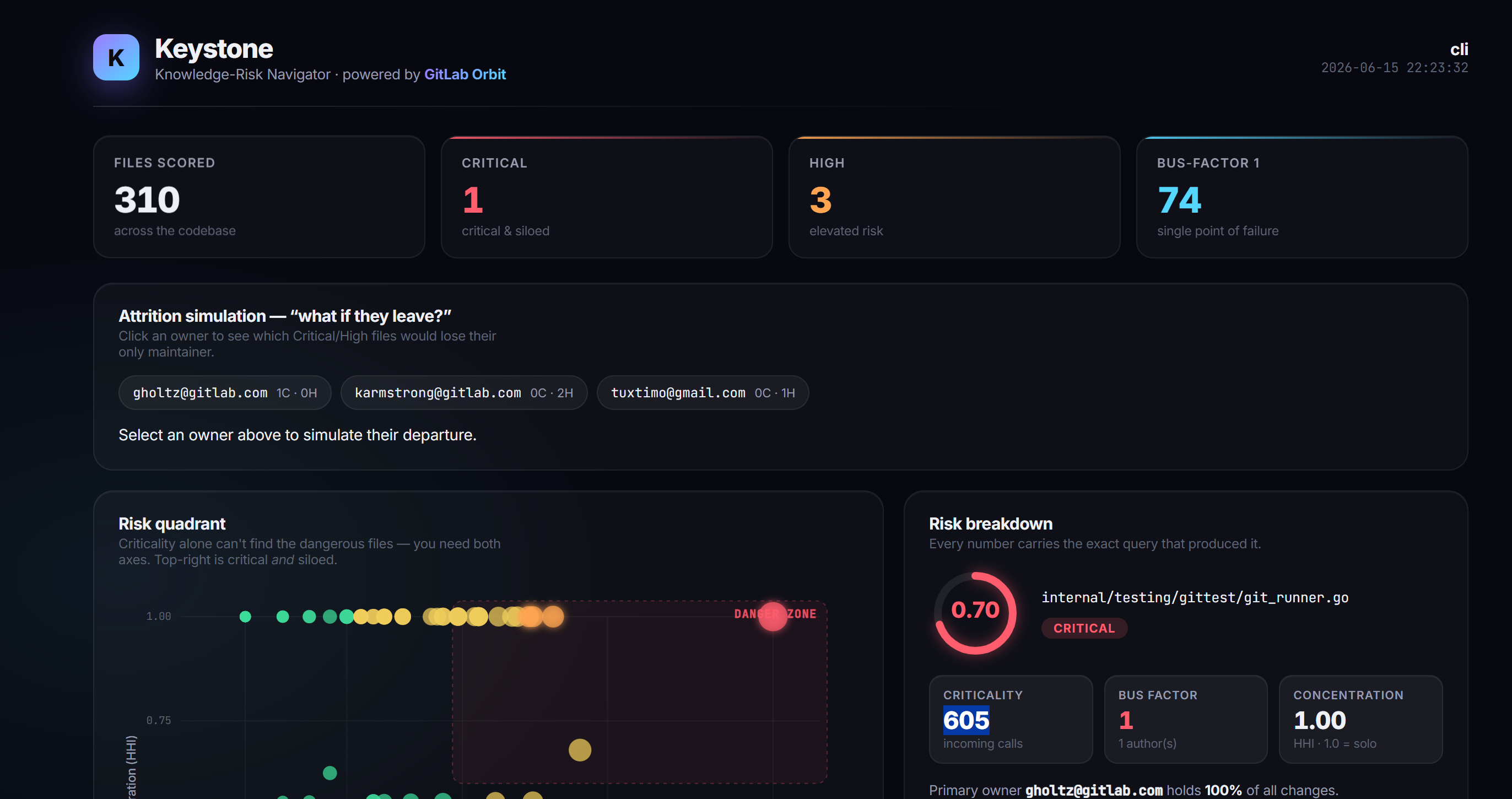
Criticality is how much other code depends on the file, read from the GitLab Orbit code graph. Concentration is how much of the knowledge sits with one person, measured from change history as a bus factor and an HHI score.
The key idea is that you need both. A file everyone depends on is fine if the whole team knows it. A file only one person knows is fine if nothing depends on it. The real risk is the file that is critical and known by a single person, so Keystone multiplies the two scores and only those files rise to the top. A plain "most depended on files" list can never make that distinction.
When you mention Keystone on a GitLab issue, it posts a report in plain English: the riskiest files, who the sole owners are, and concrete steps to spread the knowledge. It then opens real GitLab issues to track each fix, like pairing the owner with a second maintainer or adding a reviewer. It also links to an interactive dashboard that plots the whole codebase. So it does not just find the risk, it acts on it, inside GitLab.
How I built it
The risk model lives in a small, auditable engine. Every number it reports comes with the exact query that produced it, so nothing is a black box.
Criticality comes from GitLab Orbit. I validated it live against the indexed graph (for example, the IO type in factory.go has 223 incoming calls), and it also runs offline using Orbit Local.
The published flow is the part I am most proud of. When you mention it, it reads the analysis and then queries Orbit live at runtime through the Orbit MCP server, confirming the criticality against the real graph before it posts the report and opens the issues.
I also added a security layer that fuses a third Orbit signal. If a file is critical, owned by one person, and has an open vulnerability, Keystone escalates it straight to the top. One owner, load bearing, and exploitable is the first thing anyone should fix, and only Orbit's combined graph lets you see all three facts at once.
Attrition Mode is the feature that makes the idea click. You click a person and the dashboard shows exactly which critical files would lose their only owner if they left. The same capability is exposed as an MCP tool, so I can ask the question from Claude or any IDE, not just the dashboard. Everything is wired together by a Keystone MCP server, so the flow, GitLab Duo chat, and an IDE all talk to the same brain. A scheduled pipeline rebuilds the index and refreshes the dashboard on its own.
How I proved it
I ran Keystone on gitlab-org/cli, the actual GitLab CLI. The top result was internal/testing/gittest/git_runner.go: 605 things depend on it, and one person wrote all of it. A file that is just as depended on, config.go, scored Low because eleven people share it. Criticality on its own would rank those two files the same. Only the combined score tells them apart, which is the entire point.
What I learned
The hardest part was not the scoring, it was trusting it. Early on the engine kept choking on the glab CLI's update banner leaking into its JSON output, so I learned to extract the first valid JSON object and ignore the noise around it. I also learned how much the GitLab Orbit graph can do once you stop thinking of it as just a code map and start joining code, people, and security together. The multiplication idea sounds simple, but getting to it meant throwing out a few versions that just produced longer lists nobody would read.
What's next
An organization wide mode that ranks the people who are single points of failure across a whole group, not just one project. And knowledge transfer plans that hand a new owner the exact merge requests they should read to learn a module.
Built With
- duckdb
- fastmcp
- gitlab
- gitlab-duo-agent-platform
- gitlab-orbit
- glab
- langchain
- mcp
- python

Log in or sign up for Devpost to join the conversation.