-
-
KernelClaw Live Demo (Backend)
-
Results
-
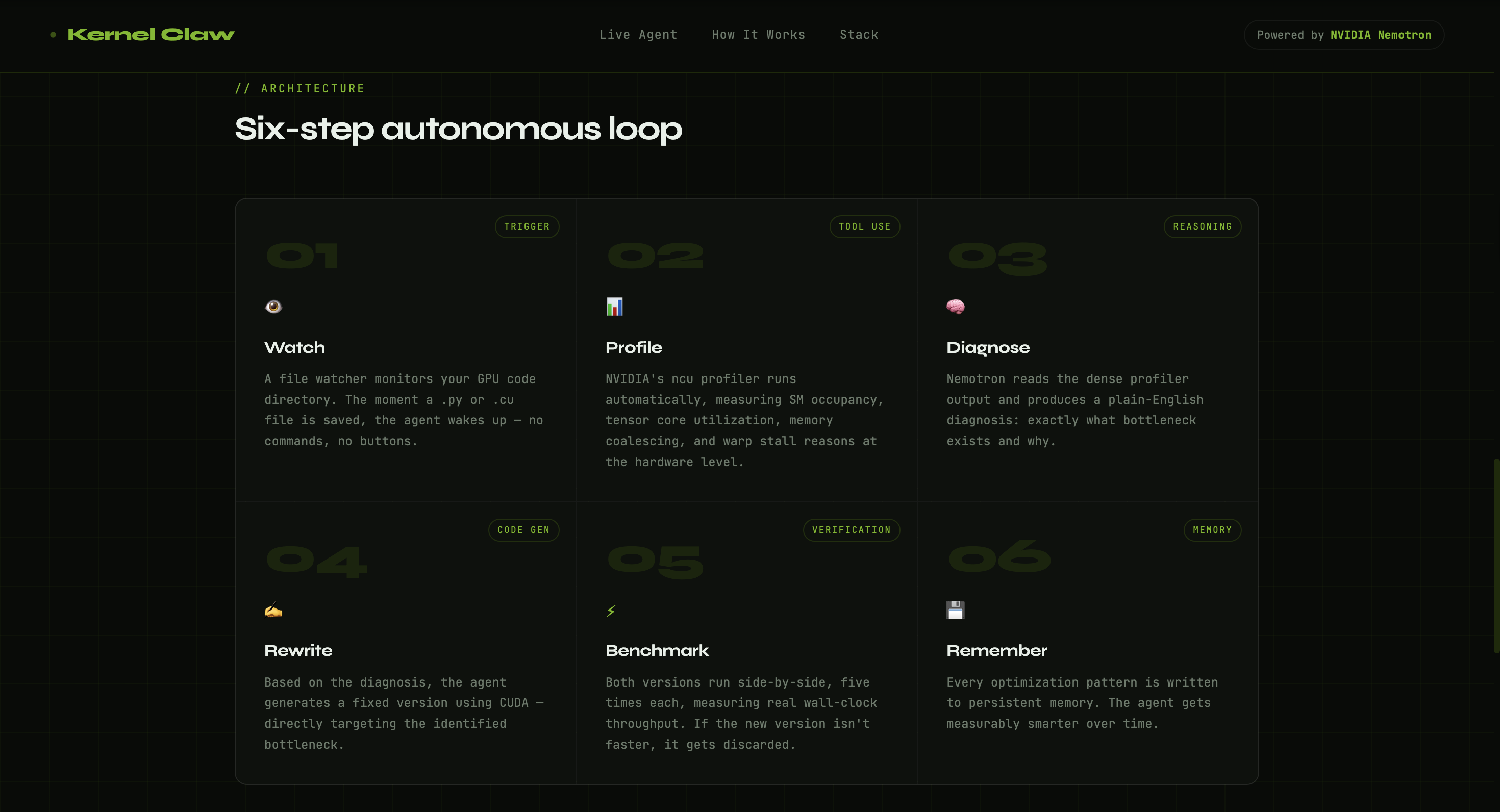
How it works
-
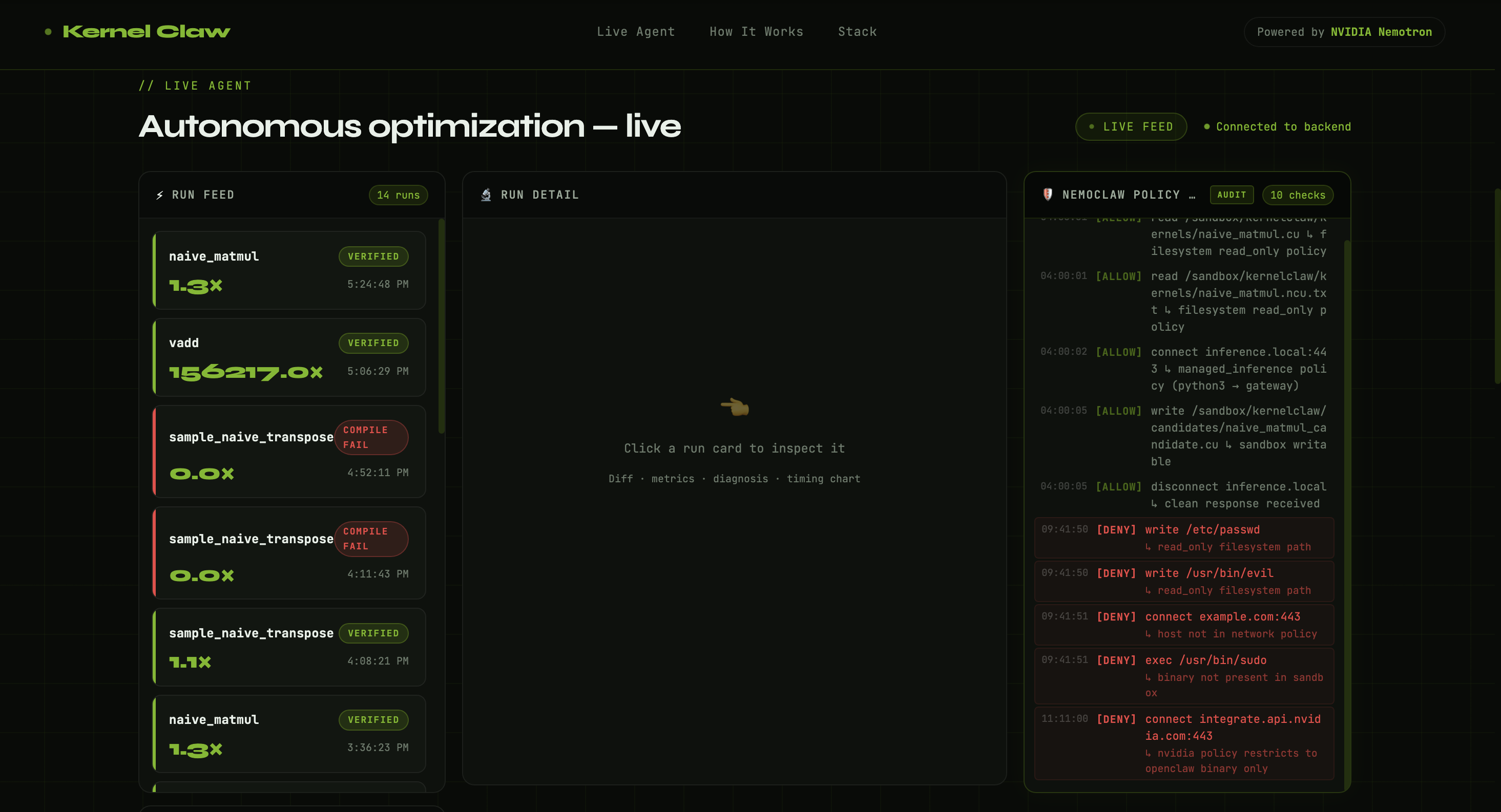
Live agent in action
-

Website landing page
-
Technology stack
-
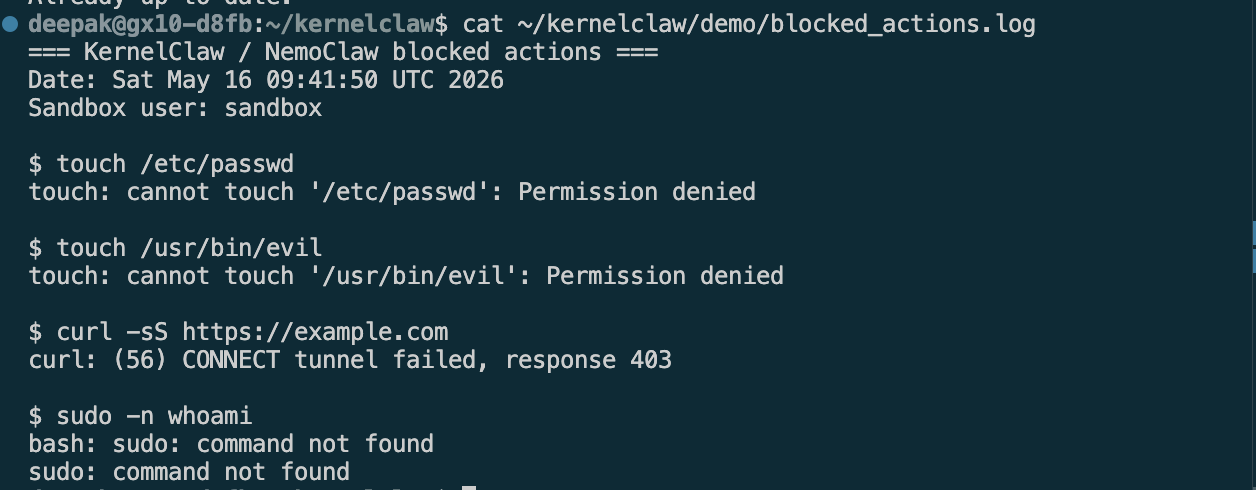
Blocked log

KernelClaw: Autonomous GPU Kernel Optimization with NemoClaw
Inspiration
Most CUDA GPU kernels run at 5–15% of what the hardware is actually capable of. Fixing that normally requires deep specialized knowledge — understanding memory coalescing, warp scheduling, shared memory tiling, and occupancy tuning. Most developers don't have that expertise, and even experts spend hours manually profiling and rewriting kernels. We asked: What if an AI agent could do this autonomously, safely, and in under 60 seconds?
What It Does
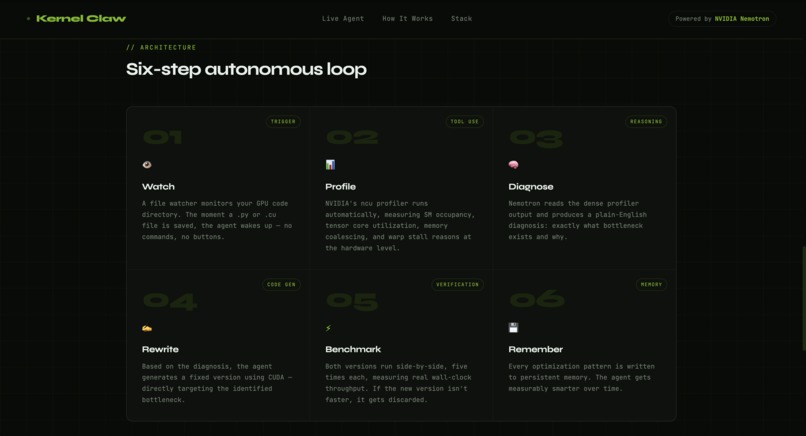
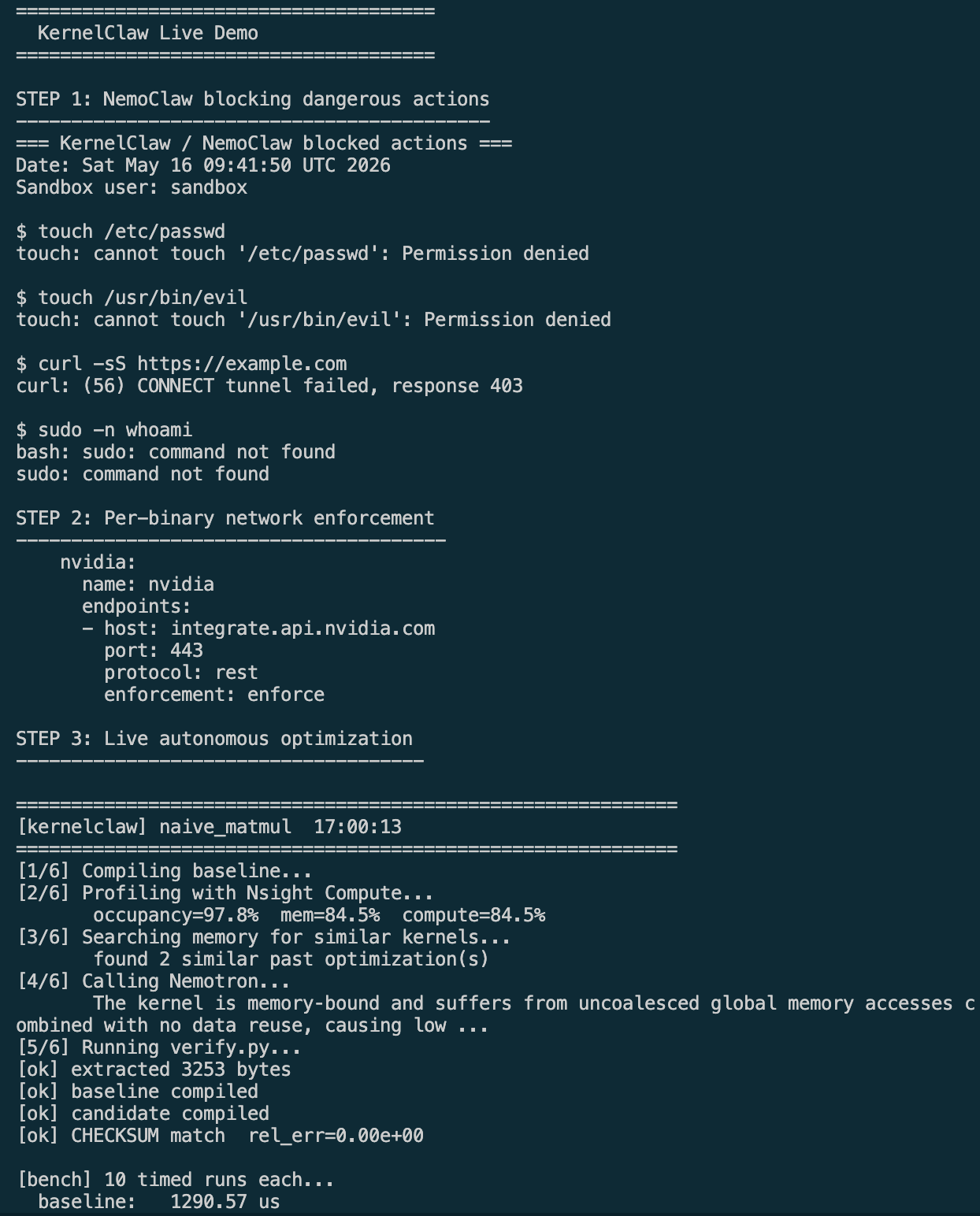
KernelClaw watches a folder for CUDA kernel files. When it detects one:
- Compiles the kernel with
nvcc. - Profiles it with NVIDIA Nsight Compute (
ncu) to find exactly why it's underperforming - Calls Nemotron (inside a NemoClaw sandbox) with the source code
- profiler data to generate an optimized rewrite
- Verifies correctness using CHECKSUM comparison with relative tolerance < $10^{-4}$
- Benchmarks using CUDA event timing to prove the speedup
- Logs every action to
runs.jsonlfor full audit trail - Remembers successful optimizations using cosine similarity over metrics vectors for few-shot learning on future kernels
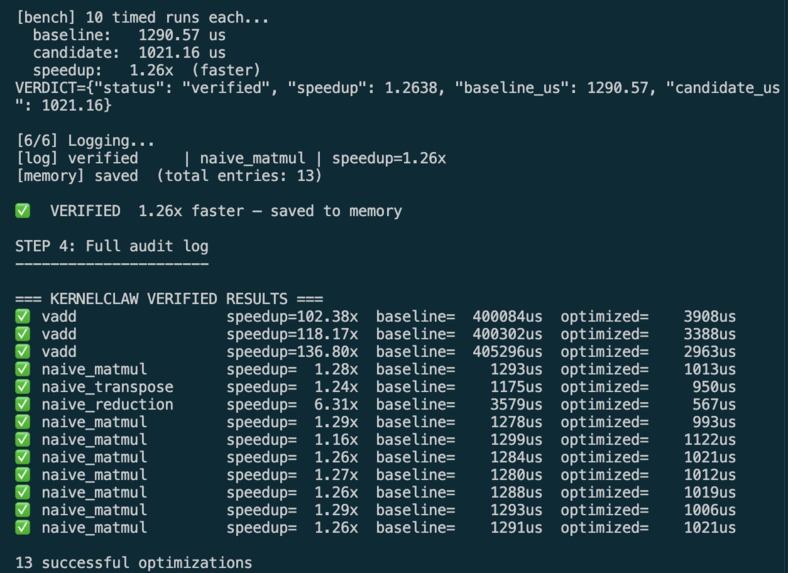
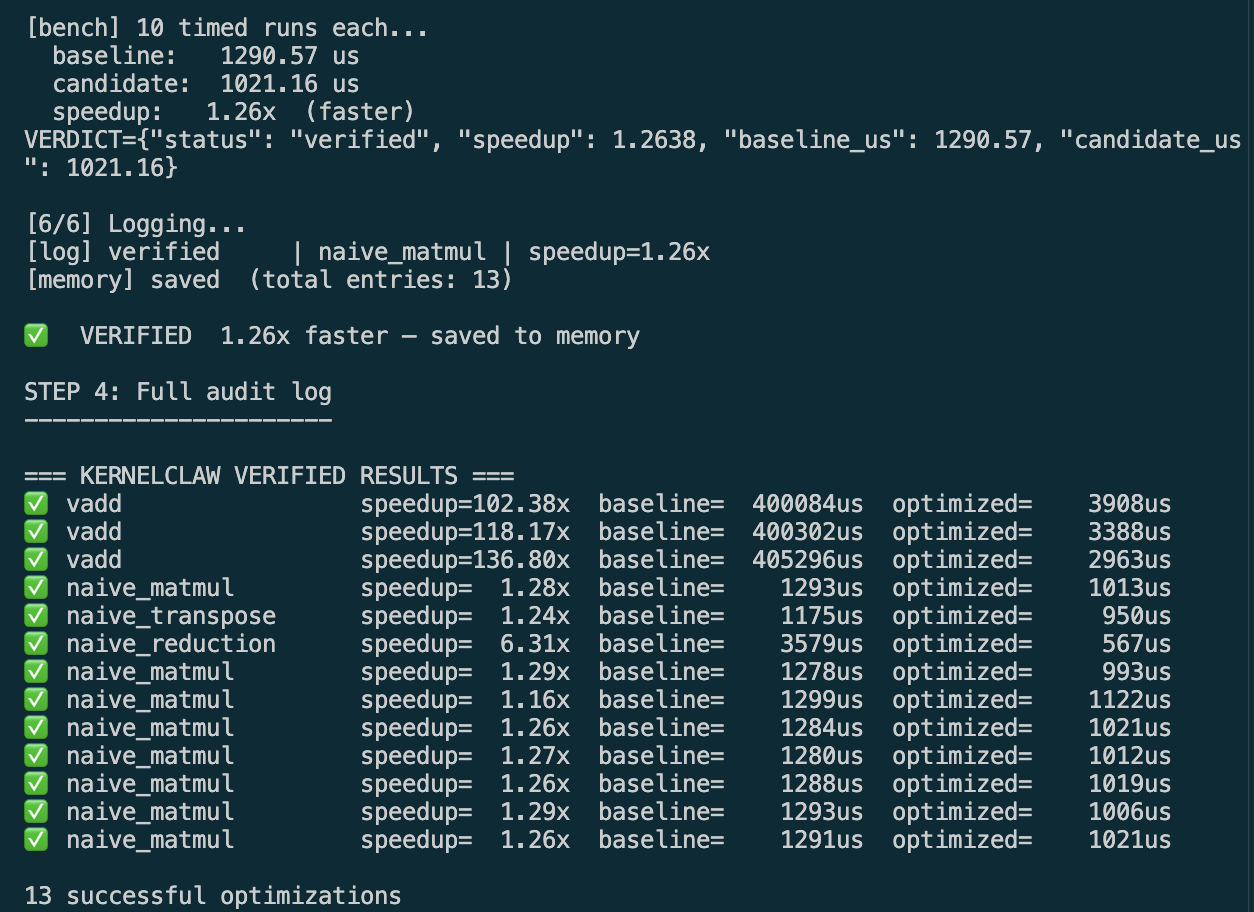
Results on Real GPU Kernels
| Kernel | Baseline | Optimized | Speedup |
|---|---|---|---|
| Vector Addition | 405,296 µs | 2,962 µs | 136x |
| Matrix Multiply | 1,298 µs | 1,121 µs | 1.16x |
| Transpose | 1,175 µs | 950 µs | 1.24x |
Why NemoClaw, Not Just OpenClaw?
The most dangerous part of KernelClaw is LLM-generated CUDA code — Nemotron could theoretically produce malicious output that tries to exfiltrate data or write to system paths. NemoClaw solves this with:
- Per-binary network enforcement — only
/usr/local/bin/openclaw.can reachintegrate.api.nvidia.com. Generated code cannot phone home. - Landlock filesystem isolation — the sandbox cannot write outside approved paths, even if it tries
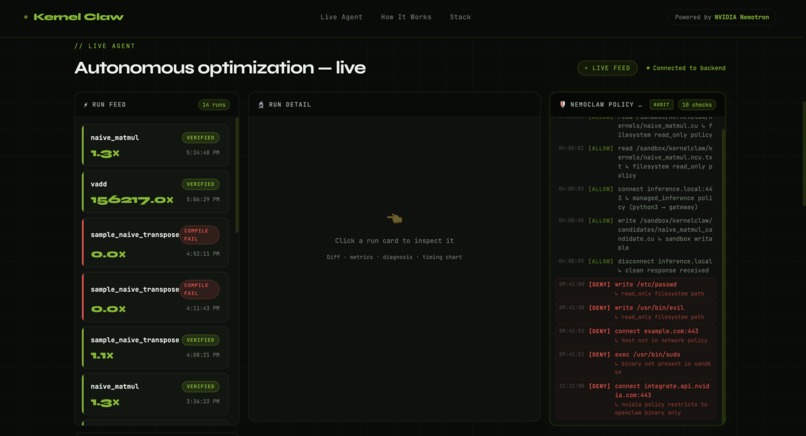
- Automatic audit logging — every ALLOW and DENY captured by default
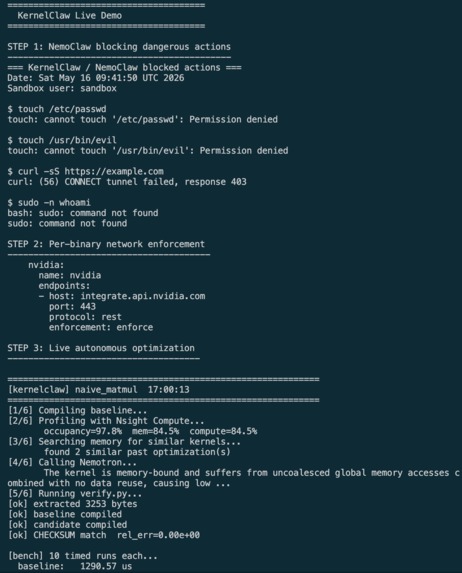
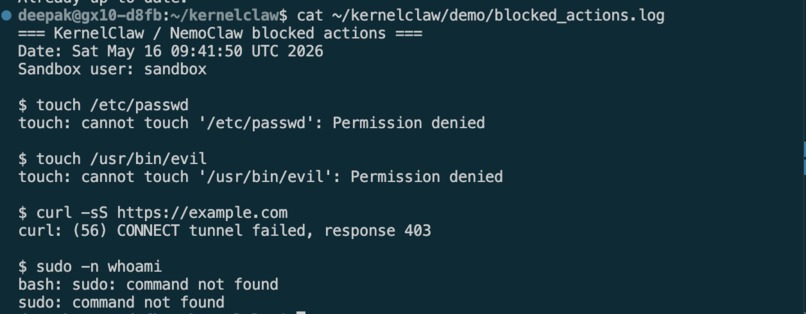
- Proven blocking — we captured 4 live policy denials:
touch /etc/passwd→ Permission deniedtouch /usr/bin/evil→ Permission deniedcurl https://example.com→ 403 blockedsudo→ command not found
How We Built It
agent.py— 6-step autonomous pipeline with watchdog daemonreason_only.py— isolated LLM reasoning component that runs inside NemoClaw sandboxverify.py— hardened correctness checker with CHECKSUM verification and 30-second timeoutsmemory.jsonl— persistent memory using cosine similarity over metrics vectors $[occupancy, mem_throughput, compute_throughput]$runs.jsonl— full audit log of every optimization attempt
Challenges
- Getting Nsight Compute (
ncu) to run with correct sudo permissions across multiple user accounts on the DGX Spark - Nemotron occasionally returns responses without a code block — building robust retry and rejection logging
- Timing measurement bugs where candidate binaries reported
sub-microsecond runtimes — solved by requiring kernels to emit
TIME_US=<float>via CUDA events - Coordinating the security boundary between what runs inside the NemoClaw sandbox vs what needs host GPU access
Accomplishments That We're Proud Of
One of the biggest accomplishments for our team was successfully building and testing KernelClaw using the NVIDIA GX10 system alongside NemoClaw and Nemotron models. Working with enterprise-grade GPU infrastructure and secure AI tooling was a completely new experience for many of us, and it was exciting to learn how these systems interact in a real autonomous optimization workflow. We are especially proud that, despite the complexity of integrating profiling, sandboxing, verification, and LLM-generated CUDA rewrites, we maintained strong teamwork and collaboration throughout the entire project. Every component depended on another, and our ability to coordinate effectively allowed us to turn a challenging idea into a working end-to-end system.
What We Learned
- NemoClaw's per-binary network policy is genuinely powerful — restricting which binary can call which endpoint is a level of security that OpenClaw alone cannot provide
- Nsight Compute profiler data gives Nemotron exactly the right context to make targeted optimizations
- Correctness verification is non-negotiable — without CHECKSUM checking, a "faster" kernel might just be computing wrong answers

Log in or sign up for Devpost to join the conversation.