



Keel — Ctrl+Z for production data
The governed control plane for production data changes. Describe a fix in plain English, preview the exact diff, get it approved, apply it safely under live traffic, and undo it — all on an immutable, tamper-evident audit trail. Built on Amazon Aurora PostgreSQL and Vercel.
Inspiration
Every company with customers has engineers who, a few times a week, have to make a change to production data that the application was never built to handle. A botched deploy wrote the wrong status to 50,000 rows. A customer requests a GDPR deletion. Finance found a data-entry error the day before an audit. A B2B customer negotiated a bespoke pricing tier that doesn't fit the standard plan model. None of these has a button in any admin panel — because if they were routine and anticipated, someone would have built a feature for them.
So they get done the dangerous way: an engineer gets a Slack message, opens a SQL console pointed at production, hand-writes an UPDATE, and runs it. No preview. No "this will affect 2 million rows — are you sure?" No undo. No record of who changed what, or why. One missing WHERE clause and you've rewritten the entire table. GitLab's 2017 outage — an engineer running a command against the wrong production database and deleting live data — is the canonical version of this nightmare, but a smaller one happens quietly at every company that touches customer data.
We kept circling one gap. AWS already has a service for governing infrastructure changes — Systems Manager Change Manager — with approvals, audit, and rollback for operational runbooks. But the single riskiest change in any company, a human directly mutating production data, has no equivalent guardrail. The relational engine hands you the raw primitives (transactions, snapshots), and then leaves you on your own. Keel is the missing service that sits in that gap: Change Manager, but for the data inside your database.
What it does
Keel turns a terrifying, ungoverned operation into a safe, reviewable, reversible one. The full loop:
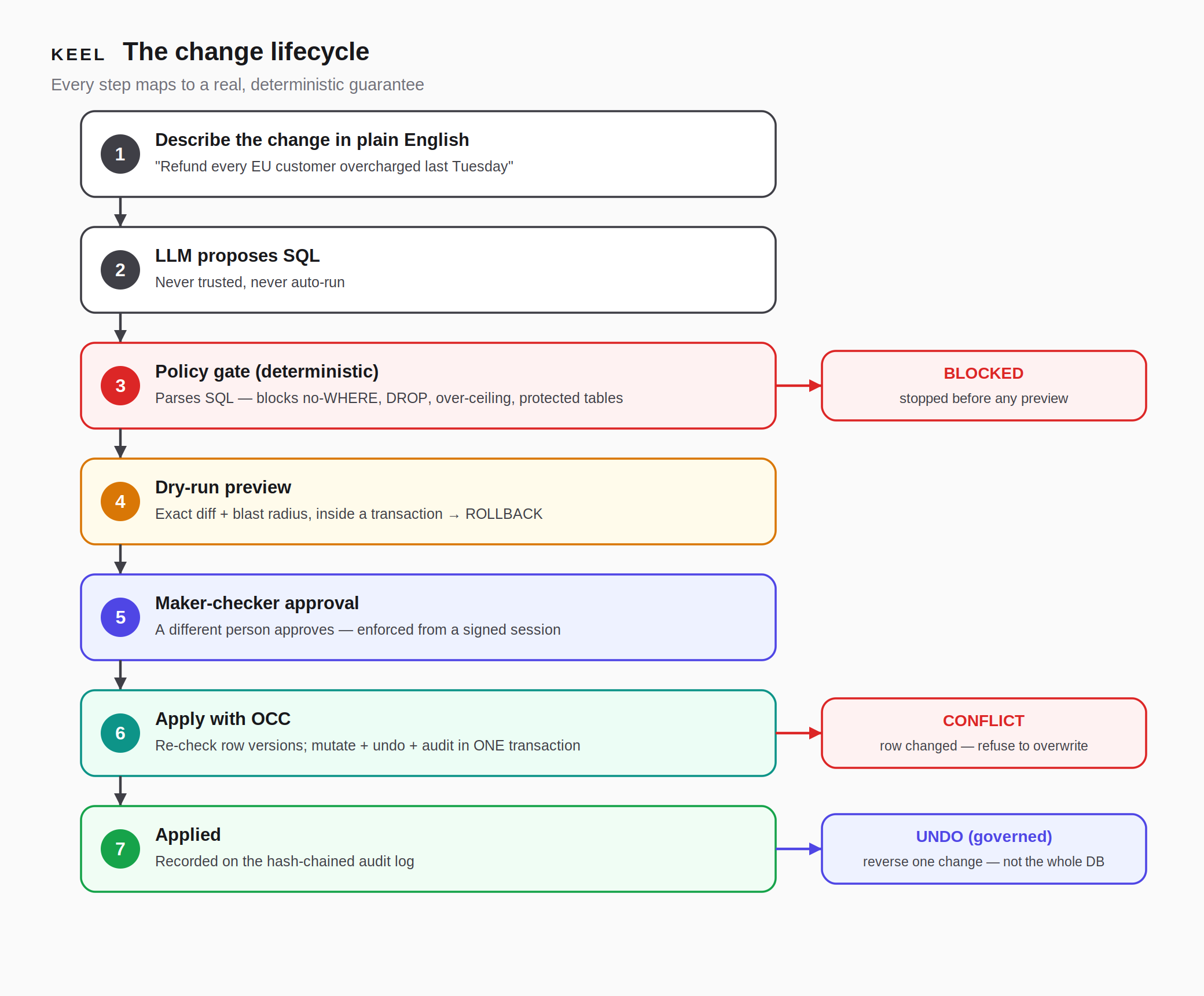
- Describe the change in plain English. "Refund every EU customer overcharged last Tuesday." An LLM proposes the SQL — but it is never trusted and never auto-run.
- A deterministic policy gate inspects the SQL before anything touches the database. It parses the statement and hard-blocks the catastrophic ones: a
DELETE/UPDATEwith noWHERE, anyDROP/TRUNCATE/DDL, a change estimated to exceed the configured row ceiling, or any write to a protected table (audit_log,change_request, etc.). The model proposes; the gate disposes. - A dry-run preview shows the exact diff — every affected row, before and after — by running the change inside a transaction and rolling it back. Nothing commits. A prominent blast-radius badge ("affects N rows") is computed from the query planner without locking or scanning the table.
- A second person approves it. Maker-checker segregation of duties: the person who drafted a change cannot be the one who approves it — enforced server-side from a signed session, not a checkbox in the UI.
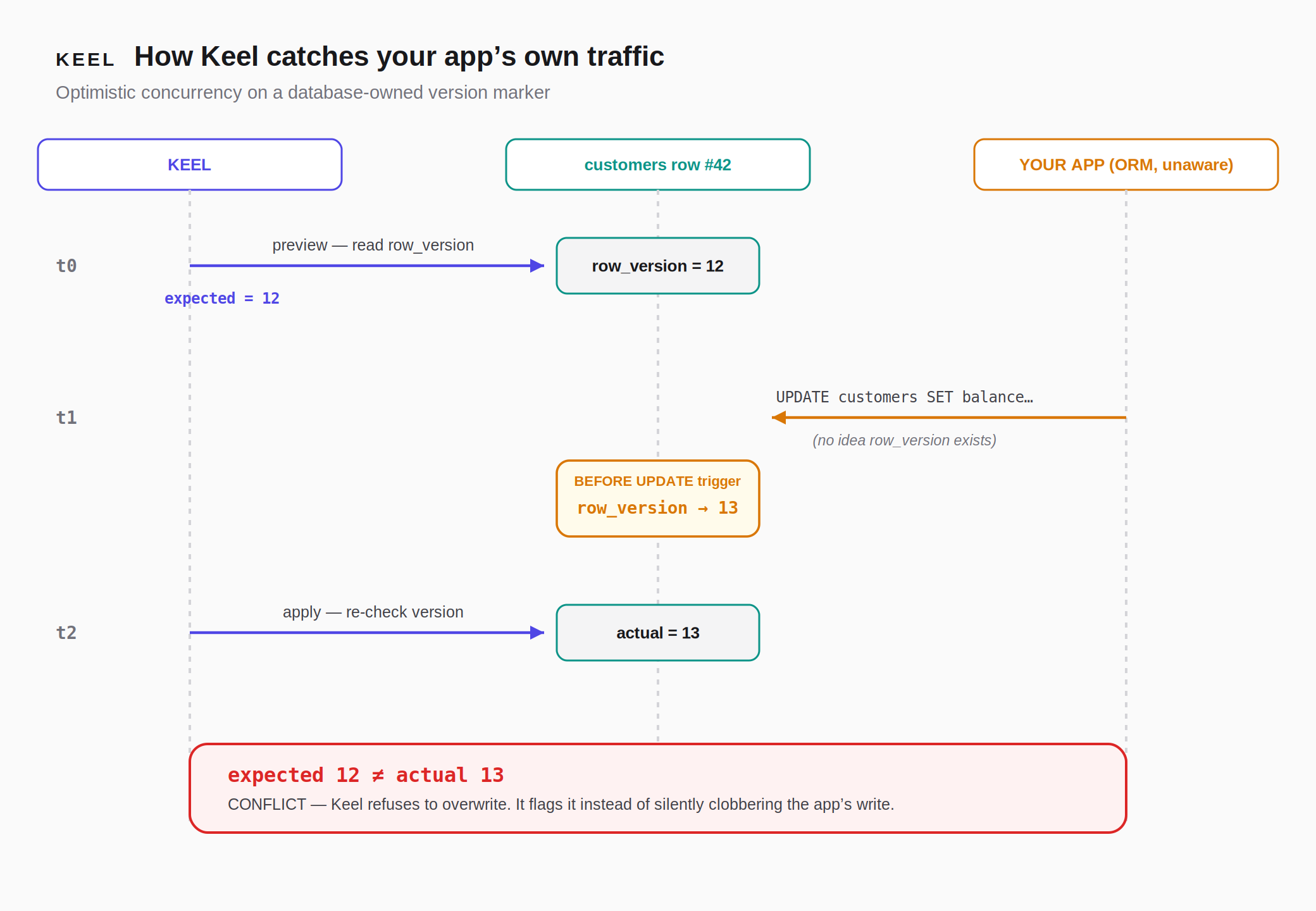
- Apply, safely, under live traffic. At apply time, Keel re-checks that the target rows haven't changed since the preview (optimistic concurrency control). If the customer's own application traffic modified one of those rows in the meantime, Keel detects it and refuses to overwrite — flagging a conflict instead of silently clobbering. The data change, an undo record, and an audit entry all commit in one atomic transaction.
- Undo any applied change — the real Ctrl+Z. A trigger-captured before-image log lets Keel reverse one specific change while leaving every other change since then untouched (unlike a database snapshot, which would roll back everything).
- Prove nothing was tampered with. Every action is recorded in a hash-chained, append-only audit log that commits to the content of each change (a hash of the SQL plus a digest of the before-images), so altering any record after the fact breaks the chain — and Keel reports exactly where.
The result does the one thing an LLM fundamentally cannot: provide a deterministic guarantee, not just careful-sounding output. You can't prompt your way to atomicity, conflict detection, or a tamper-evident trail.
What Keel is — and isn't
| Keel is | Keel is not |
|---|---|
| Per-change undo of production data | Snapshot / PITR (whole-database time-travel) |
| Governed, reviewable, reversible SQL changes | "Git for data" / branching (that's Dolt) |
| The data-plane peer to AWS Systems Manager Change Manager | Infrastructure change management |
| Governance for relational / ACID databases | NoSQL governance (ACID can't be added above a non-ACID engine) |
| A deterministic safety engine that an LLM feeds into | An LLM that writes-and-runs SQL |
This build demonstrates the full governed loop on a single Amazon Aurora PostgreSQL database, governing a representative
customerstable (120k rows). The engine is table- and database-agnostic by design — see What's next.
How we built it
The stack
- Frontend: Next.js (App Router) + TypeScript + Tailwind, scaffolded and designed with Vercel v0, deployed on Vercel — a marketing landing page plus a four-screen console (compose, review queue, history, audit timeline).
- Database: Amazon Aurora PostgreSQL Serverless v2 — the relational/ACID core that makes every guarantee possible.
- NL layer: OpenAI (primary) with Google Gemini (automatic fallback), behind a swappable provider interface.
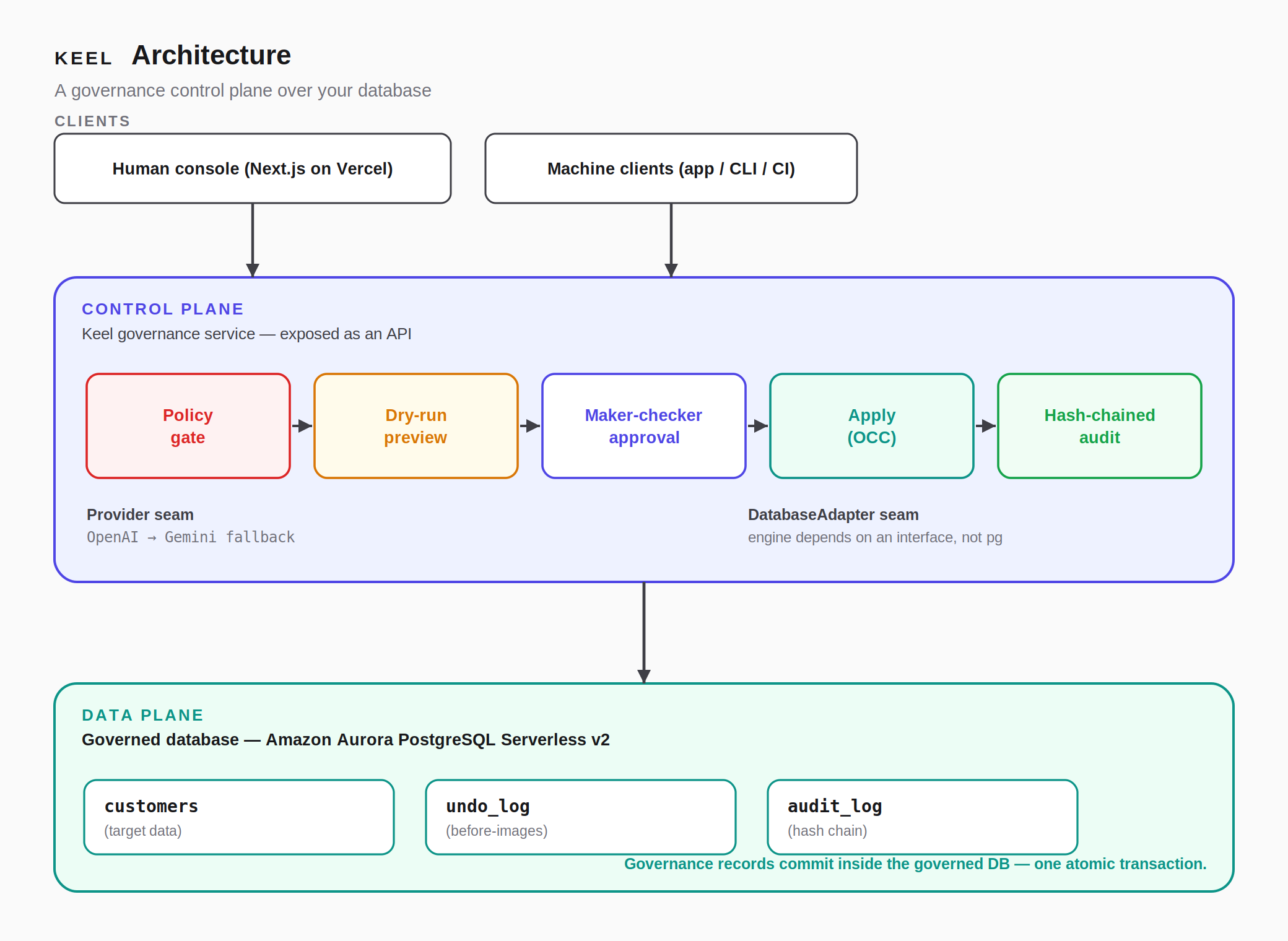
The architecture is a control plane over a data plane. The control plane is Keel's governance pipeline — policy gate → preview → approval → conflict-safe apply → audit. The data plane is Aurora Postgres: the target tables plus Keel's undo_log and audit_log. Critically, the governance records commit inside the governed database, in the same transaction as the change — a deliberate choice (see Challenges).
We built the engine first, in isolation, before any UI or LLM existed. The four core operations — preview, blastRadius, apply (with OCC), and reverse — are a pure module with no UI or LLM imports. The single most important test in the repo fires a real concurrent writer on a separate database connection and proves the apply step catches the conflict and refuses to overwrite.
Engineering decisions that carry the guarantees:
- The OCC marker is owned by the database, not the application. A
BEFORE UPDATEtrigger bumps arow_versionon every write from any writer — so Keel detects the customer application's own traffic, not just its own changes. (xmin, Postgres's system column, is the zero-schema alternative.) - The policy gate is an invariant, not a step. It runs at preview and re-runs at the execute chokepoint, so even a direct API call can't skip it. A parser-level single-statement assertion blocks stacked SQL (
SELECT 1; DROP ...). - The audit chain is concurrency-safe and content-committing. A transaction-scoped advisory lock serializes appends so two concurrent changes can't fork the chain, and the hashed payload includes the SQL and before-images so tampering is detectable.
- Identity is real. Maker-checker is derived from an HMAC-signed session — a caller can't approve as someone else by passing a string.
- The engine is database-agnostic by design. It depends on a
DatabaseAdapterinterface, not the Postgres driver directly. Aurora Postgres is simply the first adapter.
We hardened the system against three rounds of end-to-end audits, growing the test suite to 17 green suites covering the conflict path, governed reversal, the execution race, content-tampering detection, the policy chokepoint, and protected-table enforcement.
Challenges we ran into
Getting Aurora reachable. The first wall was pure AWS networking: an inbound security-group rule landed on the wrong security group, the target database didn't exist on the cluster, and Aurora's TLS handshake rejected the default sslmode=require against its CA. None of it was code; all of it was the kind of environment friction that eats hours.
The keystone realization — our concurrency check was blind to the exact traffic we claimed to protect against. Early on, row_version was only ever bumped by Keel itself. Our conflict test passed — but only because the simulated writer cooperated by bumping the column. A real application writing UPDATE customers SET ... knows nothing about our column, so the check would have passed blind against the customer's own traffic — which is the entire thesis of the product. Moving version maintenance into a database trigger so any writer bumps it turned the central demo from "Keel vs. Keel" into "Keel vs. your live application" — the version that actually proves the claim.
The dual-write trap, hit repeatedly. Every time we considered putting the audit log in a separate store — a second database, a queue, a managed ledger — we hit the same wall: the change and its audit would no longer be atomic, and a crash between them would leave a change with no record, or a record for a change that rolled back. For a tool whose entire value is a provable trail, that's fatal. The resolution shaped the architecture: governance records must commit inside the governed database.
The NoSQL boundary. We seriously explored extending Keel's guarantees to NoSQL, and had to accept a hard computer-science limit: you cannot manufacture ACID atomicity above a database that deliberately traded it away for scale. Atomicity is a property of the storage engine, not something an external layer can add. So Keel governs relational databases by design — and naming that boundary precisely proved more credible than pretending to cover everything.
Closing the gaps an expert would find. Through the audits we found and fixed a series of subtle holes — the gate ran at preview but not at the apply chokepoint (bypassable); the audit chain could fork under concurrency; maker-checker identity came from caller input rather than a session; the audit hashed the fact of a change but not its content; a double-clicked apply could throw on an illegal state transition. Each fix shipped with a test that proves it.
Accomplishments that we're proud of
- It survives "lift the hood" scrutiny. The hard parts — optimistic concurrency that catches external traffic, atomic apply-with-undo-and-audit, a tamper-evident hash chain, server-enforced segregation of duties — are real and provable, not vapor. 17 test suites back them, including a conflict test that uses a genuine second database connection and an unaware, ORM-style writer.
- A deterministic guarantee over a probabilistic model. The defining design choice: the LLM proposes, but a deterministic policy gate, an MVCC dry-run, and an OCC apply provide the actual safety. We can show the LLM hallucinating a table that doesn't exist and the gate blocking it before anything runs — the clearest possible proof that this is a database system, not a prompt wrapper.
- Per-change undo, not whole-database time-travel. Snapshots and PITR roll back everything; Keel reverses one specific change and leaves the rest. Building the before-image undo log to deliver that distinction is the heart of "Ctrl+Z for production data."
- An honest, defensible architecture. The control-plane-plus-locally-atomic-records design is more correct than the naive "central log" version — and we can explain exactly why the records live where they do.
What we learned
- You can't add ACID from the outside. Atomicity, isolation, and durability are storage-engine properties — this is why Keel is relational by design and why the dual-write trap kept reappearing.
- Concurrency tokens must be owned by the database. An application-maintained version column is blind to other writers; a trigger (or
xmin) is universal. This one distinction is the difference between a conflict check that works and one that only appears to. - Depth beats breadth. We repeatedly resisted scope creep — a second database, a BI tool, OS-level locking, git-style branching — because one mechanism done rigorously is worth more than five done shallowly, especially under expert review.
- Name the limit. Stating exactly where a guarantee stops (relational only; tamper-evident under the app's own role, not tamper-proof without append-only permissions) builds more trust than overclaiming.
- Snapshots are not undo. Whole-database time-travel and per-change reversal are categorically different operations, and the per-change one is what teams actually need day to day.
What's next for Keel — Ctrl+Z for production data
Keel is built as the single-database, single-target case of a deliberately broader architecture. The path to production:
- Any table, no migration. Replace the demo's single-table binding with
information_schemaintrospection so Keel governs arbitrary tables (customers,orders, anything) — usingxminto avoid even adding a column. - Multi-database, self-hosted. Keel is designed to run inside your environment — install it next to your infrastructure and point it at your databases, the way teams self-host Jenkins for CI. The control plane (policies, approvals, the registry of governed databases) is centralized; the undo and audit records stay local to each governed database, preserving the atomic guarantee per target. The existing
DatabaseAdapterseam extends to Aurora MySQL and RDS. - Cascade-aware blast radius. Beyond row counts, surface what a DBA actually fears — lock impact, table rewrites, and foreign-key cascades ("this delete cascades to 47 child orders across 3 tables") — a capability only a relational engine can provide.
- Stronger tamper-proofing. Append-only database roles plus external anchoring of the chain head, moving from tamper-evident to tamper-proof.
- The changeset model. Evolve from "review the SQL, re-run the SQL" to "review a concrete changeset, replay exactly that" — making apply exactly what was reviewed literally true and unlocking atomic multi-table changes.
- Real identity and enterprise readiness. Swap the signed-session stub for a real IdP (SSO/SCIM) with role-based scoping of who can change which tables.
The business. Keel fits any company whose engineers make production data changes — which is to say, every company with customers. It ships self-hosted (commercial license) or as a managed cloud tier, and the budget line is one every regulated company already has: compliance (SOC 2 and SOX both want exactly this — segregation of duties, an immutable audit trail, reversibility) and incident prevention. The cost of a single fat-fingered production UPDATE is the entire pitch.
Built With
- amazon-aurora-postgresql-serverless-v2
- gemini
- next.js
- openai-api
- tailwind-css
- typescript
- v0.app
- vercel


Log in or sign up for Devpost to join the conversation.