-
-
BluePrint
Inspiration
Modern AI coding tools are powerful, but they often fail at the most critical early stage, turning a vague idea into a complete, implementation-ready plan. We repeatedly observed a pattern: users submit a single prompt, receive partial output and then spend significant time manually requesting missing features, clarifications, and architectural fixes.
This “prompt → patch → reprompt” loop creates friction, inefficiency, and inconsistent system design.
We were inspired to build a system that behaves more like an experienced technical consultant: one that asks the right questions up front, adapts to the user’s expertise level and produces a structured Technical Design Document (TDD) that is actually ready to build from.
Our goal was simple but ambitious: Reduce ambiguity → Increase architectural completeness → Accelerate build time
What it does
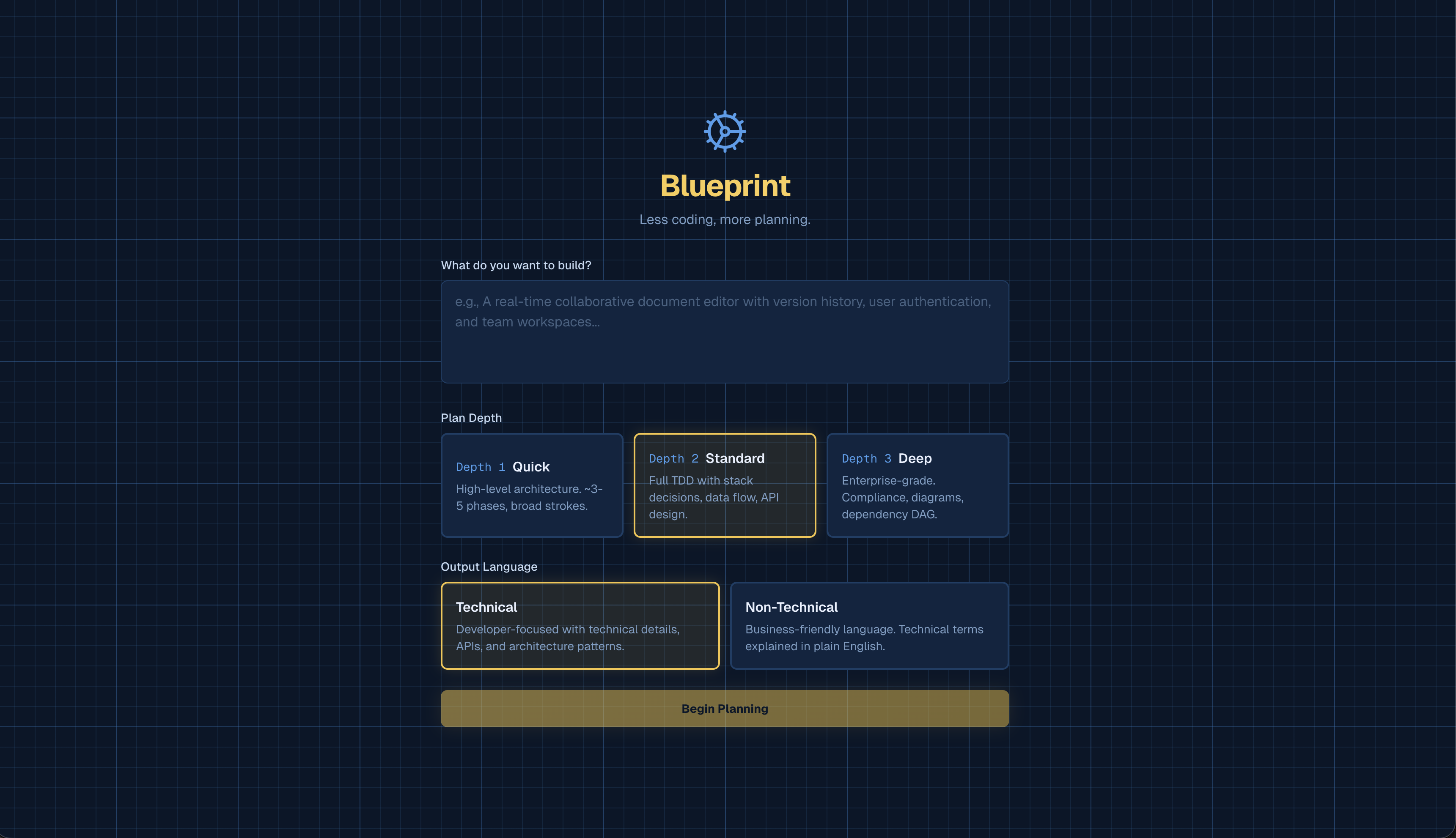
Our platform is an adaptive specification generator that transforms a simple idea into a structured Technical Design Document (TDD).
First, the user selects their preferred difficulty level, which controls how detailed and ambitious the generated system will be:
- Quick: for simple projects (e.g., a basic “Hello World” style app)
- Standard: for moderately complex, practical applications
- Deep: for production-grade systems suitable for real-world or commercial use
The user also chooses between technical and non-technical mode so the system can adjust language, assumptions and depth accordingly.
Next, the user enters a prompt just like they would on any AI platform. Instead of immediately generating output, our system intelligently analyses the prompt and asks targeted follow-up questions to clarify important requirements. Users can answer these questions or leave them blank if they prefer the system to make reasonable assumptions.
Using this information, the platform automatically generates a comprehensive Technical Design Document tailored to the selected difficulty and technical level. The TDD includes the structured details needed for implementation, meaning the user can simply pass it to a developer or “vibe coder” to build the requested application.
Why it’s better
Traditional AI app generation often looks like this: One prompt → Incomplete output → Many manual fixes
Our system improves this workflow by front-loading the thinking process: Prompt → Guided questioning → Structured TDD → Build-ready application
By proactively asking the right questions, our platform produces designs that are:
- more complete
- more efficient to implement
- better aligned with user intent
- and faster to take into production
The process is largely autonomous, stepping in only when meaningful user input is needed. The result is a smoother path from idea to fully specified system.
How we built it
We built BluePrint as a fully autonomous, multi-stage AI consulting pipeline designed to transform vague ideas into production-ready Technical Design Documents (TDDs).
At the core of the system is a LangGraph state machine that runs a five-stage loop: discovery → architect → critics → aggregator → convergence
This pipeline operates without human hand-holding, making the agent truly goal-driven rather than a simple chatbot.
Claude (Primary reasoning engine)
Claude Sonnet 4.6 performs the heavy lifting across four roles:
- Discovery: generates targeted clarification questions based on the user’s prompt
- Architecture: produces and iteratively refines the full TDD
- Aggregation: scores section confidence and incorporates critic feedback
- Export: formats structured outputs (Markdown/PDF/DOCX)
Crucially, Claude processes the entire evolving TDD in-context each loop, enabling deep architectural reasoning over large structured documents.
Gemini Critics (Adversarial validation)
We instantiated three stateless Gemini critics in parallel each loop to simulate real-world review pressure:
- Tech Lead critic: stack logic, scalability, and dependency checks
- BearingPoint-style Consultant critic: DORA, EU AI Act, and Green Software compliance
- Logic Auditor: variable consistency and dangling logic detection
Because these critics are stateless, they are freshly instantiated every iteration and cannot become complacent. Claude absorbs their feedback and refines the plan until mathematical convergence is reached.
Value framing
The agent produces structured TDD outputs exportable to PDF, DOCX, or Markdown. Each session costs roughly $0.30 in API usage while replacing hours of manual architecture and compliance work, directly supporting the Agentic AI track’s value requirement.
Challenges we ran into
Balancing depth vs. usability
One of the hardest problems was deciding how many clarification questions to ask. Too few questions reduced architectural quality, while too many increased user friction. We addressed this by conditioning question depth on the selected difficulty mode.
Maintaining critic independence
Ensuring the Gemini critics remained truly stateless required careful orchestration. Any accidental context leakage risked critics becoming less adversarial over time.
Consistent structured outputs
Generating deterministic, well-formed TDD JSON across widely different prompts required significant prompt engineering and schema discipline.
Real-time convergence detection
Designing a reliable mathematical stopping condition using cosine similarity and confidence thresholds took several iterations to stabilise.
Accomplishments that we’re proud of
- Built a fully autonomous AI consulting pipeline, not just a chatbot
- Implemented a multi-agent adversarial review loop with mathematical convergence
- Successfully simulated senior consultant behaviour through structured discovery questioning
- Produced production-ready, exportable TDDs rather than vague text output
- Integrated live voice executive briefings via ElevenLabs
- Achieved end-to-end plan generation in under a minute at low API cost
Most importantly, we created a system that meaningfully reduces the gap between idea and implementation.
What we learned
This project reinforced several key insights:
- Most AI generation failures stem from underspecified requirements, not weak models
- Structured questioning dramatically improves downstream output quality
- Multi-agent adversarial loops produce noticeably more robust designs
- Users value reduced cognitive load more than raw generation speed
- True agentic systems must have clear termination criteria and measurable value
We also gained hands-on experience orchestrating long-context reasoning with Claude and coordinating stateless multi-agent critics at scale.
What’s next for BluePrint
We see several high-impact directions:
- Token and cost dashboards for explicit value tracking
- Learning from past sessions to reduce question volume over time
- Deeper regulatory packs beyond DORA and EU AI Act
- Direct code generation pipelines from the validated TDD
- Team collaboration mode for multi-stakeholder planning
- Fine-tuned critic specialisations for different industries
Our long-term vision is for BluePrint to become the default front-end layer between human intent and autonomous software creation, ensuring every build starts from a battle-tested plan.
Built With
- claude
- gemini
- langgraph


Log in or sign up for Devpost to join the conversation.