

Inspiration: every teacher has watched a student's face go blank mid-lesson and had no way to catch it in real time, so we wanted to turn that moment of confusion into an instant, personalized fix.
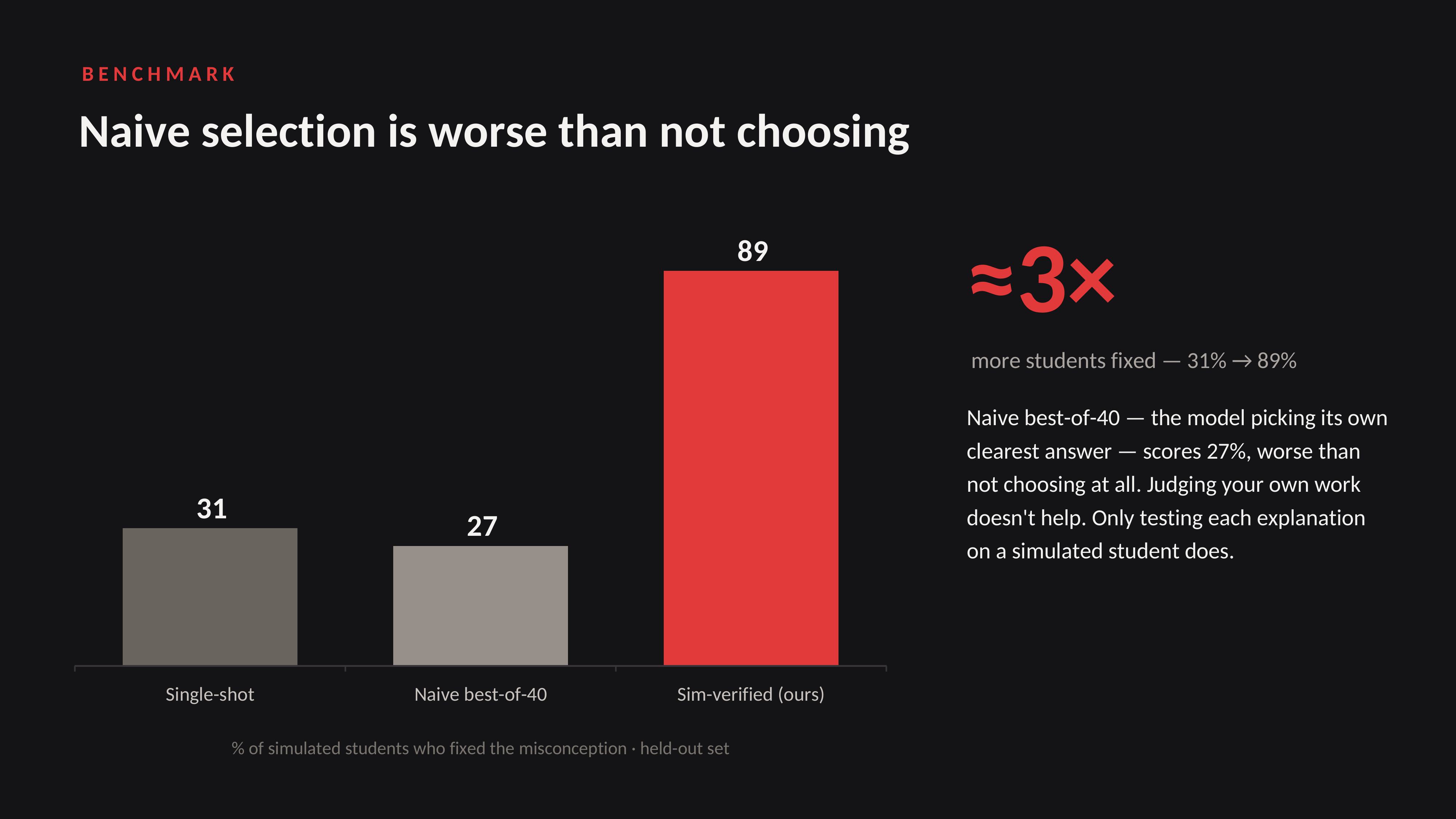
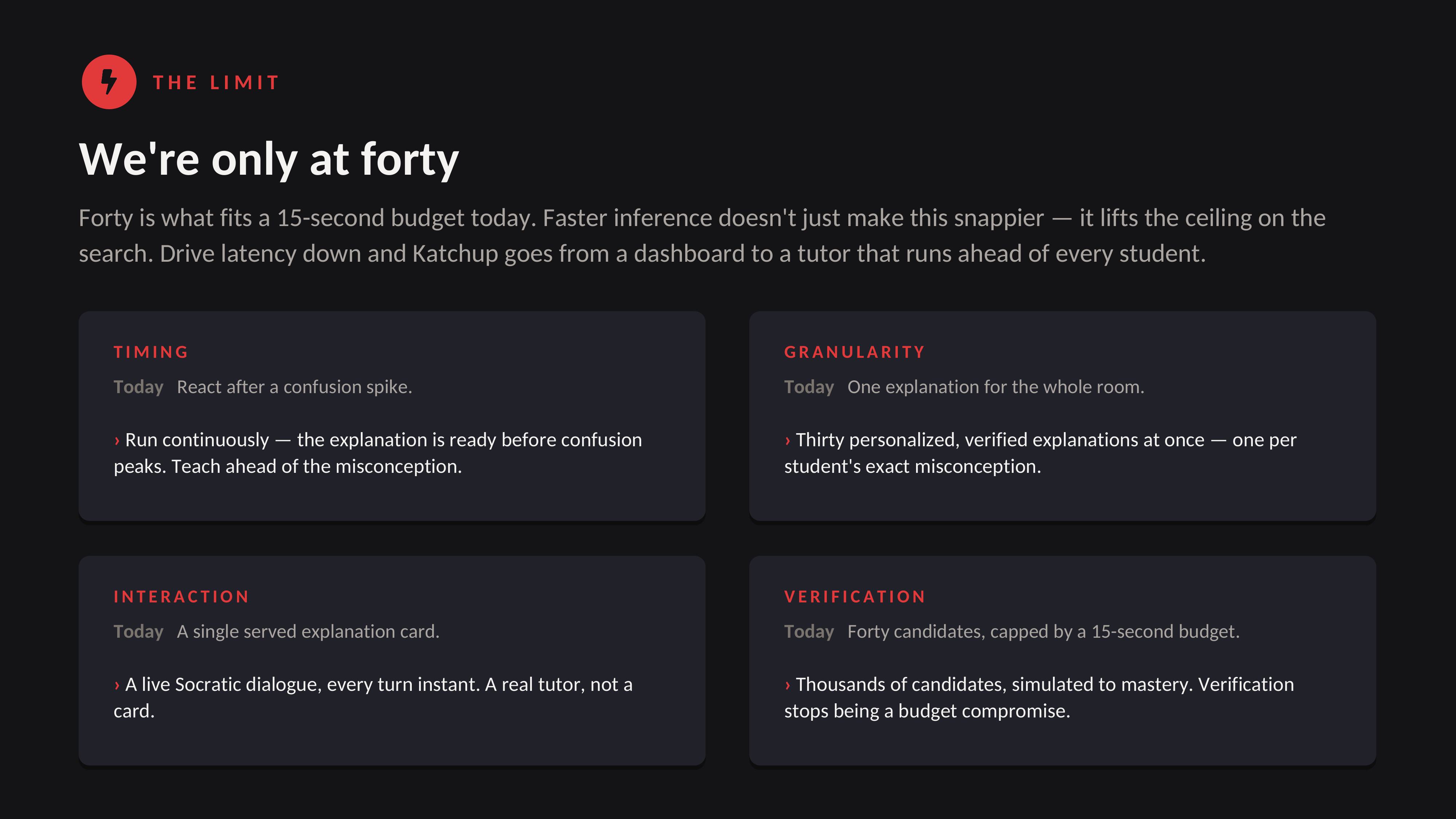
What it does: Katchup watches a student's face for confusion and the teacher's words live, and the instant someone gets lost it pins the exact sentences that lost them, then generates 40 explanations, simulates which one actually teaches that student, and serves the winner with a custom diagram.
How we built it: A FastAPI message bus wires four modules, perception (MediaPipe face-confusion + Whisper transcription), diagnosis (Claude infers the misconception + a transfer question), generation (40 candidates simulation-verified on our own Qwen served via vLLM on a Blackwell B300), and an editorial Streamlit student/teacher UI, all streaming in real time.
Challenges we ran into: getting vLLM to run on a brand-new B300 was a CUDA toolchain gauntlet (the system nvcc couldn't even target Blackwell's sm_103a), and WebRTC, macOS camera/mic library conflicts, and end-to-end latency each fought us before the loop ran clean.
Accomplishments that we're proud of: we proved the whole thesis on real hardware: verification-by-simulation scored 0.91 vs 0.24 for naive best-of-N and 0.18 single-shot on our own served model, a working product, not a mockup.
What we learned: spending inference-time compute to verify an answer by simulating the learner beats just generating one, and the hardest part of "use your own model" is rarely the model; it's the toolchain, the networking, and the seams between the pieces.
What's next for Katchup: per-student memory that tracks each learner's misconceptions over time, a real classroom pilot, and pushing the live loop under two seconds so the fix lands the moment the confusion does.
Built With
- claude
- python

Log in or sign up for Devpost to join the conversation.