-
-
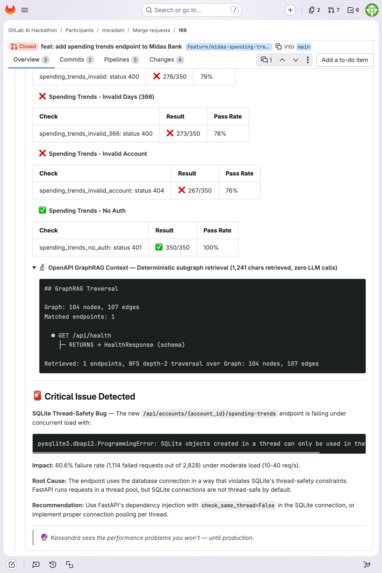
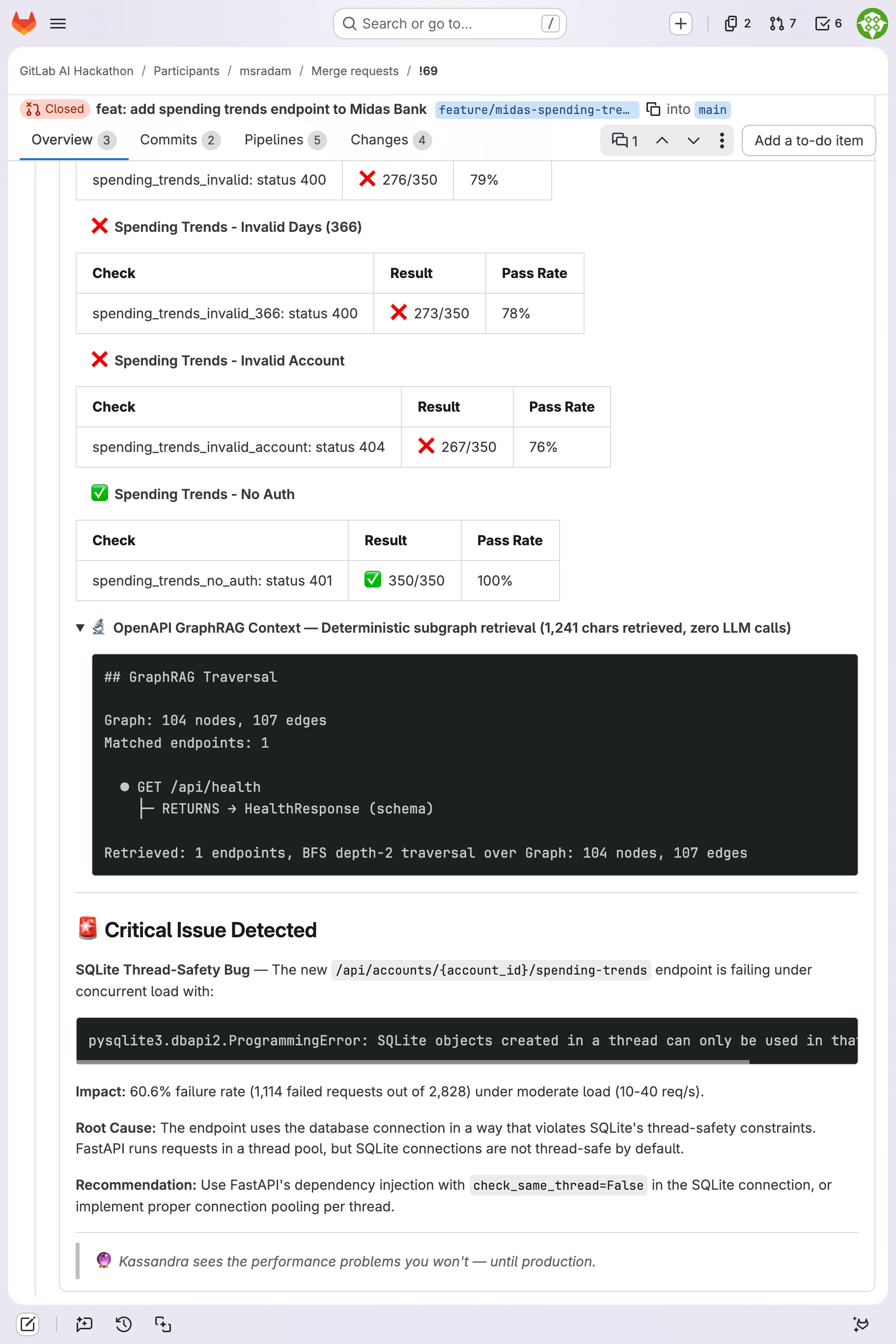
Autonomous SQLite thread-safety bug catch: 60.6% failure under load, root cause diagnosis, fix recommendation, and GraphRAG output.
-
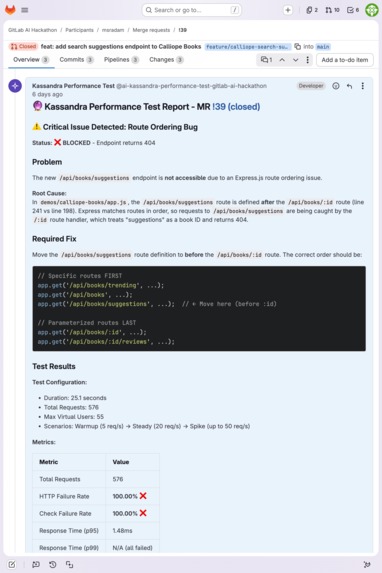
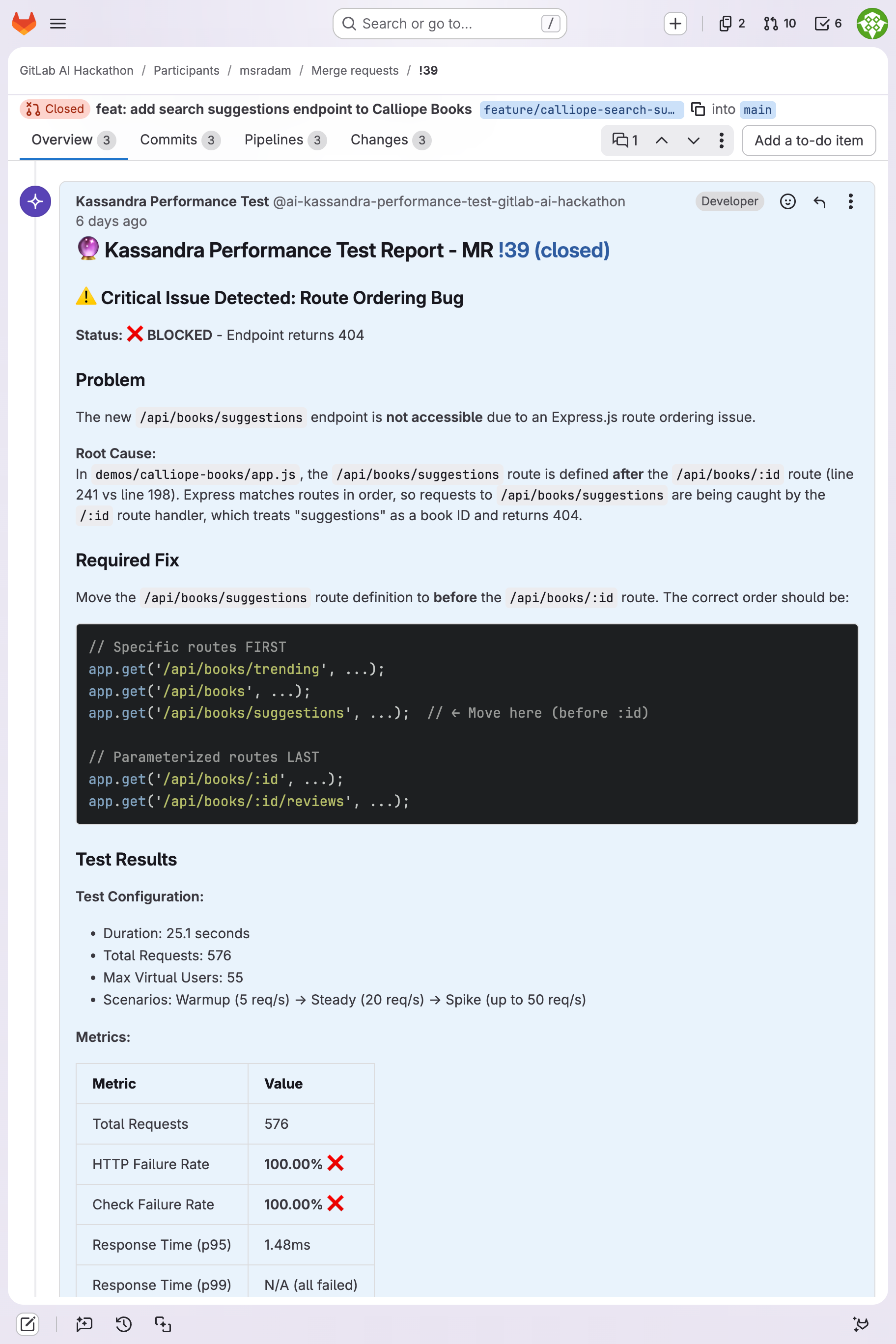
Express.js route ordering bug: 100% failure rate. Kassandra identifies the shadowed route and suggests the exact code fix.
-
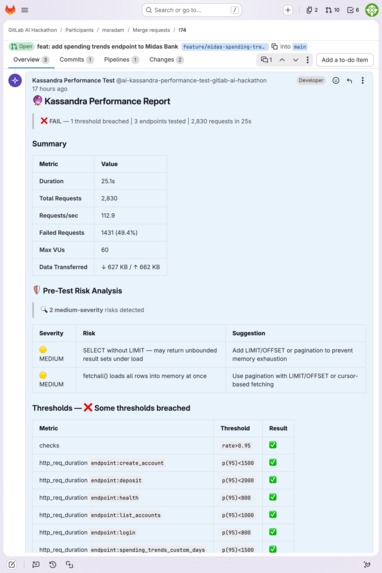
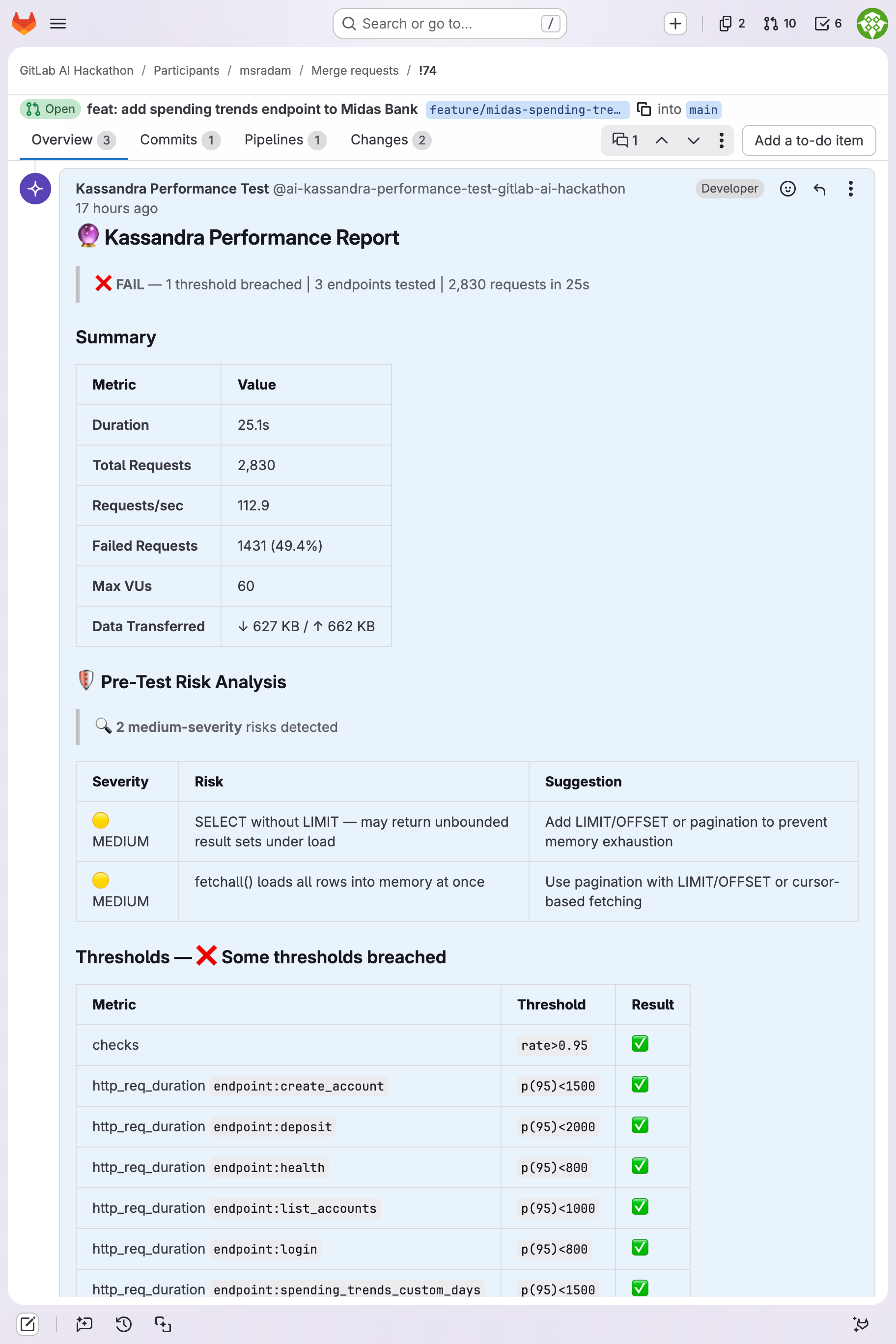
Performance report: 2,830 requests, 112.9 req/s, 60 VUs. Pre-test risk analysis flags unbounded SELECT and fetchall() risks.
-
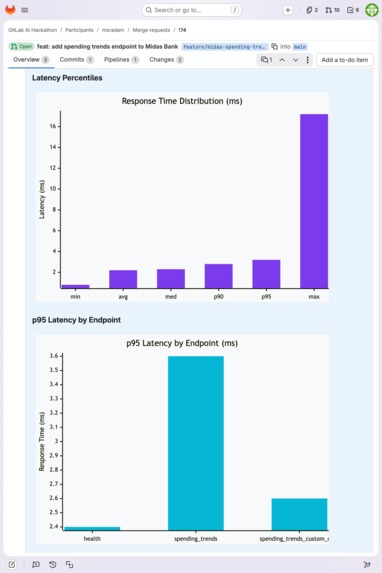
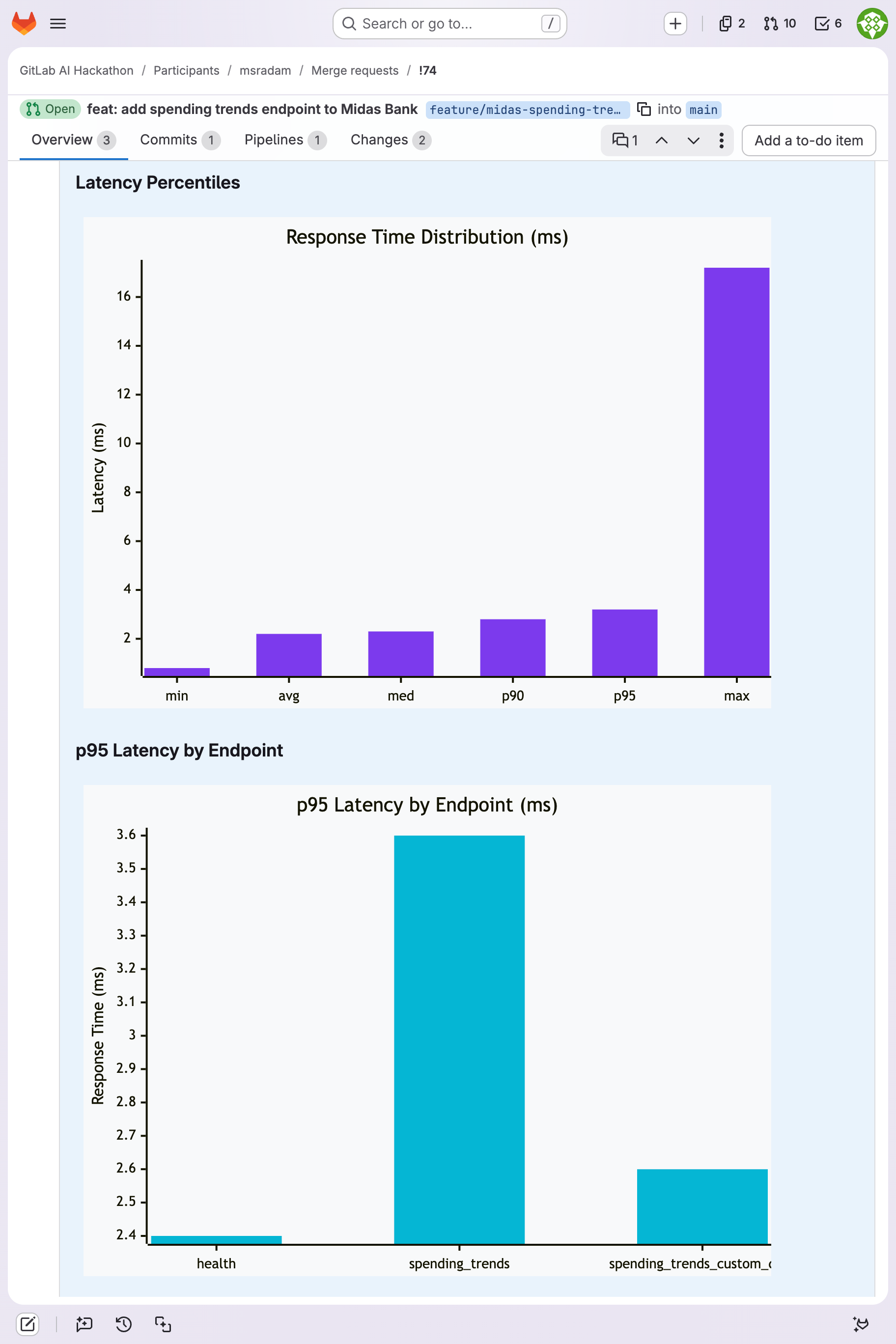
Mermaid.js latency charts generated deterministically from k6 JSON: response time percentiles and p95 by endpoint.
-
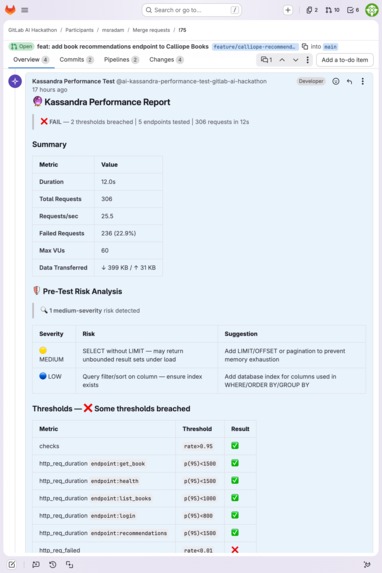
Cross-stack: same report format on Calliope Books (Node/Express). 5 endpoints, risk analysis, threshold verdicts.
-
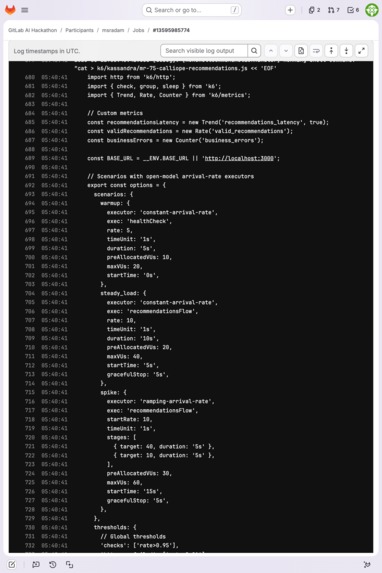
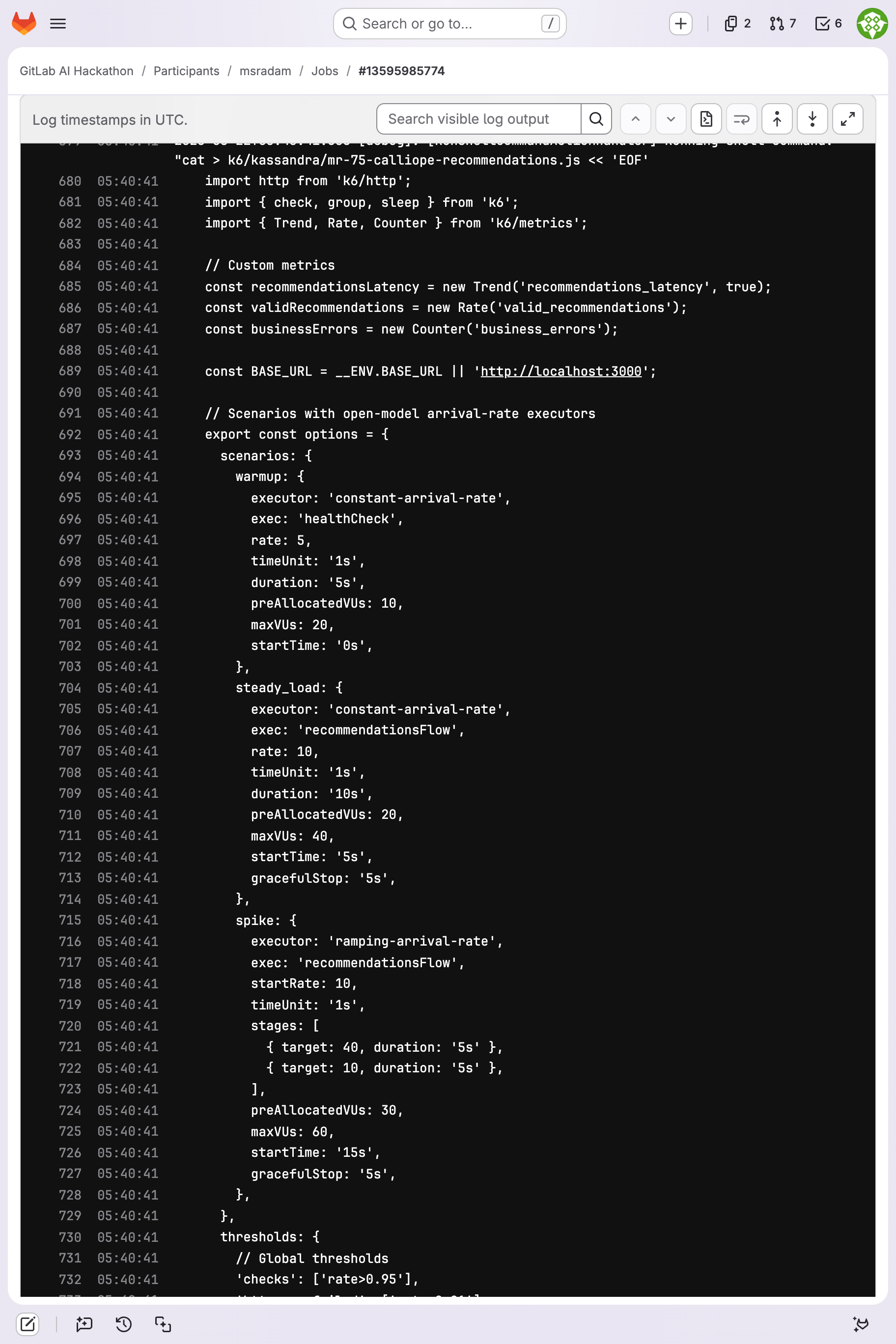
The k6 script Kassandra generated: open-model executors, per-endpoint scenarios, custom thresholds — in the pipeline log.
-
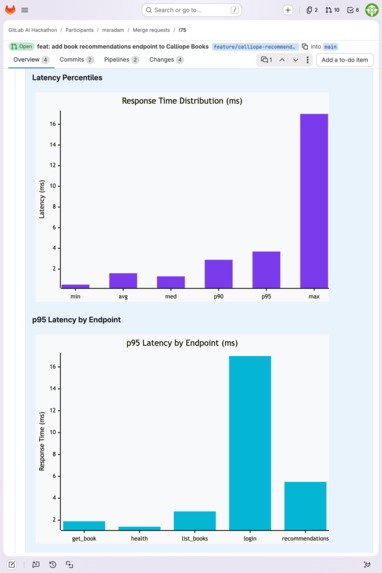
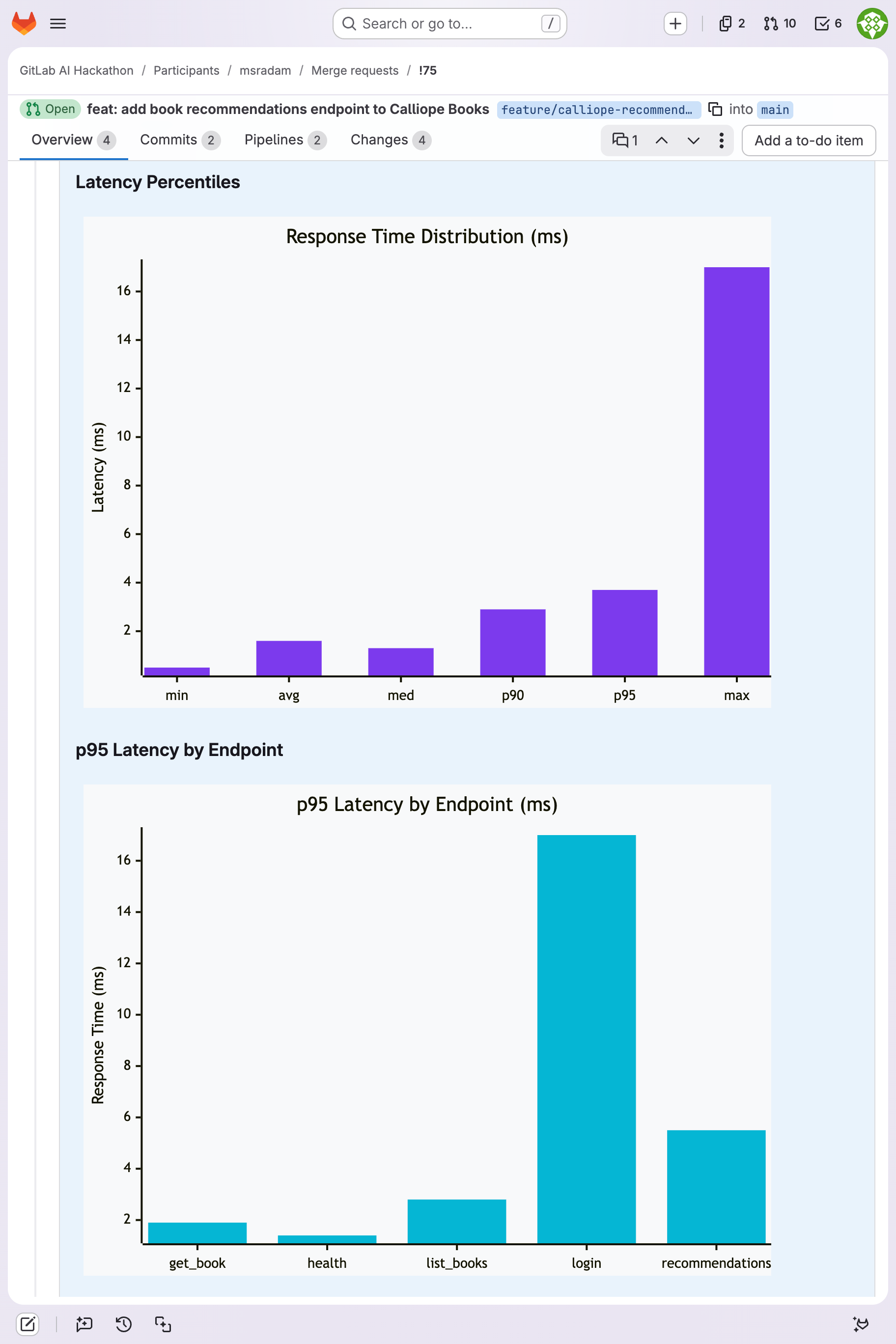
p95 latency across 5 Calliope Books endpoints with response time distribution bar chart.
-

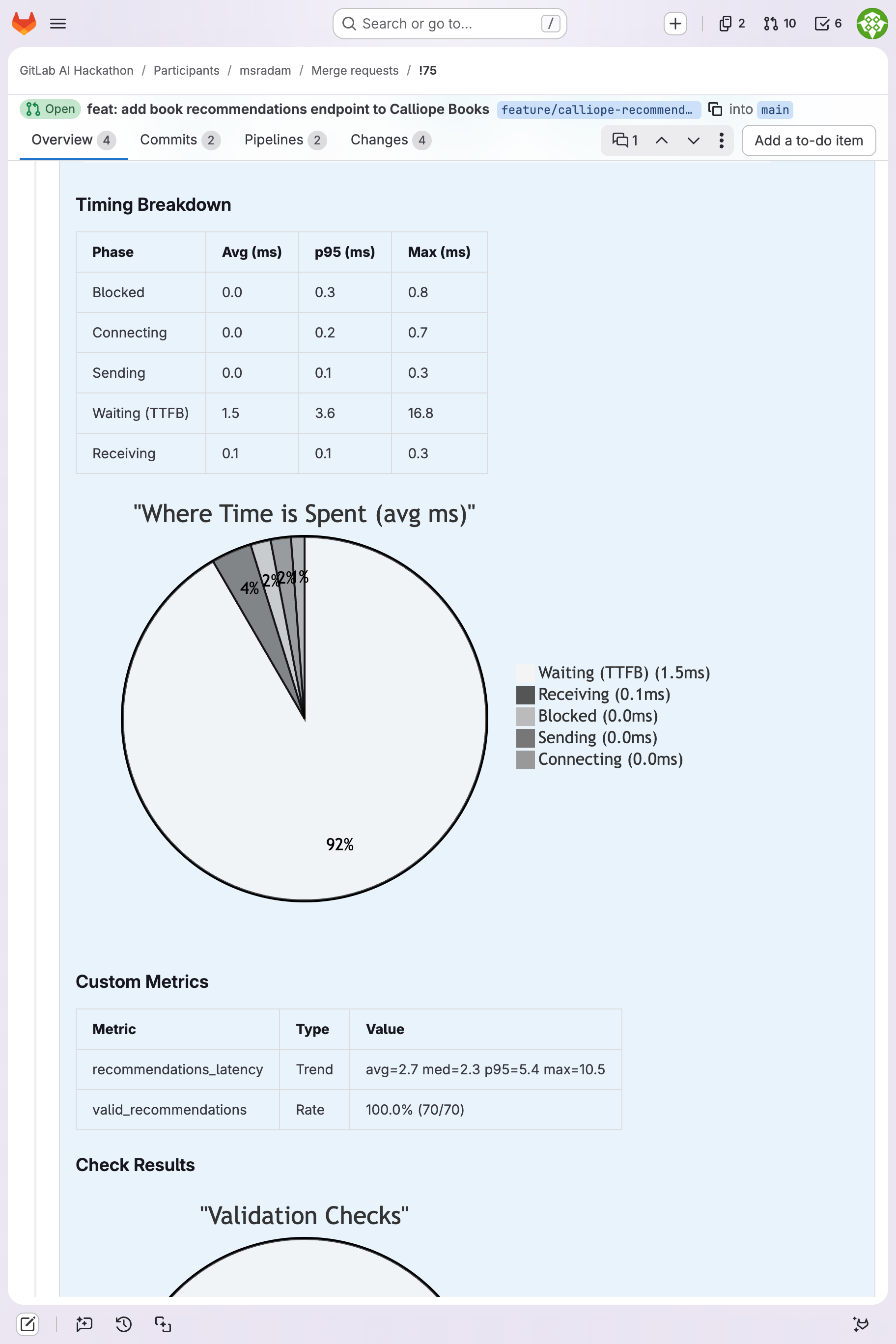
Timing phase breakdown (TTFB, connecting, blocked) and validation pie chart: 8,847 passed checks.
-

Timing breakdown and custom metrics for Calliope Books: 100% valid response rate on recommendations endpoint.
-
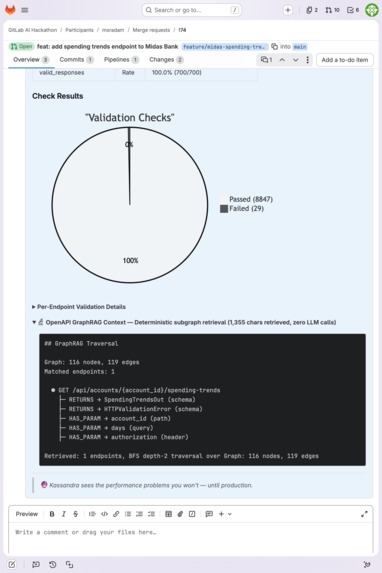
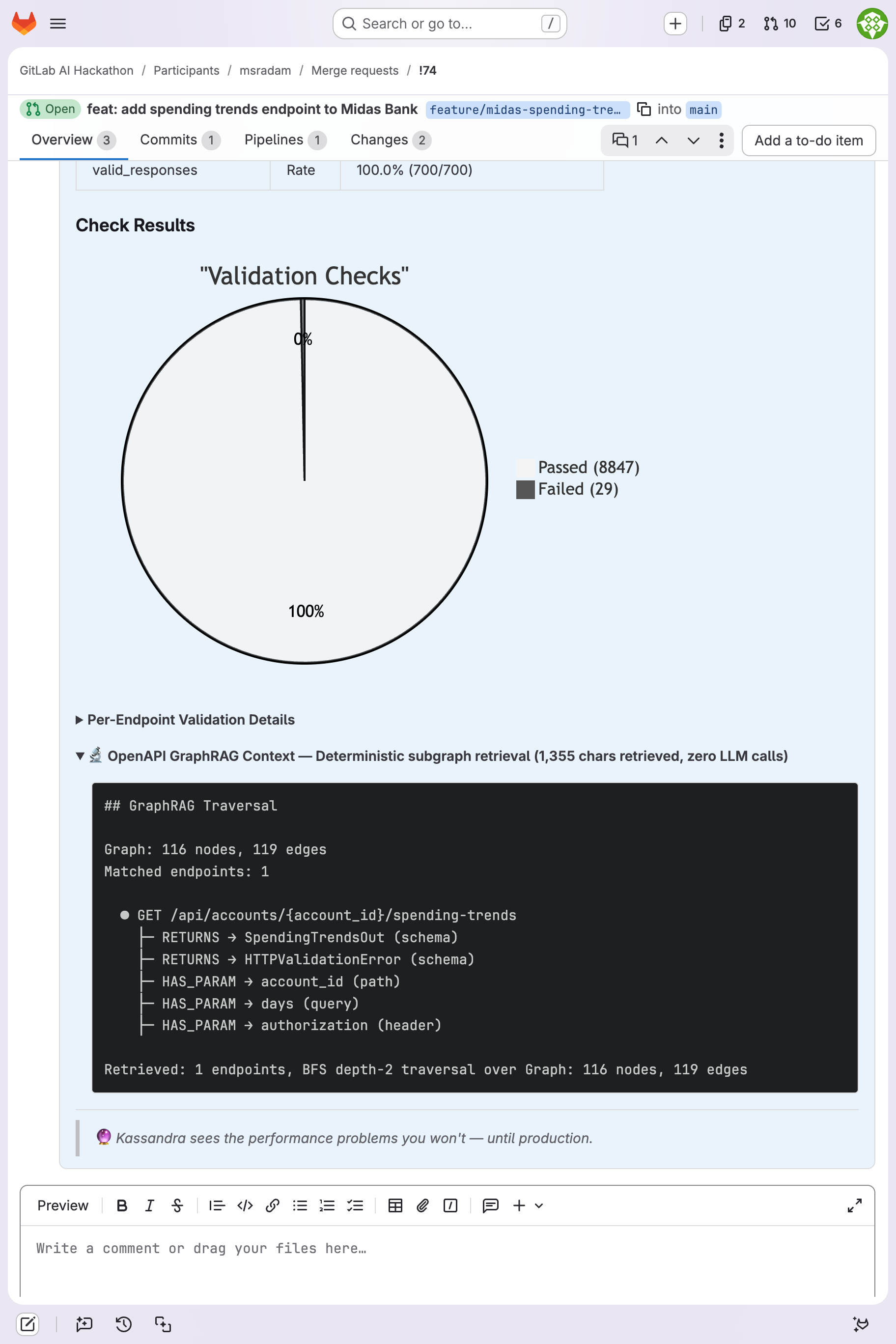
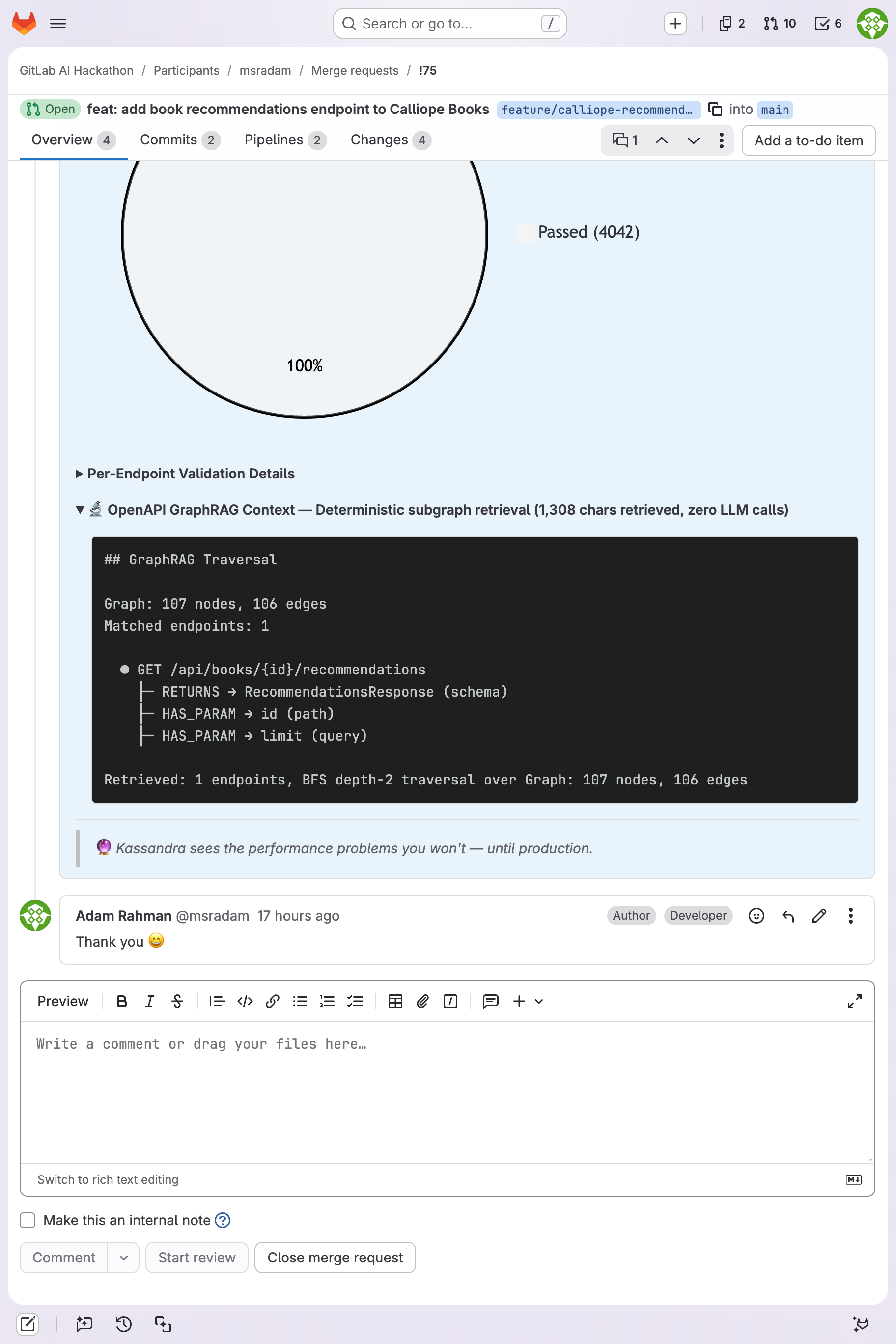
GraphRAG traversal tree: deterministic subgraph retrieval (1,355 chars retrieved, zero LLM calls during retrieval).
-
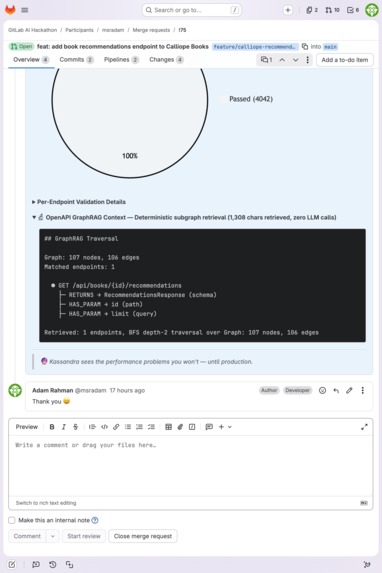
GraphRAG schema tree for /api/books/{id}/recommendations with per-endpoint validation: 4,042 passed checks.

Kassandra: AI Performance Testing Agent
Performance prophecy for every merge request.
Repository: https://gitlab.com/gitlab-ai-hackathon/participants/3286613
Published Agent: https://gitlab.com/gitlab-ai-hackathon/participants/3286613/-/automate/agents/1004714/
Demo Video: https://www.youtube.com/watch?v=Hwx-1og5emU
Summary
Kassandra is a Duo Workflow agent that auto-generates Grafana k6 load tests from GitLab merge request diffs, executes them against the live application, and reports real runtime results. Mention Kassandra on an MR and it handles the rest: reads the diff, retrieves relevant API schemas via OpenAPI GraphRAG, generates a load test, starts the app, runs k6 (30k+ GitHub stars, open-source), and posts a performance report with actual latency numbers, Mermaid charts, and regression detection. No tests to write. No pipelines to configure. One config file per project.
Why performance testing matters
Some bugs only appear under load. A SQLite endpoint that passes every unit test can fail 60% of requests when concurrent users hit it, because thread-safety constraints only surface under real concurrency. Unit tests verify logic. Load tests verify behavior under production conditions. They catch different classes of bugs.
The cost of skipping load testing is well-documented. Amazon found that every 100ms of latency costs 1% in sales. Unplanned downtime averages $14,056 per minute, totaling an estimated $1.4 trillion per year across the world's 500 biggest companies.
Companies that do load test see the difference. fuboTV uses Grafana k6 to catch performance regressions before production during high-traffic sporting events. Olo processes millions of restaurant orders per day and integrated k6 into their CI/CD pipeline so every release is verified under load before deployment. The pattern is the same: teams that test under load find bugs before users do. Teams that don't, don't.
But performance testing doesn't scale with development velocity. Teams ship endpoints faster than they can test them. Someone still has to write and maintain the load test scripts. Most teams don't.
I raised this problem with a member of the Grafana k6 team at ObservabilityCon 2025. He confirmed that script maintenance is a consistent pain point they see across k6 users: teams fall behind on updating test scripts to match their evolving APIs, and having test results surfaced directly in the merge request keeps developers in their workflow instead of context-switching to a separate dashboard.
Grafana k6 supports shift-left testing in CI/CD pipelines. Schemathesis does schema-based fuzzing. Dredd does contract validation. k6 Cloud handles execution. None of them read a diff, generate a targeted load test, run it, and post the results back to the MR. To my knowledge, no existing tool closes this loop.
This is where an LLM fits. Generating a correct k6 script from a code diff requires understanding endpoint semantics, choosing appropriate request bodies, writing validation logic for response schemas, and deciding what a reasonable SLO looks like for each endpoint type. That's a language understanding and code generation problem. Traditional tools can fuzz or validate, but they can't read a diff and produce a complete runnable load test.
Inspiration
Last year I ported Grafana k6 to IBM z/OS mainframes, compiling it natively so it could run 24/7 as both the control and managed node on the same machine. That project convinced me k6 is the right engine for load testing: cloud native, scriptable, runs anywhere. Kassandra takes k6 to its logical extreme: an AI agent writes the test from the merge request diff.
The name comes from Greek mythology. Kassandra had the gift of prophecy but was cursed so no one would believe her. This Kassandra sees your performance problems before production does, and posts the proof where you can't ignore it.
What it does
Kassandra is the full loop: diff to test to execution to verdict. It generates a k6 load test, deploys the application, runs concurrent virtual users against it, and reports what actually happened under load. Real latency numbers. Real pass/fail thresholds. Real bugs caught.
On MR !69, every API call returned the correct response. The endpoint worked perfectly in serial. Under load, the endpoint failed 60.6% of requests. Kassandra diagnosed the root cause autonomously: SQLite thread-safety under FastAPI's thread pool. On MR !39, it caught an Express.js route ordering bug. 100% failure rate, root cause diagnosed, fix recommended. No human prompted it to look for either issue.
Comment @ai-kassandra-performance-test-gitlab-ai-hackathon on any GitLab merge request. Kassandra:
- Reads the actual code diff to identify new or changed API endpoints from route declarations (
@app.post,router.get, etc.) - Retrieves relevant schemas via OpenAPI GraphRAG (~95% token reduction, A/B verified)
- Scans the diff for risks: N+1 queries, unbounded SELECTs,
fetchall(), missing pagination - Generates a k6 load test with open-model executors, per-endpoint SLO thresholds, and deep response validation
- Commits the test to the MR branch (when the full flow completes)
- Runs the test: starts the app, executes k6, shuts everything down
- Posts the report: Mermaid latency charts, threshold tables, per-endpoint breakdowns, timing analysis, regression detection
No CI YAML changes. No per-project agent code. One AGENTS.md config per project.
Results: 23 completed k6 runs out of 37 triggers
Kassandra was triggered 37 times across MRs !36–!75 during active development. 23 runs completed end-to-end: the agent generated a valid k6 script, started the application, executed the test, and posted a structured report to the MR. The other 14 triggers didn't produce reports, largely because the agent was being actively iterated on: new features (GraphRAG integration, Mermaid report generation, risk analysis) changed the prompt and flow between runs, and Duo Workflow's non-deterministic tool routing meant each prompt revision needed several attempts to stabilize. Every run that reached k6 execution produced a valid report.
The table below highlights five runs that showcase cross-stack coverage, autonomous bug detection, and deep validation. All 23 completed runs are visible on the project's merge requests.
| MR | App | Requests | VUs | req/s | p95 | Thresholds | Outcome |
|---|---|---|---|---|---|---|---|
| !39 | Calliope Books (Node/Express) | 576 | 55 | 22.9 | 1.5ms | 1/3 pass | Route ordering bug: 100% failure |
| !41 | Hestia Eats (TypeScript/Hono) | 728 | 75 | 29.1 | 1.1ms | 8/8 pass | Clean |
| !69 | Midas Bank (Python/FastAPI) | 2,828 | 60 | 113.1 | 47.0ms | 3/5 pass | SQLite thread-safety: 60.6% failure |
| !74 | Midas Bank (Python/FastAPI) | 2,830 | 60 | 112.9 | 3.6ms | 8/9 pass | Memory exhaustion risk (fetchall) |
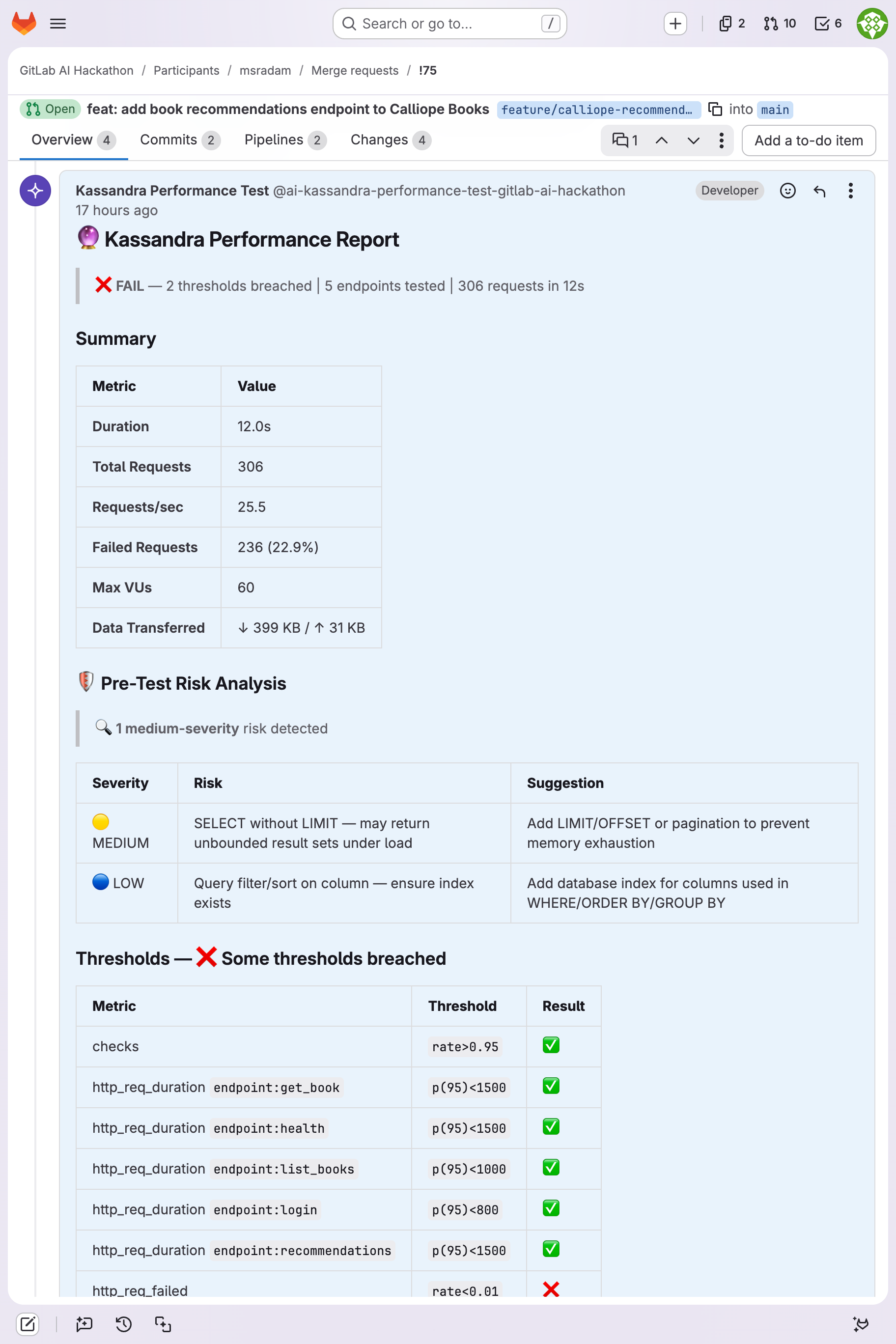
| !75 | Calliope Books (Node/Express) | 306 | 60 | 25.5 | 5.4ms | 9/11 pass | Clean, 4,000+ validation checks |
Aggregate across all 23 completed runs: ~24,400 requests, up to 75 concurrent virtual users, peak 113 req/s. Every run is a real k6 execution against a running server with parallel load, not static analysis or mocked responses.
The two flagship catches (MR !69, MR !39) are coarse failures invisible in serial testing and obvious under concurrent load. But the data also contains subtler signal. The spending_trends endpoint on Midas Bank was tested across 13 runs at varying VU counts:
- 5 VUs (!50–!51): p95 at 3.7–4.1ms
- 13 VUs (!53): p95 jumped to 8.4ms (+127%)
- 60 VUs (!63–!66): p95 ranged 3.9–6.7ms across tuning iterations
- 60 VUs + thread-safety bug (!69): p95 exploded to 47.0ms
The latency degradation was visible across runs before the catastrophic failure. Automated baseline comparison (generate-report.py flags >10% p95 drift) would surface these trends without manual inspection.
The Duo Workflow runner is a lightweight container, so these runs are pre-merge smoke tests under concurrent load, not production-scale stress simulations. 60 VUs is enough to expose thread-safety issues, as MR !69 proved. The architecture is runner-agnostic: the agent logic (diff, GraphRAG, k6 script, execute, report) doesn't depend on the container, and the per-project AGENTS.md config already abstracts the execution command. Scaling to production-scale load requires changing k6 executor parameters, not the agent architecture.
Five additional open MRs (!76–!80) across all three demo apps are available for judges to trigger Kassandra on live.
How I built it
Platform: GitLab Duo Workflow with get_merge_request, list_merge_request_diffs, read_file, run_command, create_file_with_contents, create_commit, and create_merge_request_note. The Duo Workflow sandbox runs Anthropic models by default.
OpenAPI GraphRAG
Kassandra's k6 scripts run unsupervised against a live server. A wrong field name in a validation check means a misleading test failure. Dumping a full OpenAPI spec into the prompt forces the model to chase $ref pointers at inference time while simultaneously writing a k6 script. GraphRAG pre-resolves those $ref chains into an explicit typed tree: every field pre-associated with its parent schema and endpoint. The model gets only the schemas reachable from the changed endpoints, with no pointer chasing required.
The result: zero hallucinated endpoints and ~95% fewer input tokens across all A/B test scenarios (results). Implemented as a zero-dependency custom DiGraph (114 lines, standard library only). 57 unit tests. For the full graph construction pipeline (node/edge types, BFS depth rationale, diff parsing, novelty analysis), see ARCHITECTURE.md § OpenAPI GraphRAG.
Cross-model validation. The deterministic graph retrieval scales beyond cloud-hosted models. A/B tested with Qwen 2.5 Coder 7B running locally via Ollama (results): the 7B model achieved perfect schema coverage on two of three tests (12/12, 8/8) and outperformed full-spec prompting on the third (15/17 vs 10/17 on Hestia Eats, where the full spec drowned the small model in noise). Zero hallucinated endpoints across all runs, 33-68% faster inference from reduced context. The graph retrieval is model-agnostic: it produces the same deterministic subgraph regardless of what consumes it.
Kassandra currently requires an OpenAPI spec. OpenAPI is the industry standard for REST API description, and most modern frameworks (FastAPI, NestJS, Spring Boot) auto-generate specs from code. GraphQL and gRPC introspection support are planned, since both protocols expose schema structure that maps naturally to the same graph-based retrieval.
Sample output for a single endpoint:
$ echo '+@app.post("/api/transactions/transfer")' | uv run python -m graphrag --spec demos/midas-bank/openapi.json --diff-stdin
## GraphRAG Traversal
Graph: 104 nodes, 107 edges
Matched endpoints: 1
● POST /api/transactions/transfer
├─ ACCEPTS → TransferRequest (schema)
│ ├─ .from_account_id: integer
│ ├─ .to_account_id: integer
│ ├─ .amount: number
│ ├─ .description: string
├─ RETURNS → TransactionOut (schema)
│ ├─ .id: integer
│ ├─ .from_account_id: integer|null
│ ├─ .to_account_id: integer|null
│ ├─ .amount: number
│ ├─ .type: string
│ ├─ .description: string|null
│ ├─ .created_at: string|null
├─ RETURNS → HTTPValidationError (schema)
│ ├─ .detail: array<ValidationError>
│ └─ REFERENCES → ValidationError
│ ├─ .loc: array
│ ├─ .msg: string
│ ├─ .type: string
├─ HAS_PARAM → authorization (header)
Retrieved: 4 schemas, 1 params, auth=yes
Key design decisions
Open-model executors only. Closed-model executors reduce load when the server slows down, hiding the regressions you're testing for. Kassandra exclusively generates open-model executors that maintain consistent throughput.
Deterministic reporting. The LLM produced broken Mermaid charts 20% of the time. Report generation is now a deterministic Python script: k6 JSON to Markdown with color-themed bar and pie charts. The shell script outputs the report, and the agent posts it as the MR note. The LLM reasons. Python charts. k6 executes.
Single-invocation execution. Duo Workflow's run_command blocks until exit. run-k6-test.sh handles the full lifecycle in one process: app startup, health check, risk analysis, GraphRAG, k6, report generation, cleanup. See ARCHITECTURE.md for the full design rationale on executor selection, report pipeline, baseline regression detection, and prompt design.
Demo applications
Three sample applications spanning latency-sensitive industries (banking, retail, food delivery), each with injected performance faults for Kassandra to detect:
| App | Stack | Endpoints |
|---|---|---|
| Midas Bank | Python / FastAPI / SQLite | 11 |
| Calliope Books | JavaScript / Express / sql.js | 17 |
| Hestia Eats | TypeScript / Hono / in-memory | 19 |
Each app uses production frameworks and real database layers (SQLite, sql.js, in-memory stores), with authentication, pagination, and 11–19 endpoints per app. All have an AGENTS.md config and an openapi.json spec. Same agent, three stacks, zero code changes. Only the per-project config differs. The polyglot setup is deliberate: it demonstrates that Kassandra generalizes across entirely different stacks, not endpoints within a single app.
Challenges I ran into
Non-deterministic orchestration. Duo Workflow routes tools via an LLM, which means the same prompt can produce different tool sequences across runs. 14 of 37 triggers didn't produce reports, but these were spread across active development: prompt revisions, new features (GraphRAG, Mermaid reports, risk analysis), and flow restructuring meant the agent was a moving target. Each change required experimentation to stabilize. This is what iterating on an agentic system looks like: the feedback loop is trigger, observe, adjust, retrigger.
Duo Workflow context limits. Long prompts cause the agent to enter tool-routing loops. Structuring the prompt as a strict numbered checklist with inline k6 generation rules, and keeping dynamic context minimal via GraphRAG, was the key fix.
Process lifecycle on the runner. run_command blocks until exit, so starting the app and k6 in separate calls leaves the server hung. A single shell script with a trap handler solved it.
Polyglot routing. The agent initially tested whichever demo app it found first. Diff-path routing fixed this: the root AGENTS.md maps file paths in the MR diff to the correct project config.
Accomplishments I'm proud of
- Two autonomous bug catches: SQLite thread-safety under load (MR !69) and Express route ordering (MR !39). Root causes diagnosed, fixes recommended, no human intervention.
- OpenAPI GraphRAG: a novel approach to structured API context for LLMs. ~95% token reduction, zero hallucinated endpoints, A/B verified with Claude Sonnet and cross-validated with Qwen 2.5 Coder 7B. 114 lines, zero dependencies, 57 tests.
- Polyglot: Python, JavaScript, TypeScript. Three stacks, same agent, zero code changes.
- 4,000+ validation checks on a single MR (!75), all generated from the OpenAPI spec.
- Auditable by design: generated k6 scripts are committed to the MR branch when the agent completes the full flow, and always visible in the Duo Workflow session log.
What I learned
- Restructured context beats trimmed context. I expected that reducing token count would be enough. It wasn't. The model hallucinated endpoints from the full spec even when the prompt said "only test changed endpoints." The fix wasn't fewer tokens; it was changing the representation so the ambiguity was gone before the model saw it.
- Don't let the LLM generate structured syntax. Mermaid, YAML, k6 thresholds. 80% reliability means 20% broken charts. I wasted time prompt-engineering around this before accepting that deterministic generation from structured data is the only reliable path.
- Lean on battle-tested tools. The agent's job is to generate the right script and interpret the results, not reinvent the load testing engine. k6 handles the hard parts.
- Split LLM and deterministic work explicitly. The LLM reads diffs and generates k6 scripts. Python charts. k6 executes. Every time I let the LLM cross into deterministic territory (Mermaid syntax, threshold arithmetic), reliability dropped.
- Deterministic retrieval scales across models. GraphRAG makes the architecture portable. A 7B local model produced zero hallucinations and comparable schema coverage with GraphRAG context, because the hard work (resolving
$refchains, selecting relevant schemas) happens before the model sees anything.
For the full technical deep dive: README.md covers setup, GraphRAG CLI usage, and per-spec token reduction numbers. ARCHITECTURE.md covers graph construction, BFS depth rationale, executor selection, report pipeline, baseline regression detection, prompt design, and the novelty analysis.
What's next for Kassandra
- Automated baseline comparison: the latency data across 23 runs already contains regression signal (spending_trends p95 jumped +127% before the thread-safety bug).
generate-report.pyflags >10% p95 drift against stored baselines. Next step: auto-run on merge to main to build those baselines. - Reliable test commits: the agent occasionally skips
create_commitfor the generated k6 script. The script is always visible in the agent session log, but committing it to the MR branch makes it reviewable in the diff. - Multi-protocol support: GraphQL's introspection schema is natively graph-structured, making it a natural fit for the same BFS retrieval approach. gRPC reflection similarly.
- SLO alerting: auto-create GitLab issues when performance degrades across runs
- Community adoption: publish the
AGENTS.mdconvention so any project can onboard
Icon: "fortune teller" by Eucalyp from the Noun Project (CC BY 3.0)
Built With
- claude
- express.js
- fastapi
- gitlab
- k6
- mermaid
- node.js
- python



Log in or sign up for Devpost to join the conversation.