-
-

Title Page
-
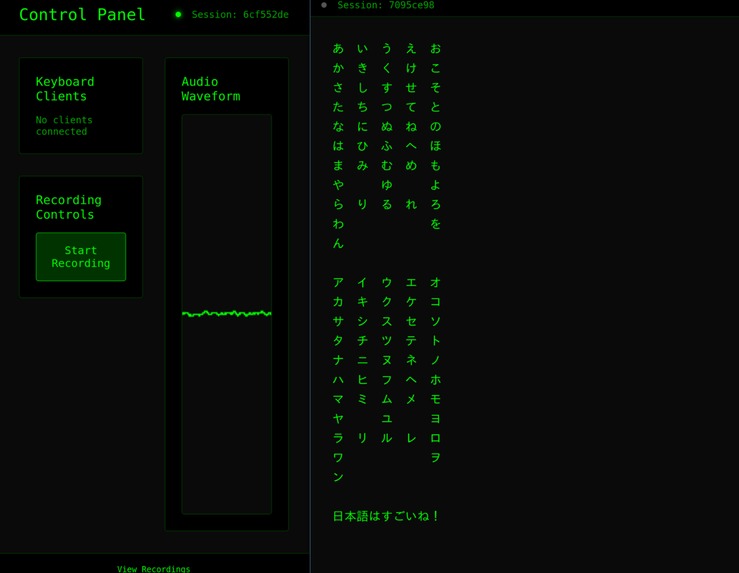
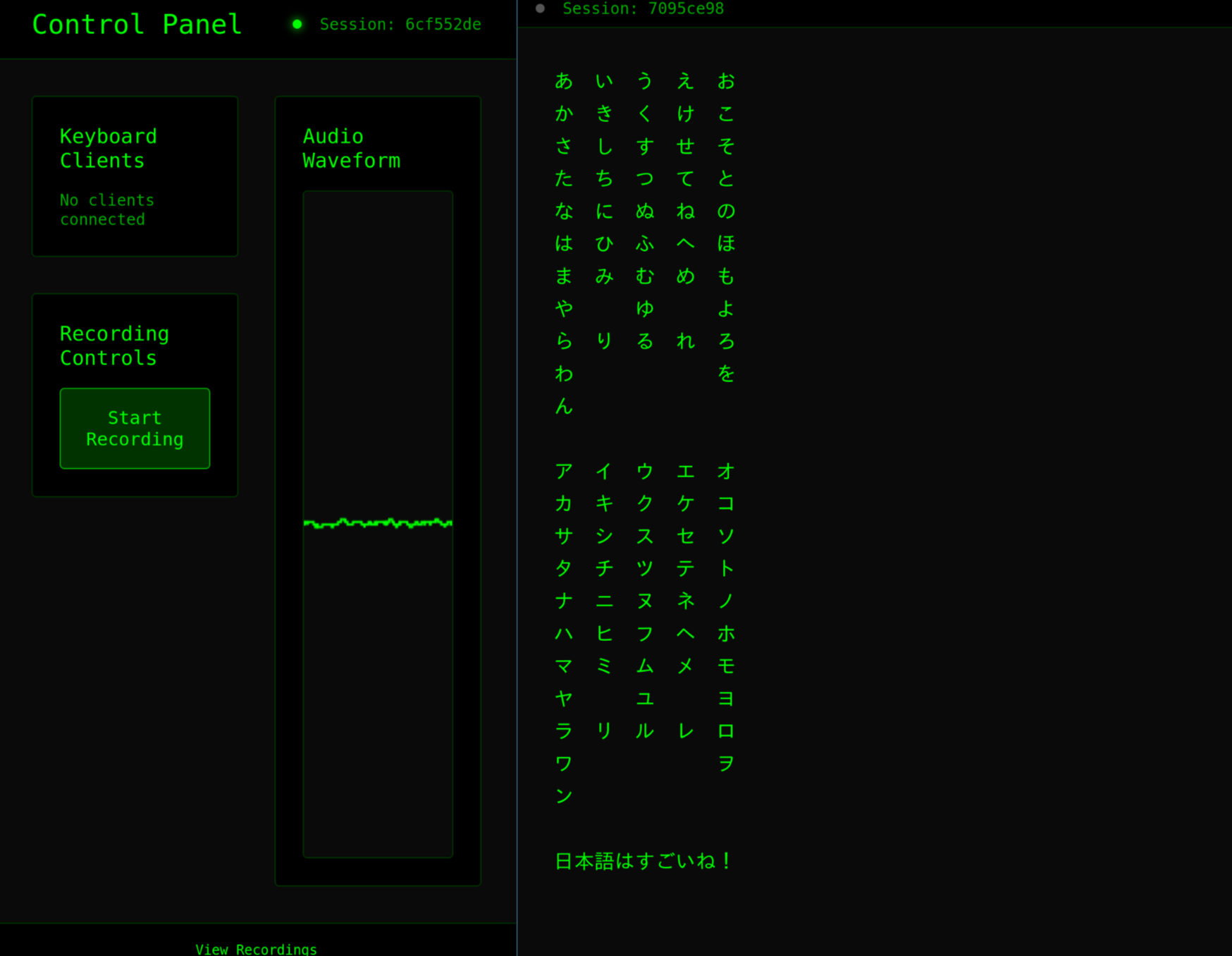
Control Panel, Typing Japanese
-
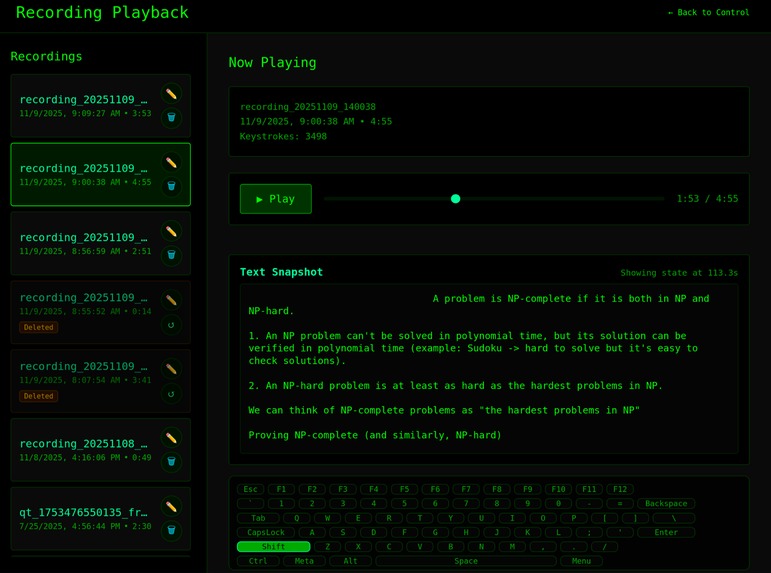
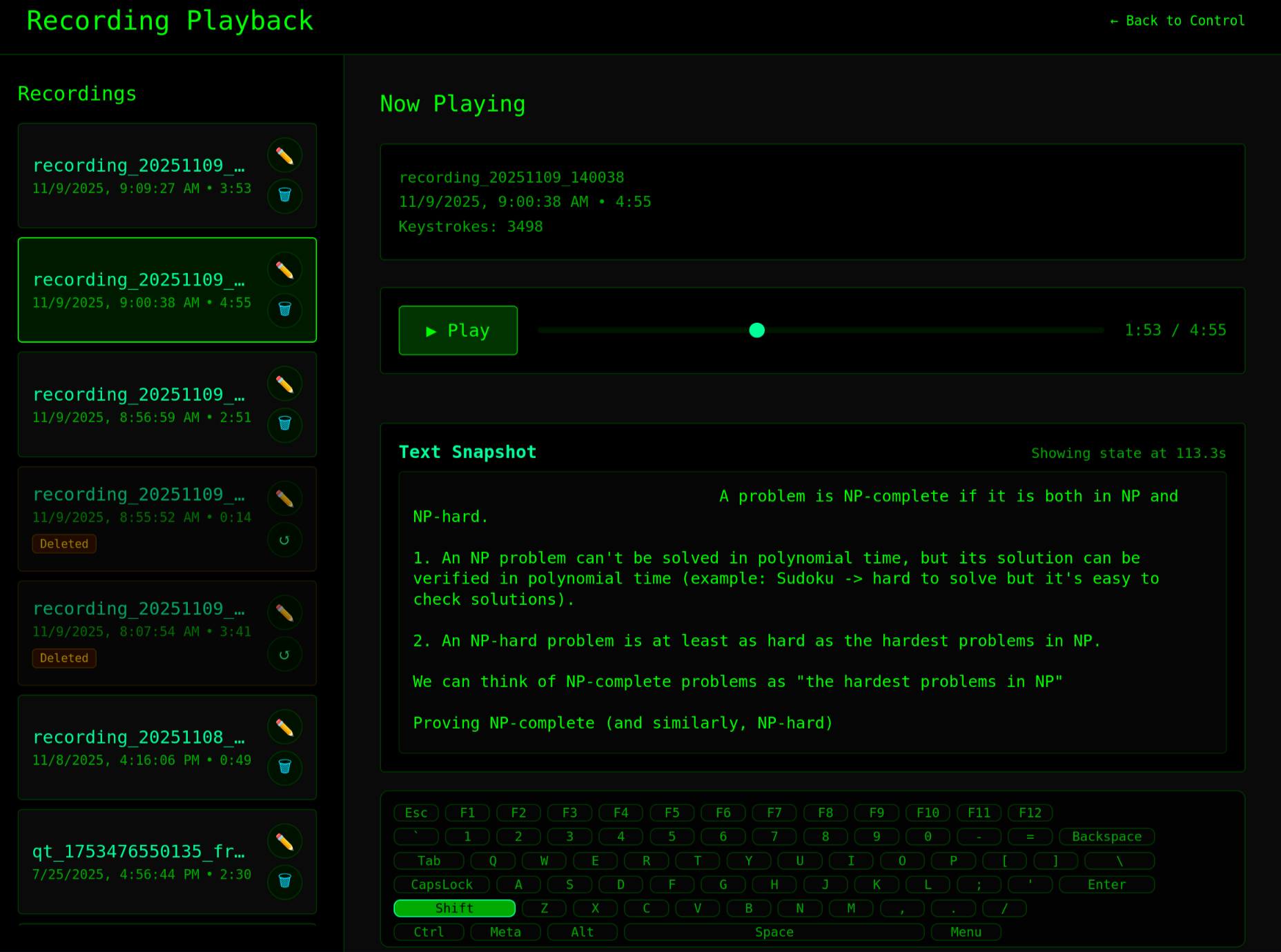
Recording Selection & Playback

Inspiration
There's a lot of existing research on acoustic sidechannel attacks but there are not really any actually practical implementations since they rely on specific keyboards or specific typing styles. Transformer models generalize well so we thought it might have a chance at making sidechannel attacks actually practical.
What it does
Accoustic sidechannel attacks take recordings of keyboard sounds and try to guess what keys were pressed by the person typing. This project is essentially that, the goal being to record a speech-to-text transformer model to predict keystrokes given some auditory context.
How we built it
We used claude-code and codex to help build a specification for a platform that enables collecting and inspecting audio and keystroke logs. We then followed a tutorial and used AI to build and implement a LoRA (Low-Rank Adaptation) of OpenAI's Whisper model on the collected data as well as a public dataset we found.
Challenges we ran into
We didn't look into the specific variants of key event types that could be received in a browser and ended up recording key text (which includes modifier keys) instead of the simpler and more close to reality key events.
We also had trouble figuring out how to finetune the model with all the various cloud services and tokenization schemes.
Accomplishments that we're proud of
We managed to build the platform to collect the data, including a beautifully animated playback of keypresses.
What we learned
- Our team learned how to vibe code via detailed specification + iterative refinement.
- We learned a lot about how AIs are trained, specifically whisper and the
transformerslibrary. - We learned about GPU providers and their various pros and cons.
What's next for KASCAesque: ASR-based Keyboard Acoustic SideChannel Attack
If it does work with more data, we are going to try to make it into an app that anyone can use! (So that people stop using passwords and get better keyboards).
Built With
- fly.io
- python
- pytorch
- svelte
- svelte5
- sveltekit
- typescript
- whisper

Log in or sign up for Devpost to join the conversation.