-
-

Karaka Reasoning-enabled-Knowledge Graph-RAG powered Agent
-
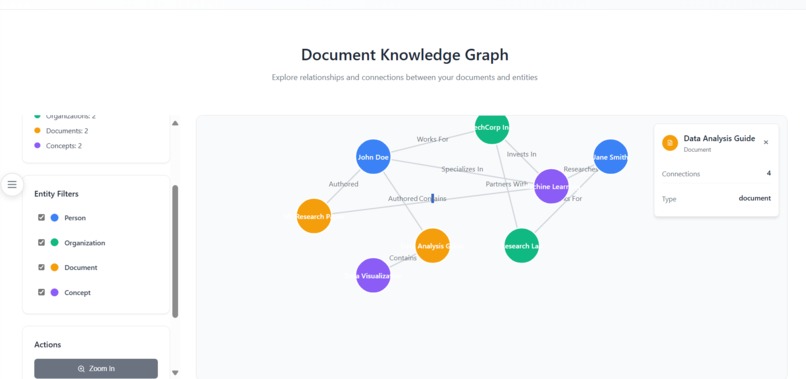
Knowledge Graph React UI with RAG Agent hosted on AWS with NvidiaNIM

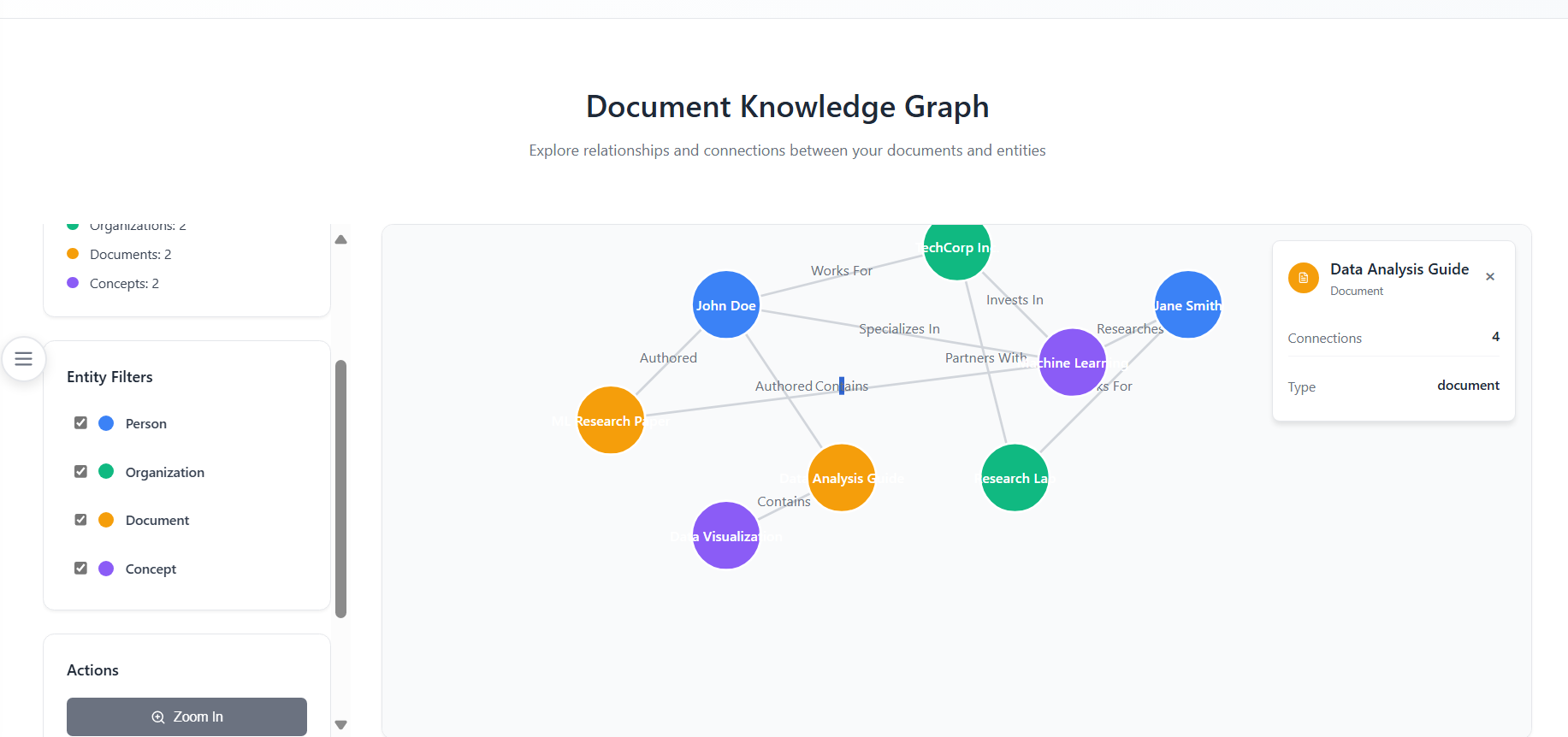
Kāraka NexusGraph
Inspiration
Traditional Retrieval-Augmented Generation (RAG) is noisy. It retrieves text based on keywords, not semantic meaning. This forces the LLM to parse unstructured text, leading to factual hallucinations.
Our inspiration is Pāṇini's Kāraka theory, a 2,500-year-old Sanskrit grammar framework. Kāraka defines the deep semantic roles in a sentence (who, what, where, why). We use this ancient logic to build a modern AI that retrieves structured facts, not just text.
What It Does
Kāraka NexusGraph is an agentic AI application that ingests unstructured documents and transforms them into a deterministic Kāraka knowledge graph.
When a user asks a question, our system retrieves structured, citable facts from this graph. This provides the LLM with verifiable evidence, eliminating hallucinations and enabling precise answers.
Traditional RAG retrieves: "A paragraph mentioning 'NIH' and 'replicated'." Kāraka RAG retrieves:
- Event:
replicated - Agent (Who):
Maria Santos - Object (What):
findings - Source:
(doc1:s3)
How We Built It
We built a cloud-native agentic system on AWS, deployed via the AWS CDK (Python).
- AI Inference: NVIDIA NIM microservices (
Llama-3.1-Nano-8BandNV-EmbedQA) run on an AWS EKS cluster withg5.xlargeGPU nodes. - Agentic Pipeline: An AWS Step Functions state machine orchestrates 18 AWS Lambda functions (Python 3.12). These agents handle document validation, Kāraka extraction, and graph construction.
- Storage: We use AWS S3 for documents and graph files, and AWS DynamoDB for tracking job status and metadata.
- API: An AWS API Gateway provides REST endpoints for the React frontend.
Challenges We Ran Into
The primary challenge was building a reliable agentic pipeline to translate natural language sentences into their correct Kāraka semantic roles. This required extensive prompt engineering and an iterative validation loop, orchestrated by Step Functions, where an "auditor" LLM agent checks the work of the "extractor" agent.
Deploying and managing GPU-enabled NVIDIA NIM microservices on EKS using the AWS CDK also presented a steep learning curve.
Accomplishments We're Proud Of
We successfully built a complete, end-to-end system that demonstrates a novel solution to LLM hallucination. We are proud of integrating ancient linguistic theory with a modern, scalable cloud architecture (EKS + Serverless). Our agentic pipeline, with its parallel processing and iterative validation, is a robust framework for deterministic knowledge extraction.
What We Learned
We learned that the key to reducing AI hallucination is not just better models, but better data representation. By structuring information as a knowledge graph based on semantic roles, we provide verifiable, factual context that LLMs can use reliably.
We also gained deep experience in production-grade GenAI architecture, combining NVIDIA NIM inference with the scalability and management of AWS EKS, Step Functions, and Lambda.
What's Next
Future work will focus on expanding the graph's capabilities to include multi-hop reasoning across documents, temporal event sequencing, and coreference resolution. The long-term vision is to build a fully autonomous research agent capable of synthesizing novel insights from a vast corpus of Kāraka-indexed knowledge.
Built With
- amazon-web-services
- knowledge-grapgh
- llama
- nim
- nvidia
- python
- rag
- react
- reasoningmodel

Log in or sign up for Devpost to join the conversation.