-
-
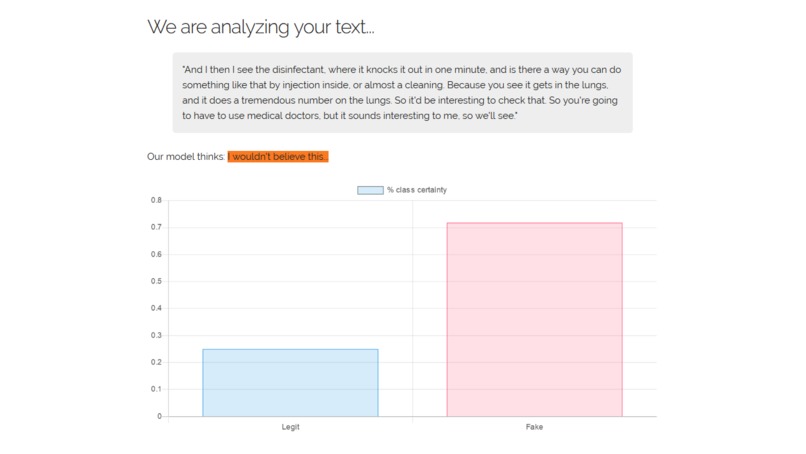
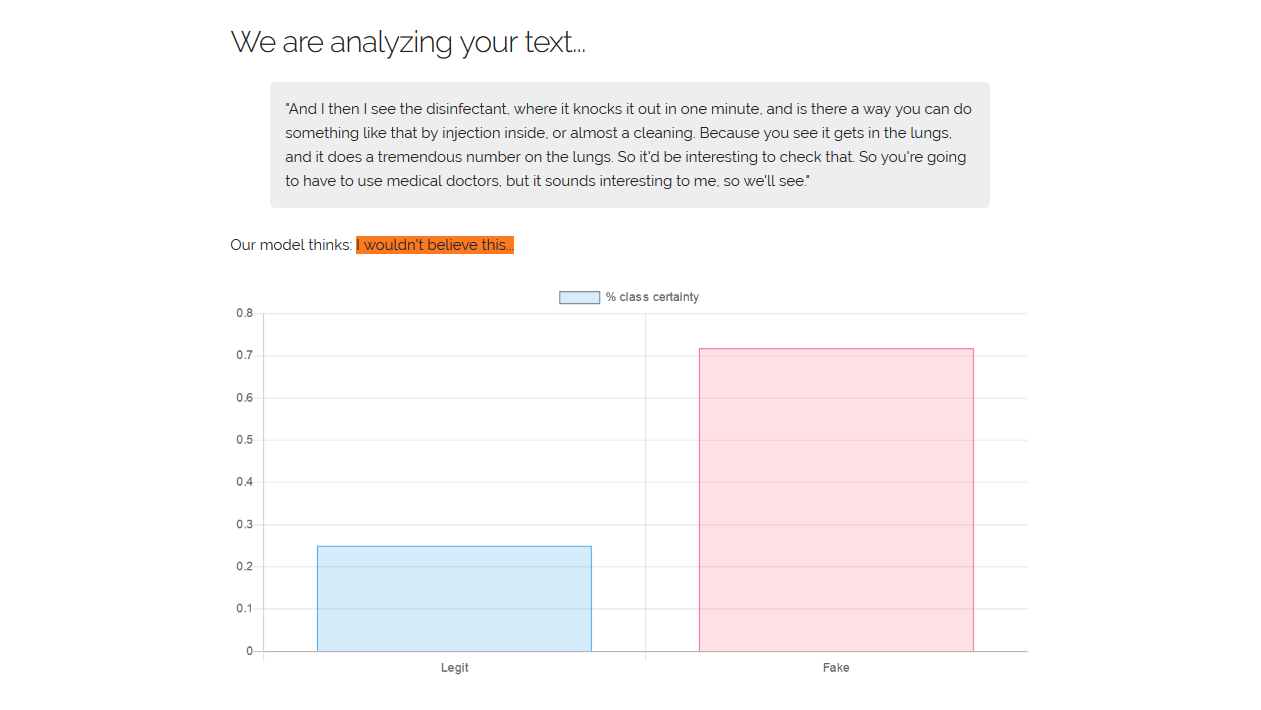
An example for a questionable fact
-
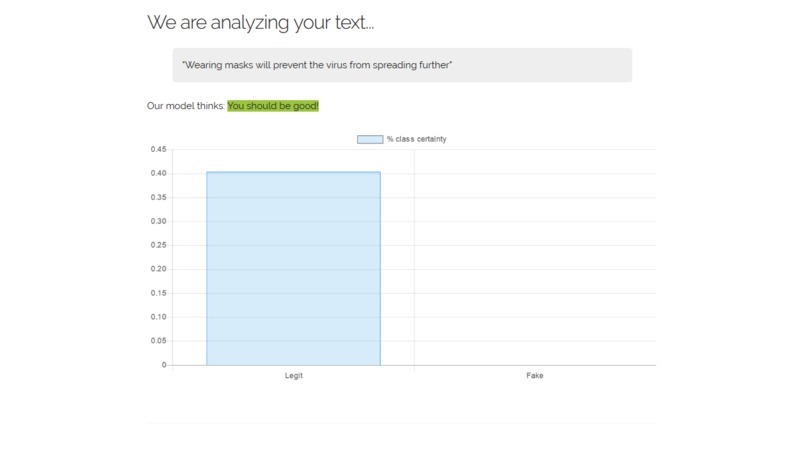
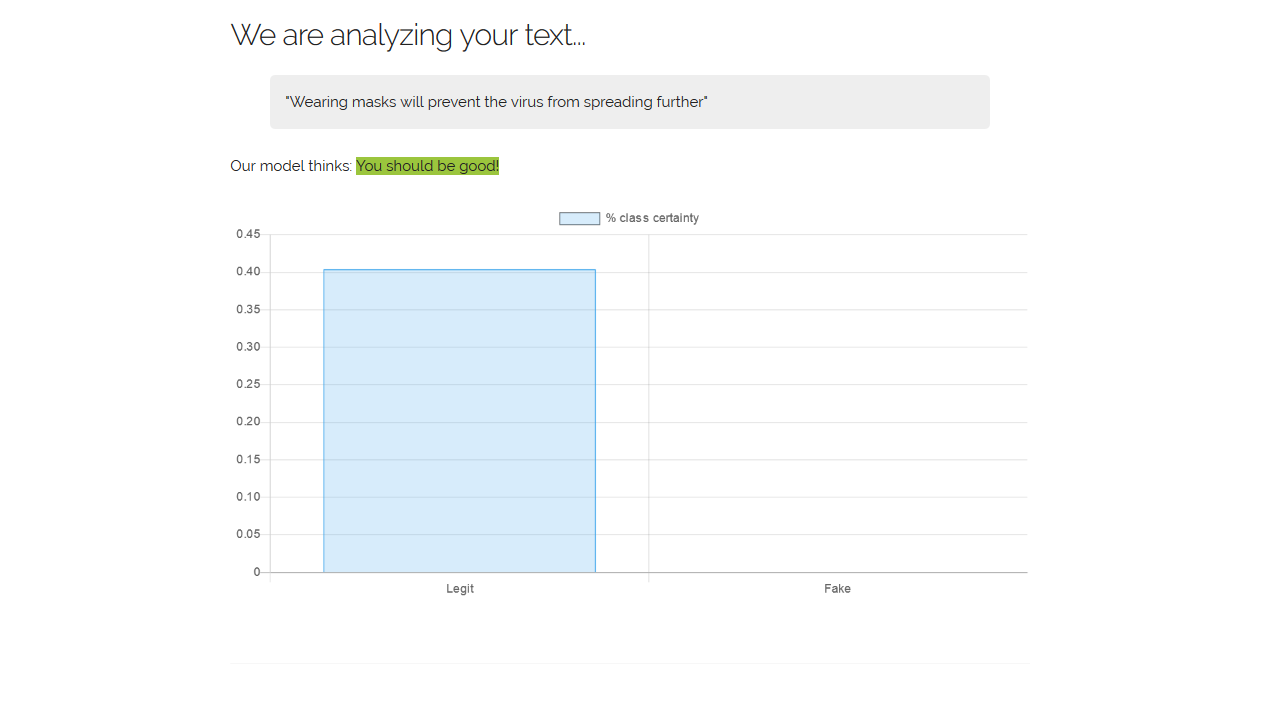
An example for a trustworthy fact
-

Made with love by the Friends of Kalman

Motivation
With thousands of news articles posted every day on the COVID-19 pandemic, it has become impossible for humans to inspect all of them for veracity. Fake news articles often aim to incite socio-political tension and can become a threat to democratic communities. Therefore, we felt the urgency to develop an automatic tool for fake news filtering.
What it does
Building on an initial assumption that the majority of fake news articles use similar writing patterns and buzz-words, we develop a machine-learning based approach with a neural classifier to distinguish between trustworthy and fake articles. Our webserver takes the entire text of the article as input and then tells you whether it appears to be real or fake after running our checker. To do this, we first amass a fake news dataset with 30000+ articles that are verified as either trustworthy or fake, by combining previously published news classification datasets. We then process the data with GloVe, a pre-trained word embedding for distributed word representation, and then feed the vectorized articles to a neural classifier. Based on our current training and testing efforts, our model can accurately detect the truth or falsity of articles ~80% of the time.
How we built it
We combined three publicly available datasets:
- Fake News: Kaggle dataset
- Liar: a benchmark dataset for fake news detection
- Buzzfeed Political News Data & Random Political News Data
Each of the dataset entries is first preprocessed and then used for training a deep neural network classifier. The preprocessing consists of tokenization with Keras and vectorization with the GloVe word embedding. The neural network classifier consists of an LSTM and 2 fully connected layers. It outputs a probability to which the input can be considered fake.
After training the network, it is used to classify the text that can be entered by users to evaluate through our website.
What we achieved during the EUvsVirus Hackathon
We’re proud to say that we started and deployed this project from scratch throughout the hackathon. From brainstorming our neural network architecture to setting up our website, it is all made with love by the Friends of Kalman.
Mainly, the workload can be summarized as:
- Literature research and data collection
- Generation of a joint dataset based on three datasets listed above
- Prototyping and implementation of multiple neural-networks architectures
- Development of an apache + flask webserver
- Deployment of the project to the webserver
Our solution’s impact on the crisis
First of all, our solution raises awareness about the fact that misinformation is a serious problem during the COVID-19 pandemic. By creating a simple tool for inspecting claims or articles, we motivate everyone to check questionable facts before sharing them with others. As the technology behind it is an artificial intelligence, it can further improve and refine its prediction with every text that is checked.
What's next for Kalman Fake News Filter
We want to experiment with a more sophisticated classifier, namely the transformer-based model BERT. As setting up and this model takes significantly longer than the architecture we deployed, we could not integrate it before the deadline. We are eager to continue working on this project, so a comparison between models will be one of the next steps.
Moreover, we would like to make the “magic” of neural networks more intuitively understandable. For this, we will experiment with different types of visualization for the classifier and explore different ways to make our model more explainable. Further, it would be interesting to explore what the networks learned, aka which general patterns appear to be consistent for “fake news”. This could help with understanding the key characteristics of “fake news” and thus allow for easier identification of these on sight.
Finally, our AI is not perfect, therefore we will try to combine our tool with fact-checking websites, where every information is reviewed manually. We believe that a hybrid model with human expert knowledge and the prediction of an artificial intelligence will deliver the best results overall. The website can use the hand-checked facts (that we know are true) and make inferences on facts that have not yet been checked due to the massive amount of information published every day.









Log in or sign up for Devpost to join the conversation.