-
-
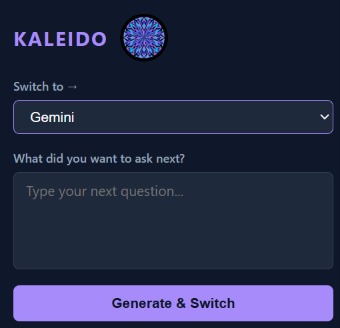
The main popup window of Kaleido
Inspiration
Kaleido was inspired by a frustration every free-tier LLM user runs into: you're mid-conversation, deep into a complex problem, and you hit the rate limit. You're forced to manually reconstruct your entire context in a new chat on a different platform, which is tedious and breaks your flow. I noticed that while LLM switching is increasingly common as users juggle ChatGPT, Gemini, Claude, and more, there was no tooling that made it seamless. I wanted to eliminate that friction entirely, without relying on another LLM to do it.
What it does
Kaleido is a Chrome extension that lets you instantly migrate an active LLM conversation to a different platform with one click. When you're on ChatGPT, Gemini, Claude, or Copilot, Kaleido scrapes your current chat directly from the DOM, runs a lightweight classical NLP pipeline locally to extract key entities, constraints, code artifacts, and recent exchanges, and then opens your target LLM in a new tab with a structured handoff prompt already filled in. You just type your next question and go. The same underlying pipeline has applications well beyond switching. It can compress long conversations into minimal context summaries before hitting a limit, strip redundant exchanges to reduce token usage in paid tiers, or automatically identify the most information-dense parts of a chat for documentation or note-taking. The entire thing runs in the browser with no external API calls and no LLM involvement, keeping it fast, private, and free.
How we built it
I built Kaleido as a lightweight Google Chrome extension using Manifest V3. The extension is written in vanilla HTML, CSS, and JavaScript, keeping it highly performant and secure.
The core of the project is a custom scraping engine. It uses specialized selectors to parse chat history on ChatGPT, Gemini, Claude, Grok, DeepSeek, Perplexity, and Copilot. I built a two-pass filter that cleans the DOM, removes active text inputs, and structures user and assistant turns.
Instead of using an external LLM to summarize the conversation, which would require API keys and be EXTREMELY expensive and slow, I engineered a classical NLP pipeline that runs locally in the browser in milliseconds. It uses a recency-weighted TF-IDF algorithm (which assigns higher importance to more recent messages in the exchange) combined with RAKE (Rapid Automatic Keyword Extraction) to identify key entities. It also utilizes a multi-pattern regex scanner to extract camelCase, PascalCase, snake_case code symbols, uppercase constants, and filenames. To extract user-defined constraints, it runs sentences through a local Naive Bayes classifier pre-trained on a custom supervision set.
To keep the new prompt to be sent to the LLM compact, I wrote a block-level parser that splits the AI text and truncates it. It utilizes formatting heuristics to auto-detect and preserve code blocks, tables, lists, key-value properties, and article/essay paragraphs. Finally, my injector script targets the input elements of the destination LLMs, and pastes in the prompt, ready for the user to send.
Challenges we ran into
Building a robust scraper across seven distinct platforms was a major challenge. The chat DOMs are heavily nested, obfuscated, and change frequently. I ran into bugs where parent containers were excluded because they contained editing fields or tooltip overlays. I solved this by separating my DOM filtering into two distinct passes: one to validate the viability of the element and another to filter out any child elements whose parent containers were already captured.
Secondly, standard text truncation kept ruining formatted text. When I initially truncated prompts, it cut out crucial lines of essays, lists, and code blocks. I had to build a layout-aware analyzer. It scans blocks for structural patterns, checking line lengths, list prefixes, punctuation consistency, among many other patterns, to ensure that structured text is always preserved at full length while standard explanatory text is kept compact.
Accomplishments that we're proud of
I am proud of creating a fast context-handoff system that runs completely locally in the browser. It does not make any external API calls, meaning user conversations remain entirely private.
I successfully built a unified scraping and injection system that operates across seven of the most popular LLM interfaces. The extension handles their distinct layouts and complex input editors seamlessly.
I am also proud of the accuracy of my text preserver and constraint extractor. By combining several computational linguistics approaches, including recency-weighted TF-IDF, RAKE, and a Naive Bayes classifier, it keeps important articles, code, tables, and key-value configurations fully intact, while still successfully shrinking the overall prompt size so it stays smaller than the original conversation.
What we learned
On the NLP side, I realized how much text processing and summarization can be achieved using classical, statistical methods. By using RAKE, TF-IDF, and Naive Bayes classifiers, I obtained high-quality, structured summaries without the overhead of heavy machine learning models.
What's next for Kaleido
First, I want to add support for file attachments. If a user uploads a PDF, text file, or image in their original session, I want Kaleido to automatically extract that data and port it over to the new LLM tab.
Secondly, I want to integrate support for local LLMs, enabling users to swap their conversations seamlessly to self-hosted models running via Ollama or the like.
Built With
- chrome
- css3
- google-storage
- html5
- javascript
- manifestv3
- naivebayesclassifer
- natural-language-processing
- rake
- tf-idf
Log in or sign up for Devpost to join the conversation.