-
-
About
-
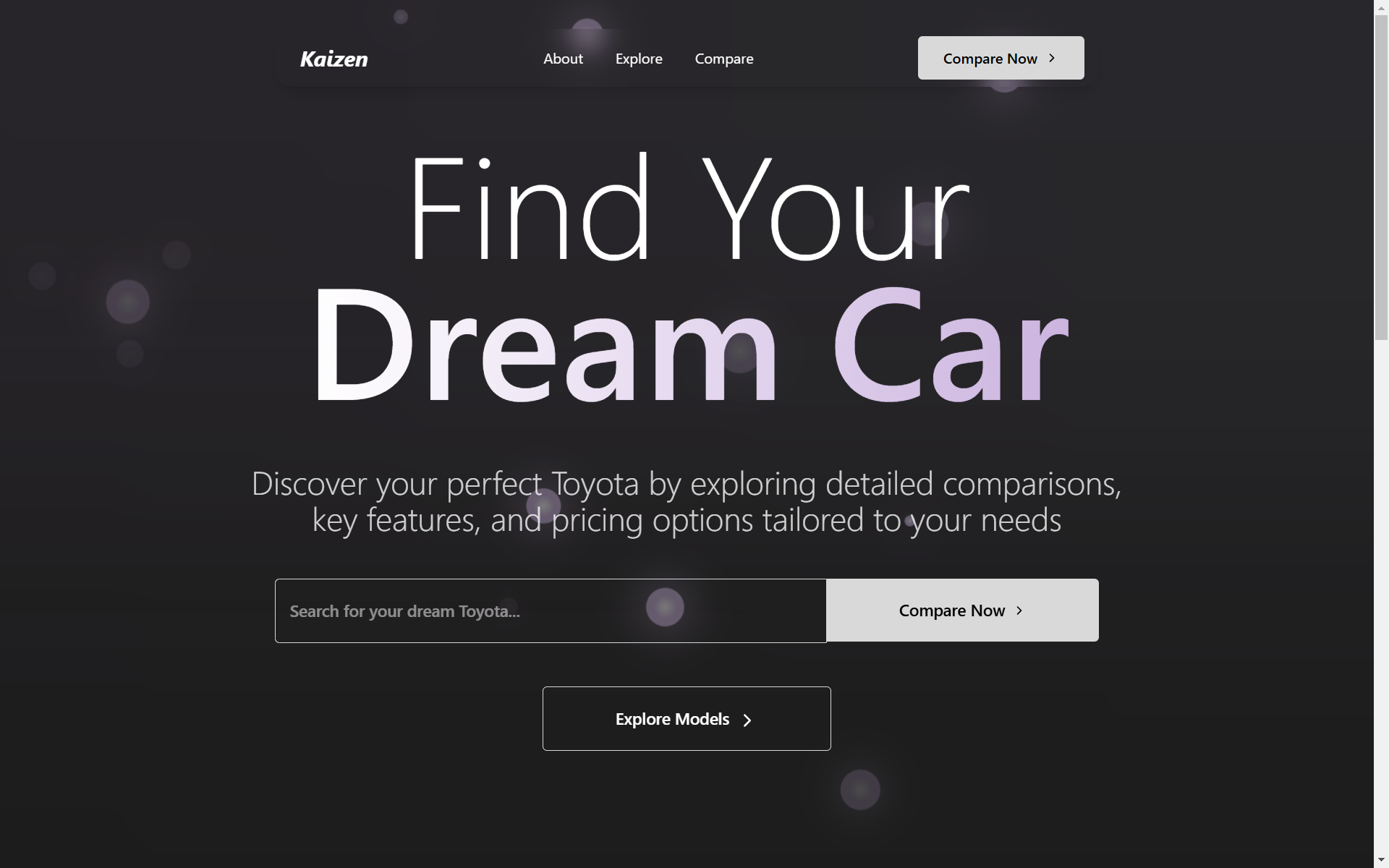
Landing
-
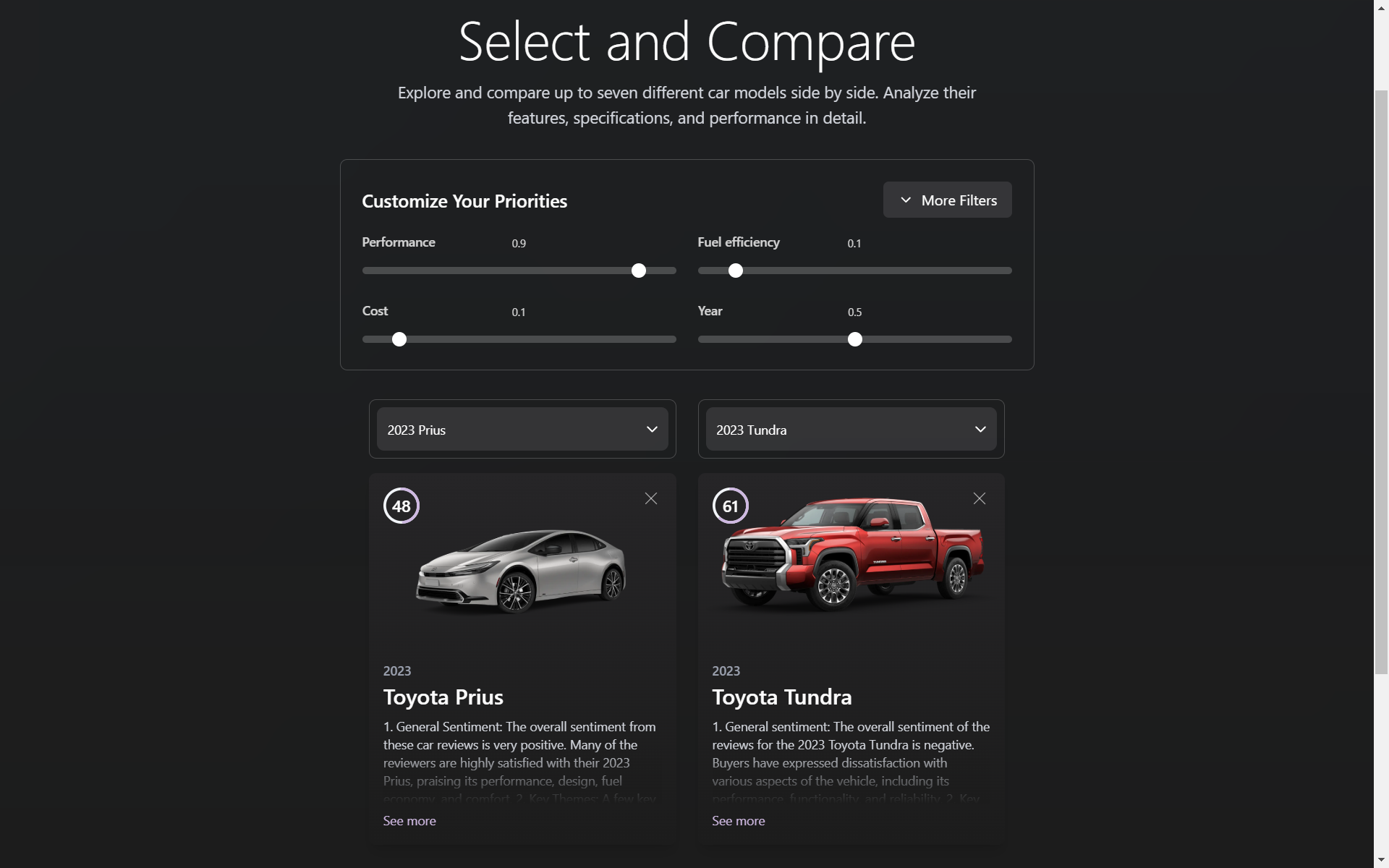
Compare
-
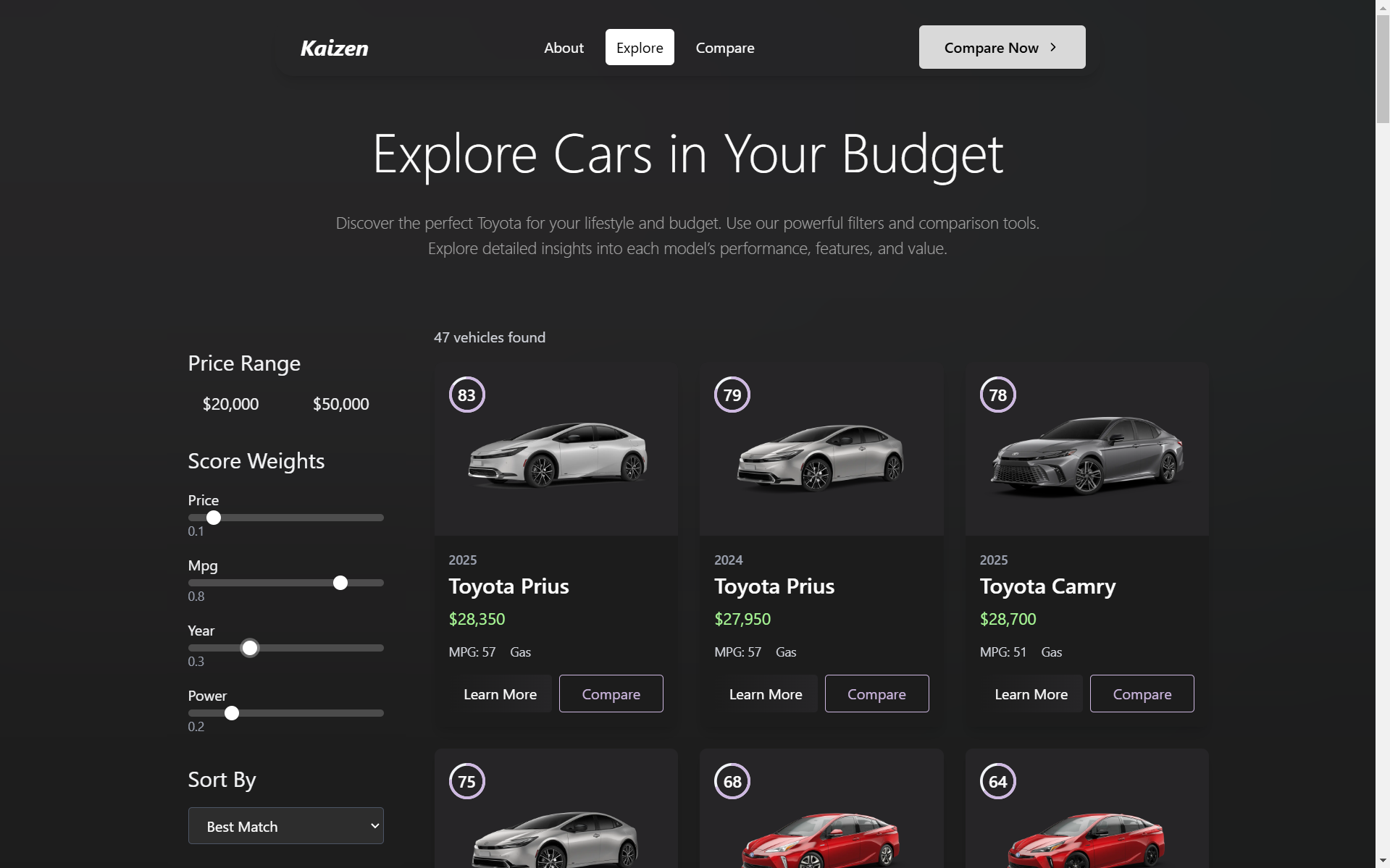
Explore
Inspiration
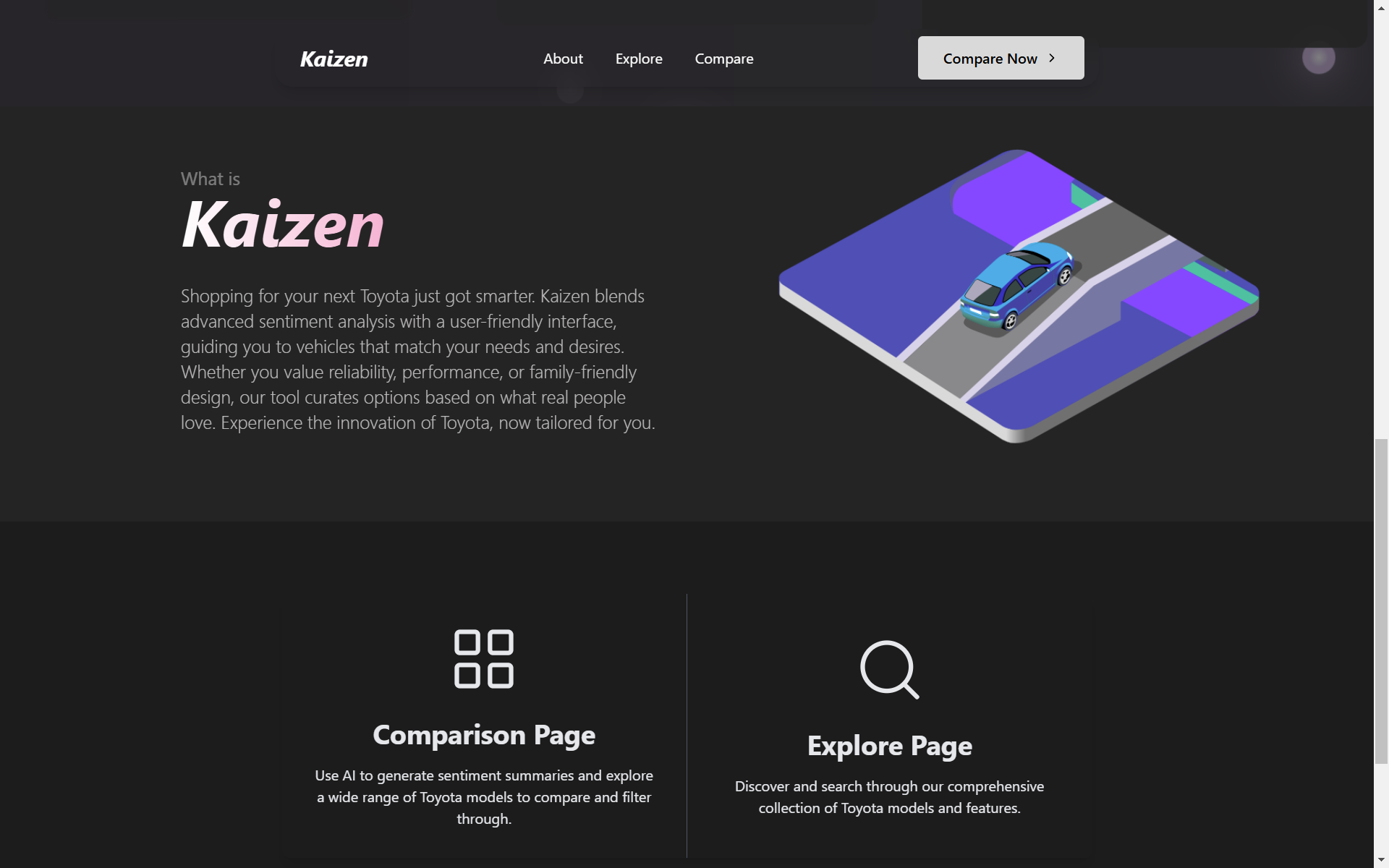
Kaizen, a motto at Toyota, translates to “incremental change.” The philosophy behind it is that the accumulation of small improvements can have lasting impacts. Named after this, our project incorporates a plethora of fine tuned improvements in order to streamline the decision making process of consumers when selecting a vehicle. Modern day cars have well over 100 different features to track, turning shopping into an uncertain guessing game. Some shoppers care about having a mighty powerhouse, while others want to maximize speed, and some just want the most reliable option to get from point A to point B. Sifting through Toyota’s massive catalog of cars can be cumbersome; Kaizen serves as an informative first step to understanding which vehicle aligns best with a consumer’s unique preferences and needs.
What it does
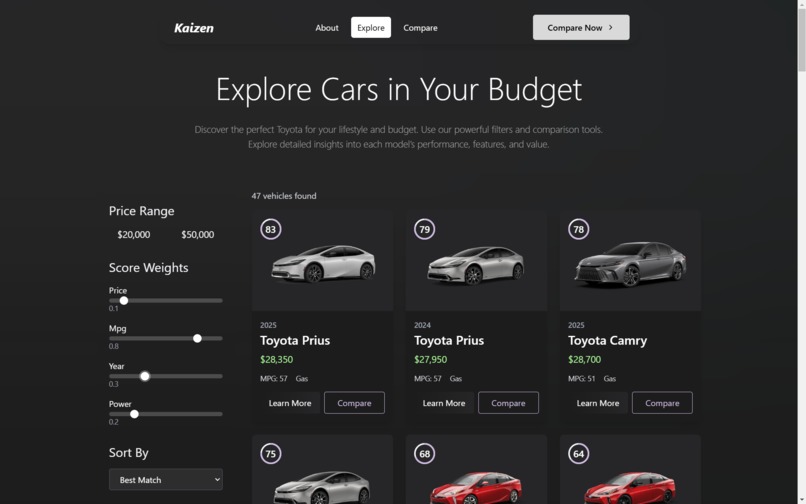
We built a platform that aggregates review data and specifications from many different websites and presents it in an easily digestible format that can be tailored to user preferences.
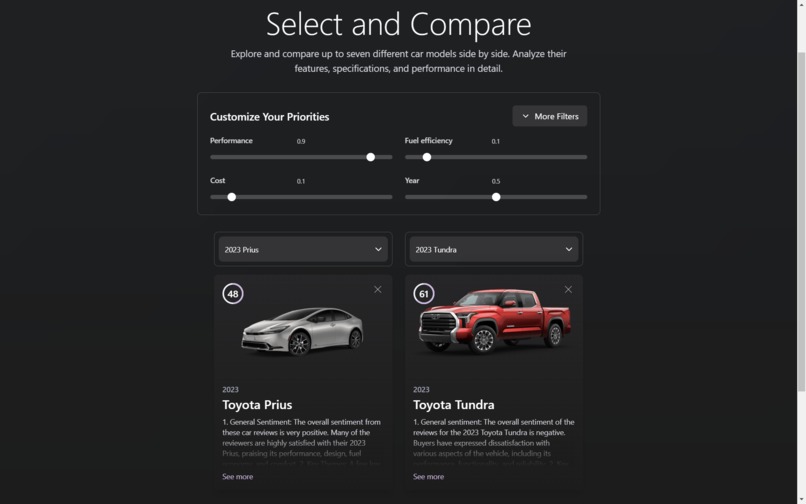
Using quantitative statistics, we created a scoring system made up of a weighted sum of specifications which we then used to easily and fairly rank the vehicles. The weights of each metric can be specified by the user depending on their own preferences (e.g horsepower weighted over milage (mpg) for those preferring heavier workloads).
For more qualitative/subjective reviews, we decided to use an LLM to summarize user reviews, highlighting key themes and general sentiment. Many of the major qualities of a car that affect user experience won’t be highlighted in statistics alone, so we wanted to provide a balanced and unbiased review that also didn’t compromise convenience.
In combining both quantitative and qualitative statistics in an easily digestible format, we strived to create a platform that can help customers gain valuable information and provide them with resources to learn more without overloading them with unnecessary statistics.
How we built it
Arize Phoenix
Langchain
def setup_components
"""Initialize all system components with proper tracing"""
def setup_conversational_chain
"""Setup the conversational chain with memory"""
def format_chat_history
"""Format chat history into a readable string"""
def chat
"""Have a conversation with the system about the documents"""
(This is the one that allows you to query with the actual openai api)
Tracing
def retrieve_similar
"""Retrieve similar documents with proper tracing"""
def process_and_refine
"""Process and refine texts with proper tracing"""
def load_documents
"""Load documents from a file or directory and create vector store"""
def search_reviews
"""Search for relevant reviews in the vector store"""
(Transition to evaluation)
Evaluation
def analyze_categoryReviewAnalysis:
Along the way, I accidentally took the harder route and was writing my own custom eval functions for hallucination and qa/correctness.
def evaluate_hallucinations(df, model):
def evaluate_correctness(df, model):
(The full length overwhelms this page, and thus will be left to your own to check on our github)
Guardrails
from guardrails import Guard
guard = Guard().use(
TwoWords(),
Backend
Web Scraping
The decision assistance pipeline begins with high quality vehicle data. We sourced our information from 3 primary sources: cars.com for specifications data, toyota.com for high quality images, and lastly Edmunds for plentiful consumer reviews. To obtain images from Toyota, we used dynamic URL parameterization. We then obtained our consumer review data and specifications from cars.com and edmunds using selenium and a browser client to circumvent bot guards. Finally, we compressed this data and serialized it by storing it in a pickle 🥒file to be easily accessed later.
Database and Storage
We used a PostgreSQL database hosted on a Docker container for portability and scalability, allowing us to efficiently manage and query large amounts of data. By using Docker, we ensured that our development environment remained consistent across different machines, reducing potential compatibility issues. The PostgreSQL database enabled us to store and organize user preferences, car specifications, and aggregated review data in a structured manner, ensuring fast and reliable data retrieval. This setup not only made our platform robust but also future-proof for further development and deployment.
API Endpoints
We used Flask to set up the backend API points. These API endpoints supplied the frontend with the information we processed and scraped from review and specification websites.
Frontend
Using figma to create preliminary mockups in order to hone our design. For the design we shot for an easy to navigate web app, streamlining the consumer experience as much as possible.
Challenges we ran into
Integration was definitely a big challenge because of the amount of different libraries and frameworks. Also, organization was a big issue because of 4 people working through the same repository.
Accomplishments that we're proud of
We were able to create a relatively polished product without many bugs, which for a hackathon, is a big accomplishment that we are proud of.
What we learned
Throughout the course of this project, we gained valuable insights into designing and implementing a full-stack application under time constraints. We learned how to effectively integrate various technologies, such as Docker for containerization, PostgreSQL for database management, and data aggregation techniques to streamline information processing.
Built With
- arize
- beutifulsoup
- flask
- nextjs
- openai
- postgresql
- selenium
- tailwindcss






Log in or sign up for Devpost to join the conversation.