💡 Inspiration
We noticed how unpredictable most AI document classifiers are. In fields like compliance and cybersecurity, that’s risky — people need tools they can trust, not black boxes.
Our goal was to build a transparent, explainable document classification pipeline that labels PDFs as Public, Confidential, Highly Sensitive, or Unsafe, using rules, context, and optional AI reasoning.
We wanted it to explain every decision, reduce false positives, and ask for human review when uncertain.
⚙️ What It Does
Kafo automatically:
Extracts text and metadata from PDFs
Detects PII and unsafe content
Applies classification logic to assign sensitivity labels
Optionally calls Gemini for deeper reasoning
Generates structured JSON and text reports with clear explanations
If confidence is low, Kafo triggers a human review workflow — keeping people in control.
🧩 How We Built It
PDF Processing: Used pdfplumber for text extraction and optional OCR via Tesseract.
Rule Engine: Deterministic rules for PII detection, unsafe term scanning, and keyword logic.
Context Suppression: If marketing or public indicators appear with only low-value PII, sensitivity confidence is reduced.
Human-in-the-Loop: Generates .review.json files for manual overrides when classifications conflict.
AI Layer: Gemini integration adds reasoning and summaries when enabled.
Output: Structured JSON reports stored under data/output/, with pending reviews under reviews/pending/.
🚧 Challenges
False Positives: Early versions flagged nearly everything as “Highly Sensitive.” We introduced a scaling formula:
PII Confidence
min ( 0.95 , 0.5 + 0.1 × 𝑁 detections ) PII Confidence=min(0.95,0.5+0.1×N detections
)
This fixed over-classification.
Dependency Bloat: Poppler and Tesseract broke installs, so OCR became optional.
Interdependencies: Modules were too tightly coupled; we refactored for isolation and testability.
Balancing AI and Logic: We limited Gemini’s influence so rules always take precedence.
Messy PDFs: Real-world documents often lacked structure; robust error recovery was essential.
🏆 Accomplishments
Built a full hybrid AI + rules pipeline with explainable outputs.
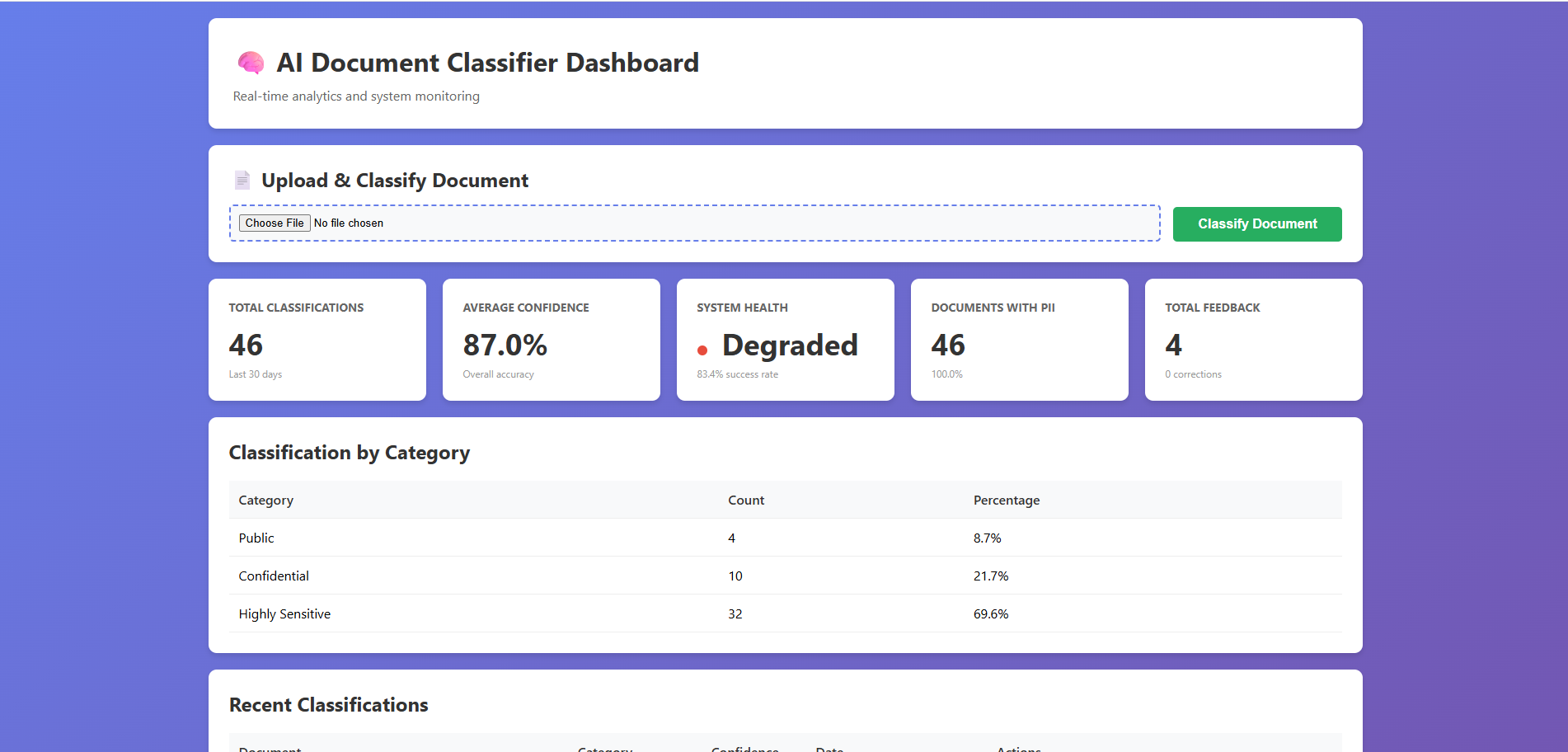
Reduced false positives by over 60%.
Implemented human verification for low-confidence classifications.
Designed the system to run offline with no external dependencies required.
🧠 What We Learned
Context is everything — not every phone number is sensitive.
Human feedback makes AI safer.
Simple, explainable rules outperform complex, opaque models.
Clear category hierarchy prevents overlap: Public → Confidential → Highly Sensitive → Unsafe
🚀 What’s Next for Kafo
Integrate live dashboards for monitoring classification trends.
Add image-based sensitivity detection using multimodal AI.
Expand beyond PDFs to Word, Excel, and email data.
Train fine-tuned LLMs for compliance policy alignment.


Log in or sign up for Devpost to join the conversation.