Inspiration
Boston’s K-Pop dance teams. Goal is to save time during the planning of K-Pop dance covers by visualizing and automatically parsing pre-existing dance formations so dance teams don't have to manually perform this process. Rather than using pre-existing applications like ArrangeUs and copy formations frame by frame, users can do it simply by uploading a dance practice video.
What it does
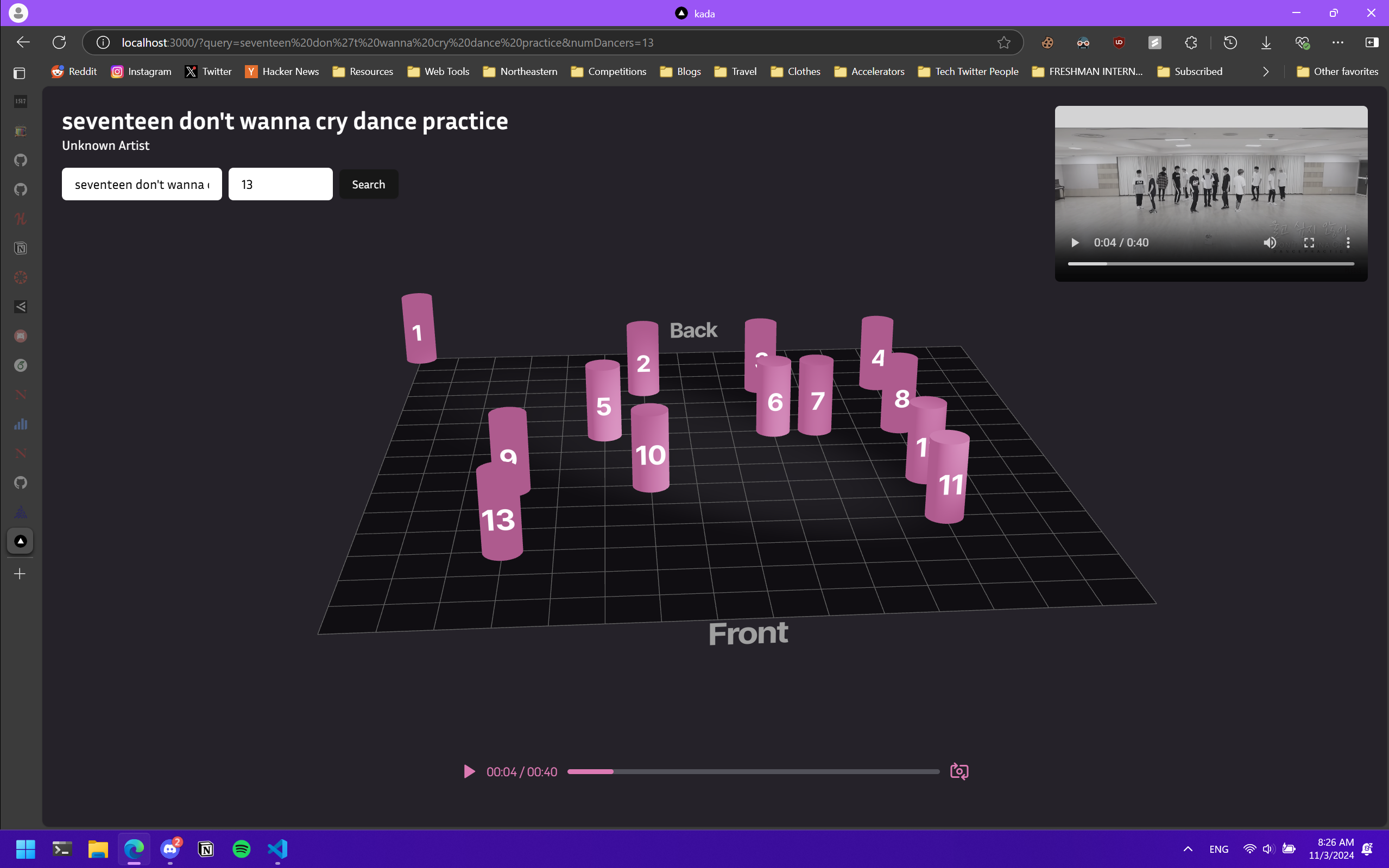
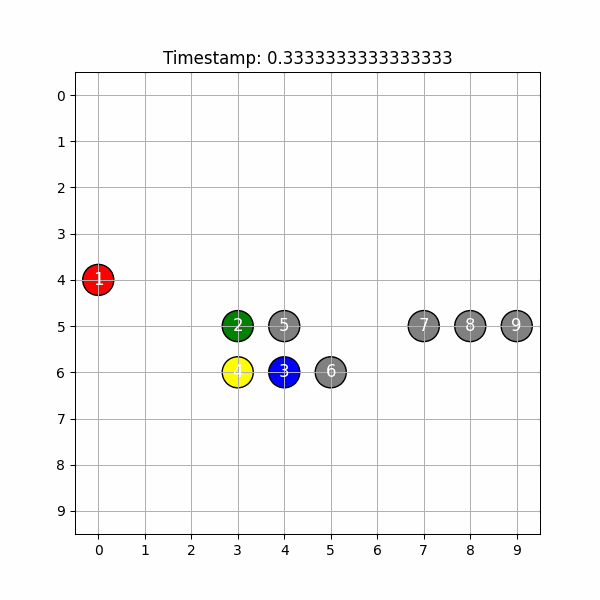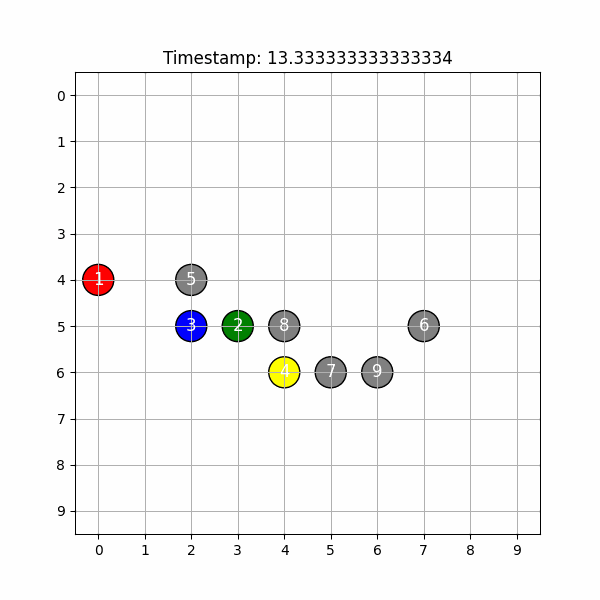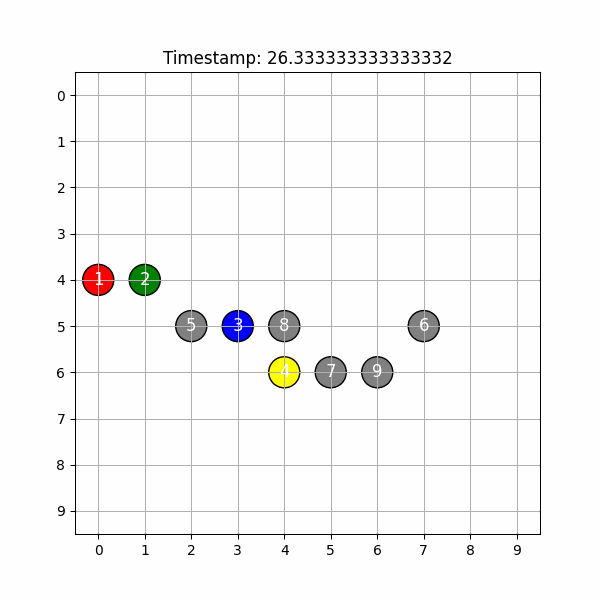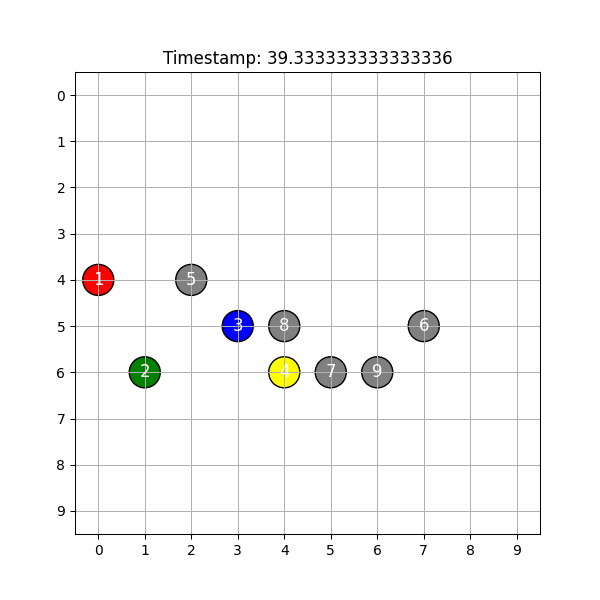
kada uses state-of-the-art computer vision models to analyze a dance practice video and create an easily accessible 2D and 3D visualization that’s suitable for dance practices.
How we built it
Backend We started with researching appropriate models and ended up with a three-model architecture combining depth perception (deep_sort), object tracking (yolov8), and facial recognition (deepface)..
Frontend We started with a mockup in Figma, then brought it to life with ThreeJS and Next.js.
Challenges we ran into
Even state-of-the-art depth models are, at the moment, limited in accuracy and cause nontrivial fluctuations in the dancers’ positions over time.
Accomplishments that we're proud of
Speed of processing: we went from taking 25 minutes to process a 2-minute video to just 30 seconds for a 2-minute video. Design: frontend is accessible and gives exactly the amount of information necessary
What we learned
Depth models are challenging to work with at the moment ThreeJS is fast and easy to use, especially when paired with frontend frameworks like React
Despite all the challenges that we faced, our solution is still faster than manually tracking dancer positions and nearly as accurate.




Log in or sign up for Devpost to join the conversation.