-
-
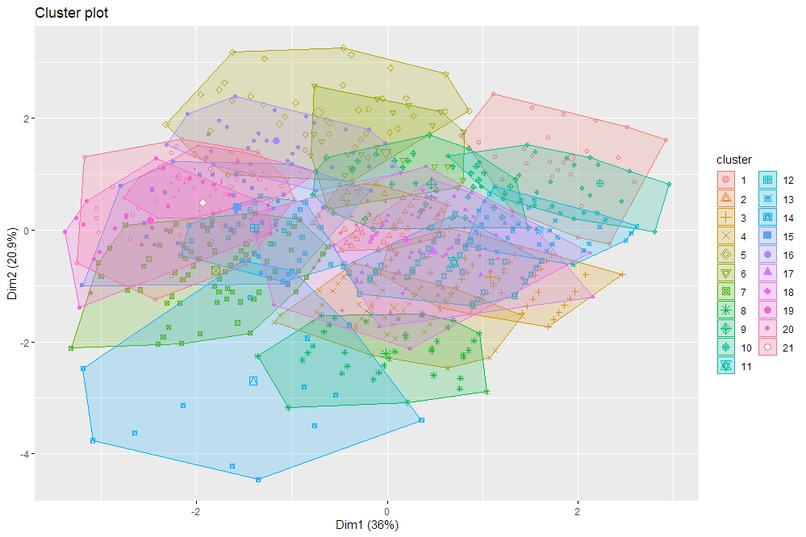
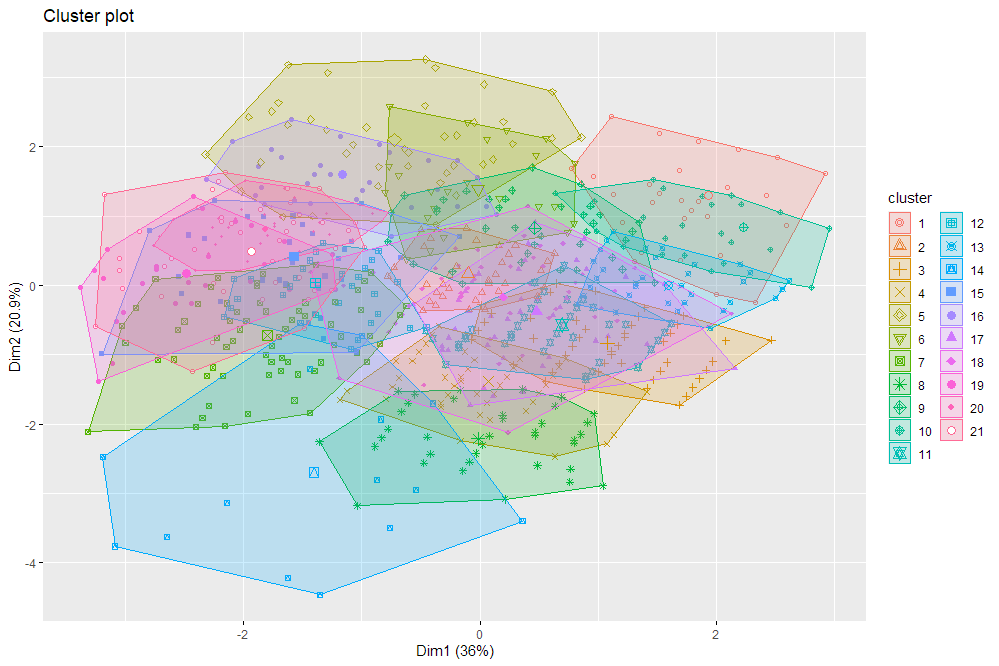
Visualization of the 21 clusters projected onto a 2D plane (axes determined through principal component analysis)
-
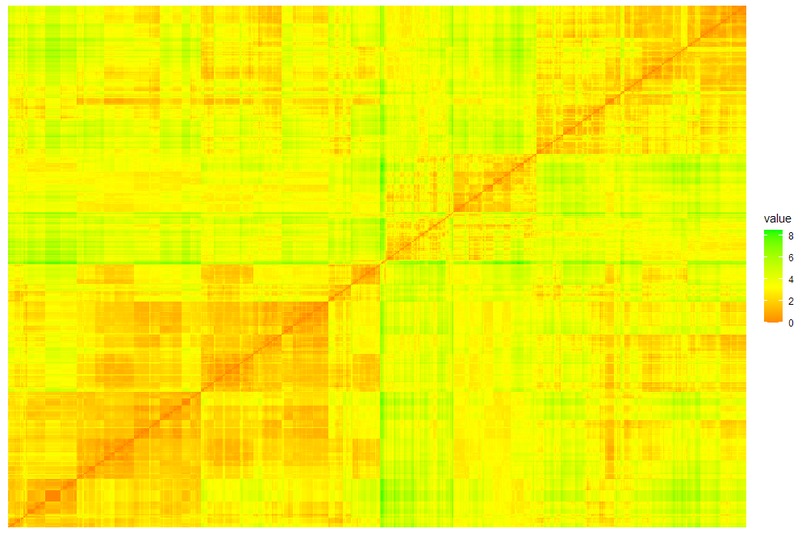
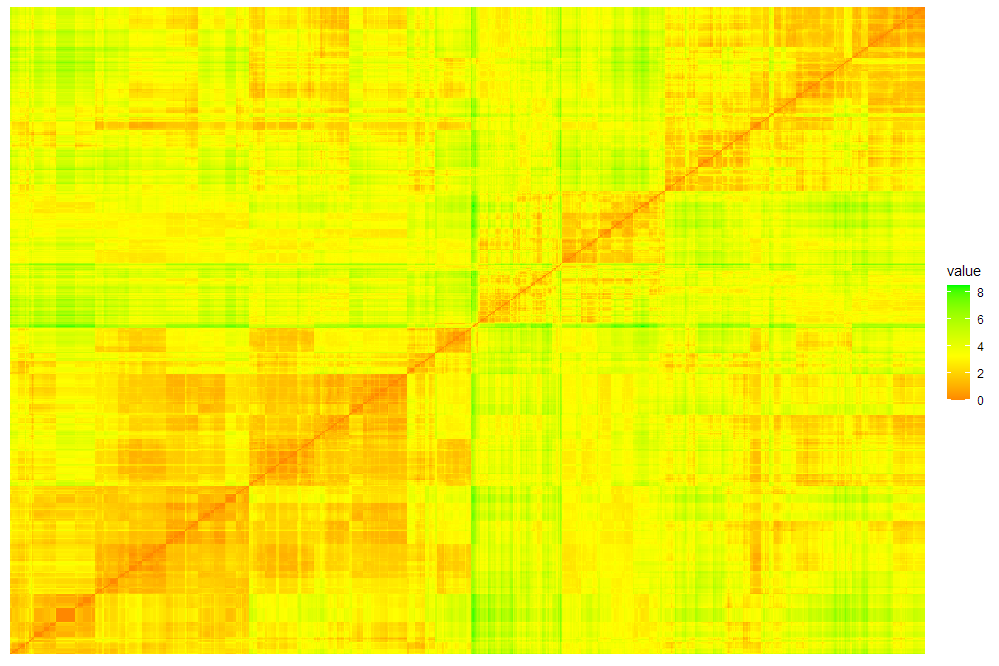
Plot of the euclidean distance function between every pair of users (red diagonal is the user with themself, hence a distance of 0)
Inspiration
Technical folk aren't always the best at meeting new people. So, our algorithm meets good teammates for them!
What it does
Clusters applicants to TAMU Datathon into groups based on similar technical/experience background
How I built it
We used a k-means clustering algorithm on a data matrix constructed by turning various categorical variables into ordered factors and computed with a euclidean norm.
Challenges I ran into
How to turn different variables into ordered factors to make sense of things like how a list of different skills might affect how we discretize their 'score' for that variable.
Accomplishments that I'm proud of
Our algorithm qualitatively performed very well at grouping applicants; pulling random people from the same clusters consistently resulted in groups that we felt were at a similar technical skill level / were generally similar applicants.
What I learned
This was all of our first hackathons/datathons! We learned a lot about clustering algorithms, the k mean clustering algorithm, and how to visualize different aspects of the model such as by plotting a projection of the clusters onto a 2D scale (determined through principal component analysis) since our analysis was in a dimension higher than 2.
What's next for K Mean Matchmaking
The k mean algorithm is not necessarily the best for this application; a hierarchical clustering algorithm could perform better / be more accurate but has a more complex implementation and sometimes slower runtime. Since this was our first project we wanted to keep it as functionally simple as possible while still delivering a strong result.
Built With
- r
- tidyverse







Log in or sign up for Devpost to join the conversation.