

Inspiration
I grew up in a place of constant economic decline. I watched the different policy makers, community activists, public administrators repeat the same mistakes and fall into a vicious cycle when it came to economic development. For the past 20 years, I have lived in Austin TX and have seen how a virtuous cycle can happen when economic and social development is focused, inclusive, and evolving. I wanted to use this challenge to look at social and economic development.
Target User
- Local community policy makers
- Public administrators
- Economic development officials
- Community NGOs
Data Sources
Data.gov is the front door to a collection of public data. I combined data from three different US federal government departments.
The first one is from the Treasury Department. The data is maintained by the Internal Revenue Service which collects migration data by tracking address from individual tax returns filed from one year to the next.
The second data set is from Health and Human Services. The mortality data is based on all death certificates filed in the United States. It is maintained by the National Center for Health Statistics.
The final data set is from the Department of Commerce. The American Community Survey is administered by the Census Bureau. It is an annual survey to track the characteristics of local communities. The data helps determine how $400 billion dollars of federal and state funds are distributed each year.
Exploratory Data Analysis
When I have data sets that I’m reviewing for the first time, I like to start with exploratory data analysis to see what’s inside. With the IRS migration data, I asked “What communities had the largest migration outflows? Looking at the outliers, two popped out. New Orleans in 2005, and Los Angeles from 2004 to 2007. Over 195 thousand people migrated out of New Orleans after Hurricane Katrina. But Los Angeles? And the total population outflows were 3 times that of New Orleans. “Where did they go?”
I used ggplot2 in R Studio to create graphs to understand overall migration over time and the Los Angeles migrations outflows.
Data Mashup
I combined the migrations data set with the mortality data set by county starting at 2004 and up to 2010 which is the latest data from the Internal Revenue Service. The death rate is calculated by combining the total homicide and suicide counts by the per thousand county population. This is one of the quality of life metrics used to rank the communities.
The mortality data set featured county data with a classification according to population size. I created box plots to look at the death rates by geographic classifications.
Up to now, this data looks at events in the past. How can you use it to make decisions for the future? The approach I used combines the death rate quality of life metric, together with the net migration flow, and ranks each of them on a percentile scale. I use those rankings and combined the data with the American Community Survey to understand the community’s characteristics.
App Data
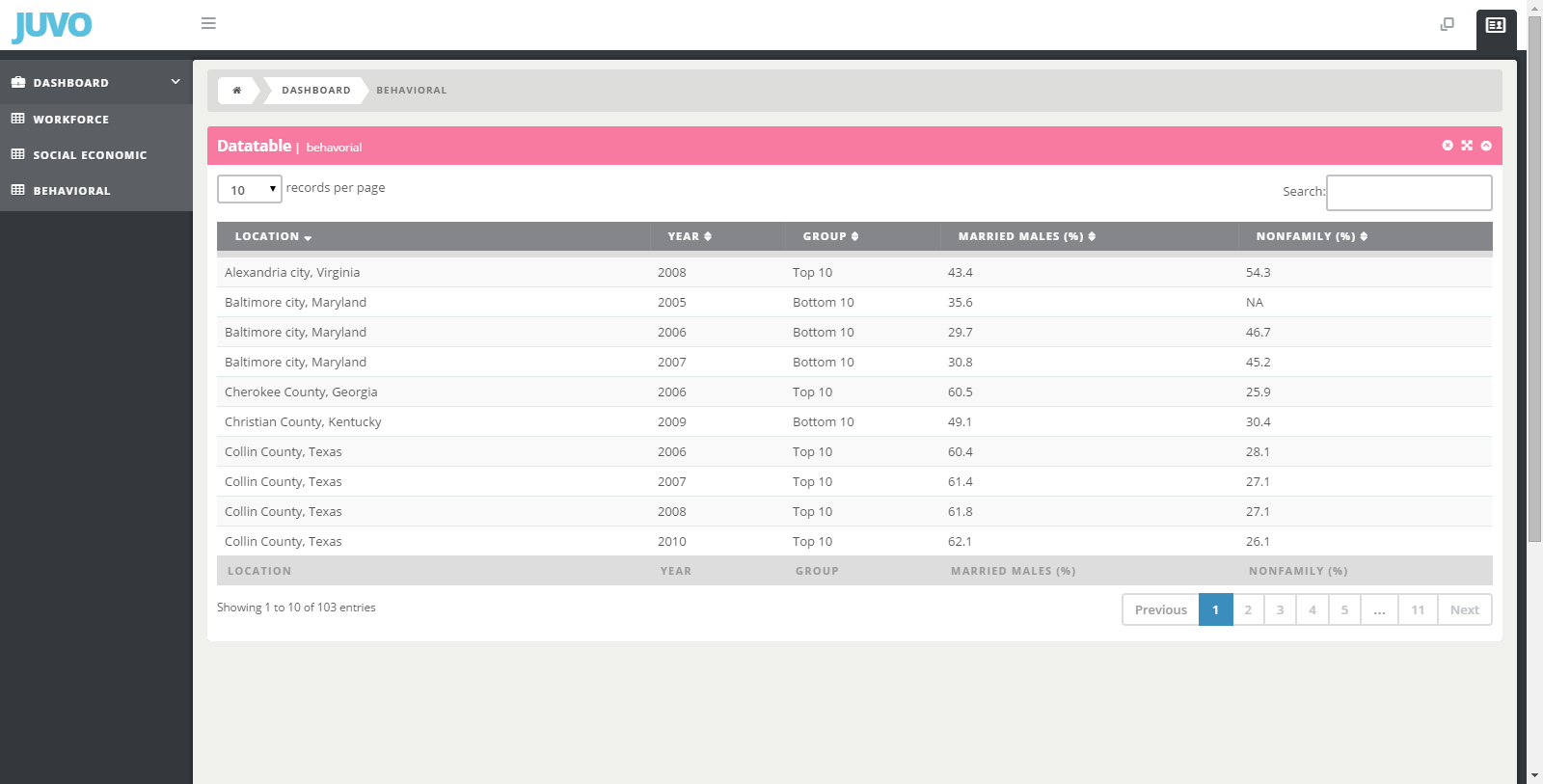
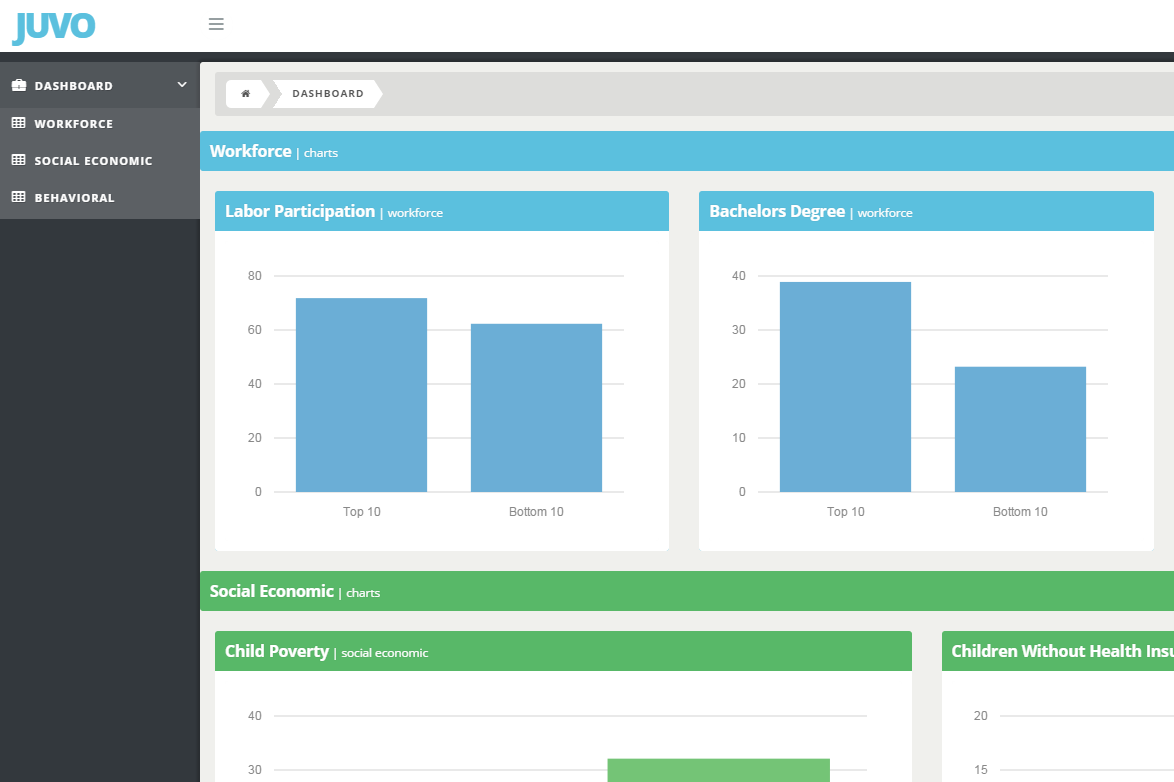
Using the American Community Survey data, I created three separate groups to present the results. These are Workforce, Social Economic, and Behavioral. The Workforce group characteristics are labor participation rate, the percent of people 25 and older with at least a bachelor’s degree, and the percent of people 18-64 receiving disability support. Social Economic included percent of children under 18 living below the poverty line, and the percent of children without health insurance. For the Behavioral, the characteristics are the percent of males 15 and older who are married, and the percent living in non-family households. Non-family households are residences where there are zero family members living together.
Within these characteristics, the data looks at the floor and ceiling metrics. These are the top and bottom 10 percentiles communities. The bottom 10 is the average of the communities with the highest homicide and suicide rates and the highest percentage of community migration outflows. The top 10 is the average of the communities with the lowest death rates and the highest percent of migration inflows.
App Description
The app is named Juvo, which is Latin for “to aid, assist”. Its goal is to aid and assist the target users for setting their social and economic development plans with realistic achievable goals and metrics to measure those goals.
The interactive app uses a dashboard style layout. It opens with with bar charts for each of the community characteristics. The categories are color coded. You can explore the data by category and sort it according to the characteristics through the data tables. The app was created with the Orb admin template. I used the javascript libraries Morris Charts and Datatables to build it.
Data Limitations
With every data set, you need to understand its limitations and how those limitations affect your analysis. In the mortality analysis data, only the counties with 10 or more combined homicides and suicides are reported due to privacy regulations.
The American Community survey is a sample of the population at a point in time. Many of the rural communities are excluded in the data sets because there is not enough people in those communities to come up with statistically valid sample estimates.
In my exploratory data analysis, the higher rural death rates appeared intriguing. However when you take into account the data imitations and the missing data around rural communities, the box plot which shows rural communities to have the highest death rates may be completely false.
Hadoop Process
“To what extent is this missing data affecting my analysis?” This is where IBM Analytics for Hadoop comes into play. My mortality analysis data is from the compressed mortality data set. The raw master mortality data is over one gigabyte with the personal and geographic data stripped. I used Big R to count the total number of homicides and suicides from the master mortality data set. I found 15 percent of these deaths excluded from my analysis data. I matched the geographic data with the master list of geographic codes to find 2172 communities excluded and 59 percent of them are rural. Now I have more insights into the data, including the key missing aspects.
Toolset
- R Studio
- R Libraries - dplyr, sqldf, ggplot2, jsonlite, bigr
- IBM Analytics for Hadoop on Bluemix
- Orb admin template
- javascript libraries - morris charts, datatables
- Vegas Pro 11, Figure app, and Screencastify chrome extension for video
Built With
- bigr
- bootstrap
- css
- datatables
- dplyr
- ggplot2
- html
- javascript
- morris-charts
- r
- r-studio
- sqldf


Log in or sign up for Devpost to join the conversation.