-
-
AI Outcome
-
Upload Page
-
Home Page
-
Cases
Submission Text
Inspiration
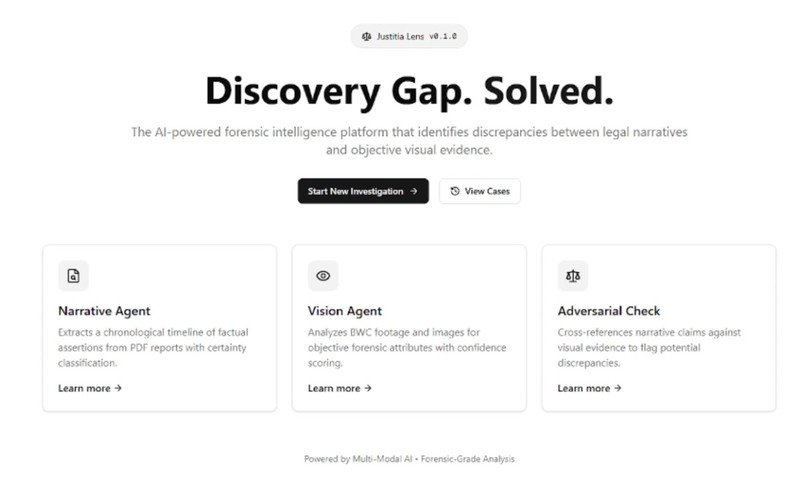
Every year, wrongful convictions happen partly because no one has time to review hundreds of hours of footage. We built Justitia Lens to fix that. Discrepancies between police reports and bodycam/photo evidence often go unnoticed due to the sheer volume of case material. Manual cross-verification is time-consuming and error-prone, delaying case review and increasing the risk of oversight. We saw an opportunity to use Multimodal AI as an objective second pair of eyes to help legal teams review evidence more efficiently. Justitia Lens is a multimodal AI pipeline that cross-references witness statements and police reports against bodycam and CCTV footage, automatically flagging discrepancies, timestamping every claim, and surfacing perjury in minutes instead of weeks.
What it does
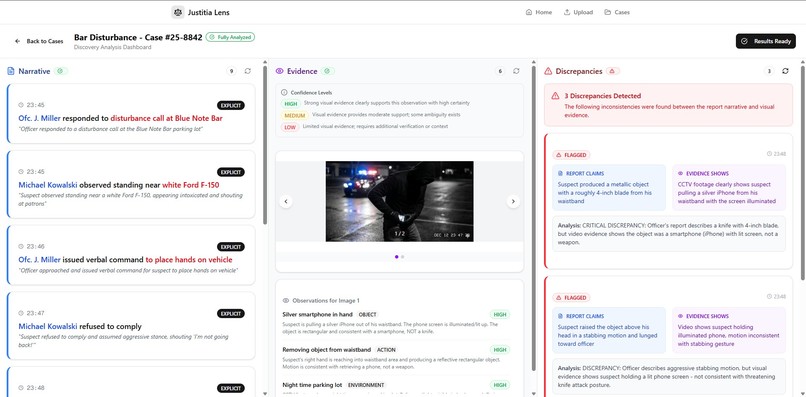
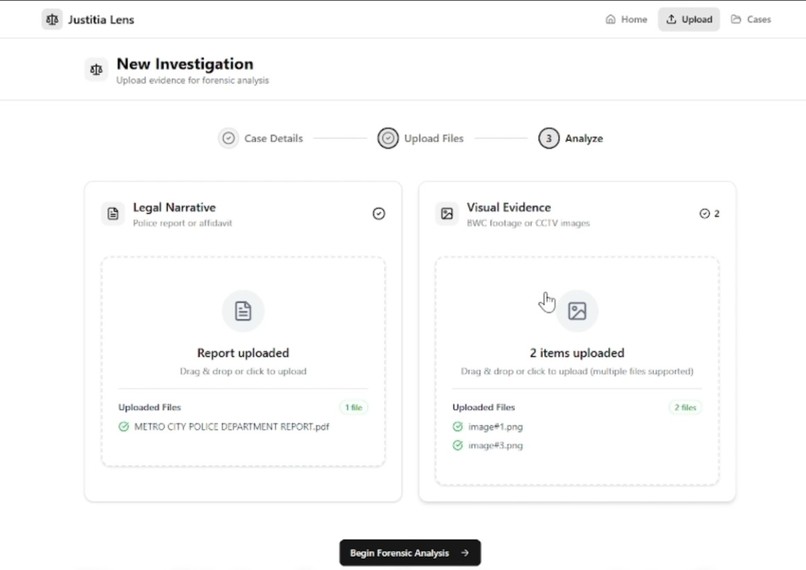
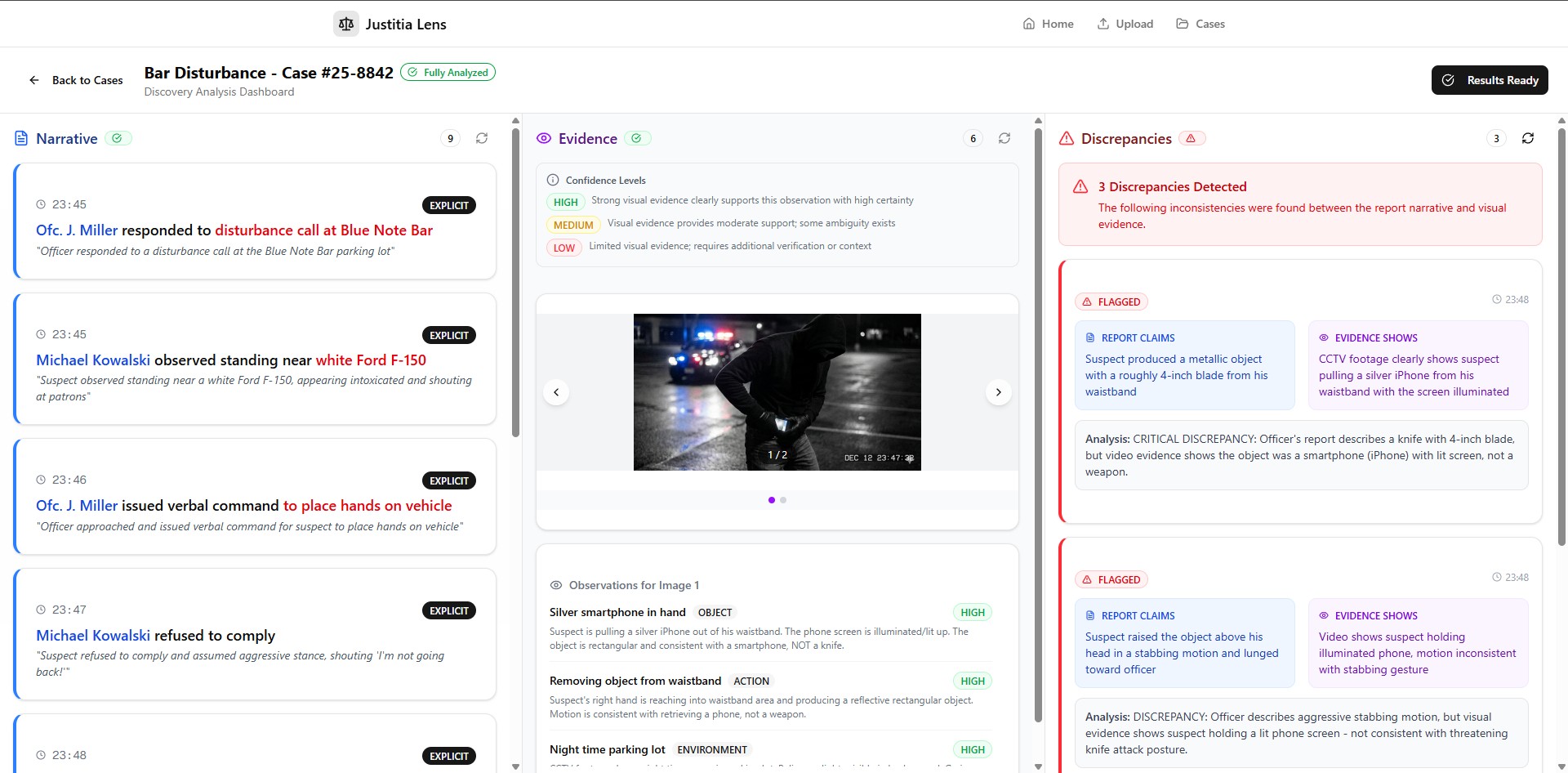
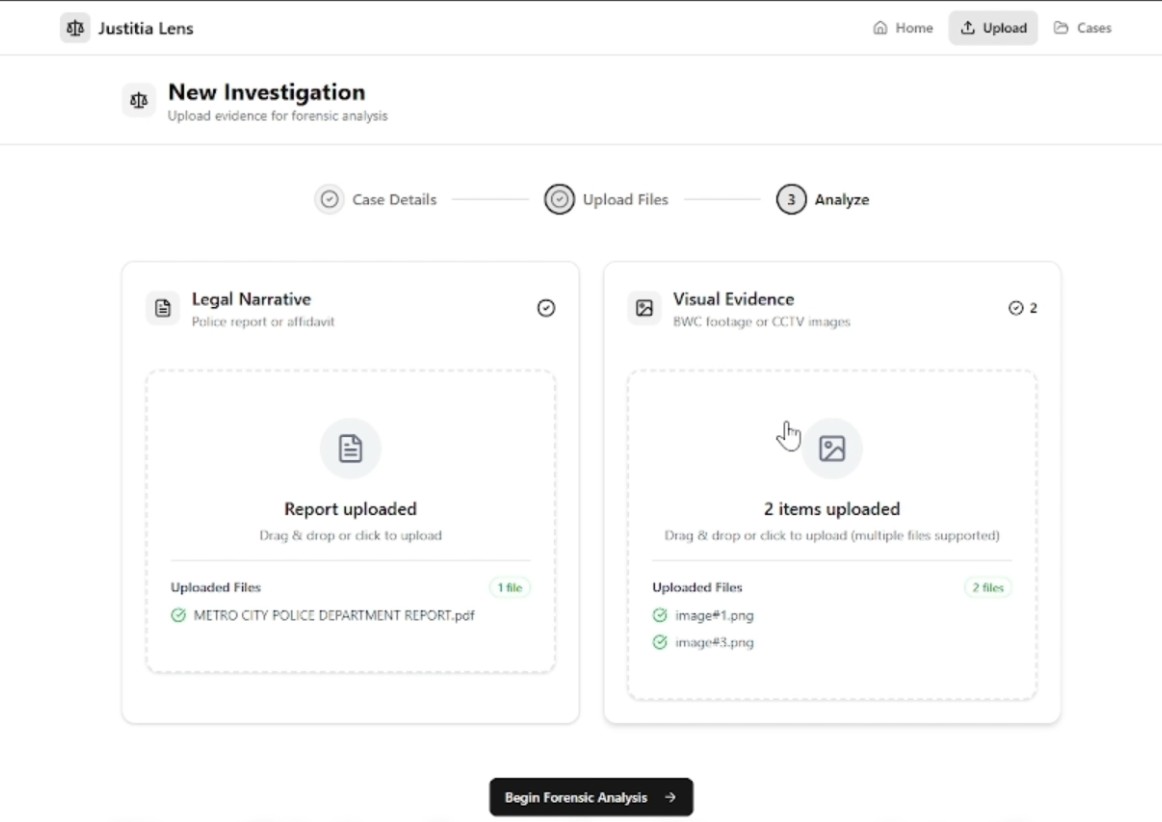
Justitia Lens is an AI Forensic Auditor. It reads police reports (PDFs) and looks at crime scene photos simultaneously. It extracts claims from the text and cross-references them with visual evidence based on the timelines/timestamp and then flags discrepancies between them, hence, saving legal teams hours of manual review.
How we built it
We built a modern web app using Next.js (Frontend) and FastAPI (Backend). The core intelligence uses Google Gemini 3.0 Flash via the AI Studio API. We designed a multi-agent system: a "Narrative Agent" parses text into timelines, a "Vision Agent" indexes visual evidence, and a "Synthesizer Agent" compares the two using Gemini's structured JSON mode to ensure accuracy.
The core intelligence is powered by Google Gemini 3.0 Flash, leveraging its native multimodal capabilities and structured JSON output mode. We architected a multi-agent system where each agent has a specialized forensic role:
- Narrative Agent – Uses Gemini's long-context processing to extract structured chronological timelines from legal PDFs, identifying specific claims with timestamps
- Vision Agent – Leverages Gemini's native vision capabilities to analyse crime scene images independently, indexing objective visual facts without narrative bias
- Synthesizer Agent – Cross-references both outputs using Gemini's JSON mode to programmatically compare claims against visual evidence and flag discrepancies This separation helps reduce confirmation bias by ensuring the Vision Agent analyses visual evidence independently before comparison.
Challenges we ran into
Getting the AI to be "objective" was hard. Early versions would hallucinate or infer intent. We solved this by using strict system prompts and Gemini's JSON mode to force the model to output only factual observations, not opinions. Handling large case files also required careful context management.
Accomplishments that we're proud of
We successfully built a working end-to-end pipeline that will help people in Legal to process things faster than ever. We're especially proud of the "timestamps verification" feature, which can pinpoint exactly when a narrative diverges from the visual evidence.
What we learned
We learned that "prompt engineering" is actually "context engineering." Feeding the model structured data (JSON) instead of raw text significantly improved reliability. We also learned how powerful Gemini's long-context window is for legal documents.
What's next for Justitia Lens
We plan to add Video Analysis. Using Gemini's native video understanding, we want to process bodycam footage directly to correlate frames with report timestamps. We also aim to add a "Citation" feature, where every AI claim links back to the specific sentence or pixel that supports it.
Built With
- alembic
- cloudrun
- css
- docker
- fastapi
- next.js
- postgresql
- python
- react
- render
- sqlalchemy
- supabase
- typescript




Log in or sign up for Devpost to join the conversation.